{kind=link}
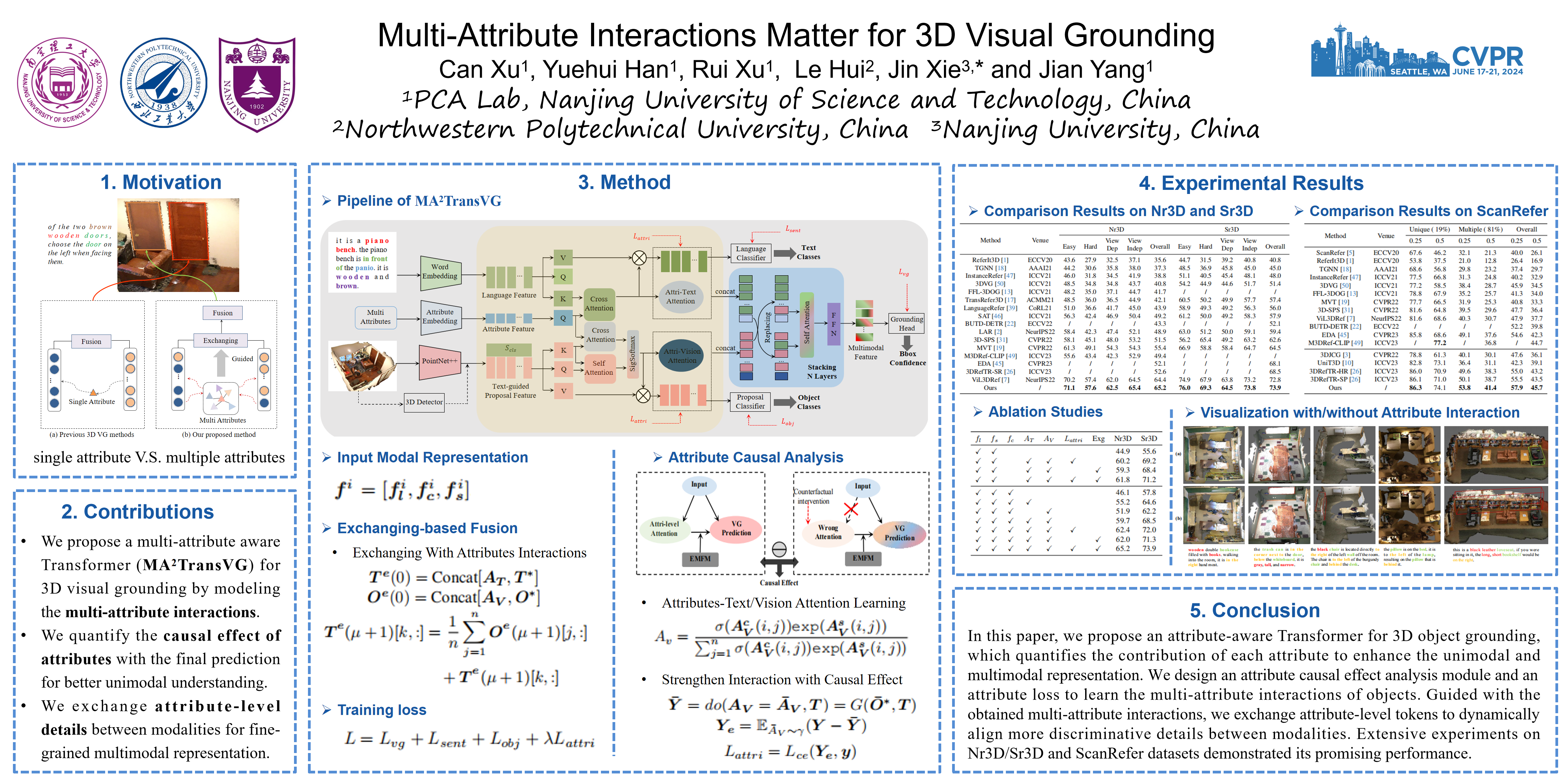
3D visual grounding aims to localize 3D objects described by free-form language sentences. Following the detection-then-matching paradigm, existing methods mainly focus on embedding object attributes in unimodal feature extraction and multimodal feature fusion, to enhance the discriminability of the proposal feature for accurate grounding. However, most of them ignore the explicit interaction of multiple attributes, causing a bias in unimodal representation and misalignment in multimodal fusion. In this paper, we propose a multi-attribute aware Transformer for 3D visual grounding, learning the multi-attribute interactions to refine the intra-modal and inter-modal grounding cues. Specifically, we first develop an attribute causal analysis module to quantify the causal effect of different attributes for the final prediction, which provides powerful supervision to correct the misleading attributes and adaptively capture other discriminative features. Then, we design an exchanging-based multimodal fusion module, which dynamically replaces tokens with low attribute attention between modalities before directly integrating low-dimensional global features. This ensures an attribute-level multimodal information fusion and helps align the language and vision details more efficiently for fine-grained multimodal features. Extensive experiments show that our method can achieve state-of-the-art performance on ScanRefer and SR3D/NR3D datasets.