|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present Monocular Neural Parametric Head Models (MonoNPHM) for dynamic 3D head reconstructions from monocular RGB videos. To this end, we propose a latent appearance space that parameterizes a texture field on top of a neural parametric model. We constrain predicted color values to be correlated with the underlying geometry such that gradients from RGB effectively influence latent geometry codes during inverse rendering. To increase the representational capacity of our expression space, we augment our backward deformation field with hyper-dimensions, thus improving color and geometry representation in topologically challenging expressions. Using MonoNPHM as a learned prior, we approach the task of 3D head reconstruction using signed distance field based volumetric rendering. By numerically inverting our backward deformation field, we incorporated a landmark loss using facial anchor points that are closely tied to our canonical geometry representation. To evaluate the task of dynamic face reconstruction from monocular RGB videos we record 20 challenging Kinect sequences under casual conditions. MonoNPHM outperforms all baselines with a significant margin, and makes an important step towards easily accessible neural parametric face models through RGB tracking. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
We present M&M VTO–a mix and match virtual try-on method that takes as input multiple garment images, text description for garment layout and an image of a person. An example input includes: an image of a shirt, an image of a pair of pants, "rolled sleeves, shirt tucked in", and an image of a person. The output is a visualization of how those garments (in the desired layout) would look like on the given person. Key contributions of our method are: 1) a single stage diffusion based model, with no super resolution cascading, that allows to mix and match multiple garments at $1024\mathord\times\mathord512$ resolution preserving and warping intricate garment details, 2) architecture design (VTO UNet Diffusion Transformer) to disentangle denoising from person specific features, allowing for a highly effective finetuning strategy for identity preservation (6MB model per individual vs 4GB achieved with, e.g., dreambooth finetuning); solving a common identity loss problem in current virtual try-on methods, 3) layout control for multiple garments via text inputs specifically finetuned over PaLI-3 for virtual try-on task. Experimental results indicate that M&M VTO achieves state-of-the-art performance both qualitatively and quantitatively, as well as opens up new opportunities for virtual try-on via language-guided and multi-garment …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractMulti-modal Large Language Models (MLLMs) have demonstrated impressive instruction abilities across various open-ended tasks. However, previous methods have primarily focused on enhancing multi-modal capabilities. In this work, we introduce a versatile multi-modal large language model, mPLUG-Owl2, which effectively leverages modality collaboration to improve performance in both text and multi-modal tasks. mPLUG-Owl2 utilizes a modularized network design, with the language decoder acting as a universal interface for managing different modalities. Specifically, mPLUG-Owl2 incorporates shared functional modules to facilitate modality collaboration and introduces a modality-adaptive module that preserves modality-specific features. Extensive experiments reveal that mPLUG-Owl2 is capable of generalizing both text tasks and multi-modal tasks while achieving state-of-the-art performances with a single generalized model. Notably, mPLUG-Owl2 is the first MLLM model that demonstrates the modality collaboration phenomenon in both pure-text and multi-modal scenarios, setting a pioneering path in the development of future multi-modal foundation models. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractRecent studies have noted an intriguing phenomenon termed Neural Collapse, that is, when the neural networks establish the right correlation between feature spaces and the training targets, their last-layer features, together with the classifier weights, will collapse into a stable and symmetric structure. In this paper, we extend the investigation of Neural Collapse to the biased datasets with imbalanced attributes. We observe that models will easily fall into the pitfall of shortcut learning and form a biased, non-collapsed feature space at the early period of training, which is hard to reverse and limits the generalization capability. To tackle the root cause of biased classification, we follow the recent inspiration of prime training, and propose an avoid-shortcut learning framework without additional training complexity. With well-designed shortcut primes based on Neural Collapse structure, the models are encouraged to skip the pursuit of simple shortcuts and naturally capture the intrinsic correlations. Experimental results demonstrate that our method induces a better convergence property during training, and achieves state-of-the-art generalization performance on both synthetic and real-world biased datasets. |
|
Highlight
|
Poster
[ Arch 4A-E ] 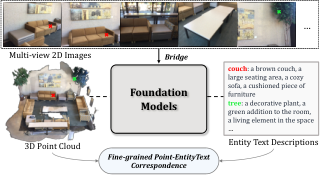
AbstractIn dynamic 3D environments, the ability to recognize a diverse range of objects without the constraints of predefined categories is indispensable for real-world applications. In response to this need, we introduce OV3D, an innovative framework designed for open-vocabulary 3D semantic segmentation. OV3D leverages the broad open-world knowledge embedded in vision and language foundation models to establish a fine-grained correspondence between 3D points and textual entity descriptions. These entity descriptions are enriched with contextual information, enabling a more open and comprehensive understanding. By seamlessly aligning 3D point features with entity text features, OV3D empowers open-vocabulary recognition in the 3D domain, achieving state-of-the-art open-vocabulary semantic segmentation performance across multiple datasets, including ScanNet, Matterport3D, and nuScenes. Code will be available. |
|
Highlight
|
Poster
[ Arch 4A-E ] 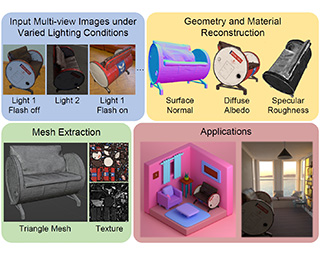
AbstractThis paper introduces a versatile multi-view inverse rendering framework with near- and far-field light sources. Tackling the fundamental challenge of inherent ambiguity in inverse rendering, our framework adopts a lightweight yet inclusive lighting model for different near- and far-field lights, thus is able to make use of input images under varied lighting conditions available during capture.It leverages observations under each lighting to disentangle the intrinsic geometry and material from the external lighting, using both neural radiance field rendering and physically-based surface rendering on the 3D implicit fields.After training, the reconstructed scene is extracted to a textured triangle mesh for seamless integration into industrial rendering software for various applications.Quantitatively and qualitatively tested on synthetic and real-world scenes, our method shows superiority to state-of-the-art multi-view inverse rendering methods in both speed and quality. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractVision-centric 3D environment understanding is both vital and challenging for autonomous driving systems. Recently, object-free methods have attracted considerable attention. Such methods perceive the world by predicting the semantics of discrete voxel grids but fail to construct continuous and accurate obstacle surfaces. To this end, in this paper, we propose SurroundSDF to implicitly predict the signed distance field (SDF) and semantic field for the continuous perception from surround images. Specifically, we introduce a query-based approach and utilize SDF constrained by the Eikonal formulation to accurately describe the surfaces of obstacles. Furthermore, considering the absence of precise SDF ground truth, we propose a novel weakly supervised paradigm for SDF, referred to as the Sandwich Eikonal formulation, which emphasizes applying correct and dense constraints on both sides of the surface, thereby enhancing the perceptual accuracy of the surface. Experiments suggest that our method achieves SOTA for both occupancy prediction and 3D scene reconstruction tasks on the nuScenes dataset. The code will be released when paper is accepted. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractExtracting keypoint locations from input hand frames, known as 3D hand pose estimation, is a critical task in various human-computer interaction applications. Essentially, the 3D hand pose estimation can be regarded as a 3D point subset generative problem conditioned on input frames. Thanks to the recent significant progress on diffusion-based generative models, hand pose estimation can also benefit from the diffusion model to estimate keypoint locations with high quality. However, directly deploying the existing diffusion models to solve hand pose estimation is non-trivial, since they cannot achieve the complex permutation mapping and precise localization. Based on this motivation, this paper proposes HandDiff, a diffusion-based hand pose estimation model that iteratively denoises accurate hand pose conditioned on hand-shaped image-point clouds. In order to recover keypoint permutation and accurate location, we further introduce joint-wise condition and local detail condition. Experimental results show that the proposed model significantly outperforms the existing methods on three hand pose benchmark datasets. Codes and pre-trained models are publicly available at https://anonymous.4open.science/r/HandDiff_-A032. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
People are spending an enormous amount of time on digital devices through graphical user interfaces (GUIs), e.g., computer or smartphone screens. Large language models (LLMs) such as ChatGPT can assist people in tasks like writing emails, but struggle to understand and interact with GUIs, thus limiting their potential to increase automation levels. In this paper, we introduce CogAgent, an 18-billion-parameter visual language model (VLM) specializing in GUI understanding and navigation. By utilizing both low-resolution and high-resolution image encoders, CogAgent supports input at a resolution of $1120\times 1120$, enabling it to recognize tiny page elements and text. As a generalist visual language model, CogAgent achieves the state of the art on five text-rich and four general VQA benchmarks, including VQAv2, OK-VQA, Text-VQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet, and POPE. CogAgent, using only screenshots as input, outperforms LLM-based methods that consume extracted HTML text on both PC and Android GUI navigation tasks---Mind2Web and AITW, advancing the state of the art. The model and codes are available at https://github.com/THUDM/CogVLM.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractGeneralizable face anti-spoofing (FAS) approaches have drawn growing attention due to their robustness for diverse presentation attacks in unseen scenarios. Most previous methods always utilize domain generalization (DG) frameworks via directly aligning diverse source samples into a common feature space.However, these methods neglect the hierarchical relations in FAS samples which may hinder the generalization ability by direct alignment. To address these issues, we propose a novel Hierarchical Prototype-guided Distribution Refinement (HPDR) framework to learn embedding in hyperbolic space, which facilitates the hierarchical relation construction. We also collaborate with prototype learning for hierarchical distribution refinement in hyperbolic space. In detail, we propose the Hierarchical Prototype Learning to simultaneously guide domain alignment and improve the discriminative ability via constraining the multi-level relations between prototypes and instances in hyperbolic space.Moreover, we design a Prototype-oriented Classifier, which further considers relations between the sample and prototypes to improve the robustness of the final decision. Extensive experiments and visualizations demonstrate the effectiveness of our method against previous competitors. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
We present CosmicMan, a text-to-image foundation model specialized for generating high-fidelity human images. Unlike current general-purpose foundation models that are stuck in the dilemma of inferior quality and text-image misalignment for humans, CosmicMan enables generating photo-realistic human images with meticulous appearance, reasonable structure, and precise text-image alignment with detailed dense descriptions.At the heart of CosmicMan's success are the new reflections and perspectives on data and model:$(1)$ We found that data quality and a scalable data production flow are essential for the final results from trained models. Hence, we propose a new data production paradigm \textbf{Annotate Anyone}, which serves as a perpetual data flywheel to produce high-quality data with accurate yet cost-effective annotations over time. Based on this, we constructed a large-scale dataset CosmicMan-HQ 1.0, with $6$ Million high-quality real-world human images in a mean resolution of $1488\times 1255$, and attached with precise text annotations deriving from $115$ Million attributes in diverse granularities.$(2)$ We argue that a text-to-image foundation model specialized for humans must be pragmatic -- easy to integrate into down-streaming tasks while effective in producing high-quality human images. Hence, we propose to model the relationship between dense text descriptions and image pixels in a decomposed manner, and present Decomposed-Attention-Refocusing …
|
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractScene simulation in autonomous driving has gained significant attention because of its huge potential for generating customized data. However, existing editable scene simulation approaches face limitations in terms of user interaction efficiency, multi-camera photo-realistic rendering and external digital assets integration. To address these challenges, this paper introduces ChatSim, the first system that enables editable photo-realistic 3D driving scene simulations via natural language commands with external digital assets. To enable editing with high command flexibility, ChatSim leverages a large language model (LLM) agent collaboration framework. To generate photo-realistic outcomes, ChatSim employs a novel multi-camera neural radiance field method. Furthermore, to unleash the potential of extensive high-quality digital assets, ChatSim employs a novel multi-camera lighting estimation method to achieve scene-consistent assets' rendering. Our experiments on Waymo Open Dataset demonstrate that ChatSim can handle complex language commands and generate corresponding photo-realistic scene videos. |
|
Highlight
|
Poster
[ Arch 4A-E ] 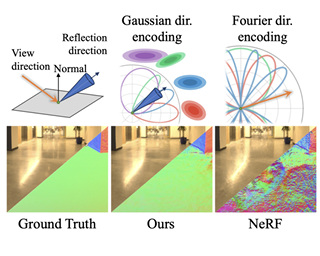
AbstractNeural radiance fields have achieved remarkable performance in modeling the appearance of 3D scenes. However, existing approaches still struggle with the view-dependent appearance of glossy surfaces, especially under complex lighting of indoor environments. Unlike existing methods, which typically assume distant lighting like an environment map, we propose a learnable Gaussian directional encoding to better model the view-dependent effects under near-field lighting conditions. Importantly, our new directional encoding captures the spatially-varying nature of near-field lighting and emulates the behavior of prefiltered environment maps. As a result, it enables the efficient evaluation of preconvolved specular color at any 3D location with varying roughness coefficients. We further introduce a data-driven geometry prior that helps alleviate the shape radiance ambiguity in reflection modeling. We show that our Gaussian directional encoding and geometry prior significantly improve the modeling of challenging specular reflections in neural radiance fields, which helps decompose appearance into more physically meaningful components. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractEvent sensors offer high temporal resolution visual sensing, which makes them ideal for perceiving fast visual phenomena without suffering from motion blur. Certain applications in robotics and vision-based navigation require 3D perception of an object undergoing circular or spinning motion in front of a static camera, such as recovering the angular velocity and shape of the object. The setting is equivalent to observing a static object with an orbiting camera. In this paper, we propose event-based structure-from-orbit (eSfO), where the aim is to simultaneously reconstruct the 3D structure of a fast spinning object observed from a static event camera, and recover the equivalent orbital motion of the camera. Our contributions are threefold: since state-of-the-art event feature trackers cannot handle periodic self-occlusion due to the spinning motion, we develop a novel event feature tracker based on spatio-temporal clustering and data association that can better track the helical trajectories of valid features in the event data. The feature tracks are then fed to our novel factor graph-based structure-from-orbit back-end that calculates the orbital motion parameters (e.g., spin rate, relative rotational axis) that minimize the reprojection error. For evaluation, we produce a new event dataset of objects under spinning motion. Comparisons against ground … |
|
Highlight
|
Poster
[ Arch 4A-E ] 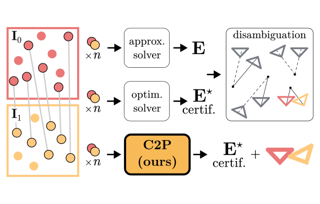
Abstract
Estimating the relative camera pose from $n \geq 5$ correspondences between two calibrated views is a fundamental task in computer vision. This process typically involves two stages: 1) estimating the essential matrix between the views, and 2) disambiguating among the four candidate relative poses that satisfy the epipolar geometry. In this paper, we demonstrate a novel approach that, for the first time, bypasses the second stage. Specifically, we show that it is possible to directly estimate the correct relative camera pose from correspondences without needing a post-processing step to enforce the cheirality constraint on the correspondences.Building on recent advances in certifiable non-minimal optimization, we frame the relative pose estimation as a Quadratically Constrained Quadratic Program (QCQP). By applying the appropriate constraints, we ensure the estimation of a camera pose that corresponds to a valid 3D geometry and that is globally optimal when certified. We validate our method through exhaustive synthetic and real-world experiments, confirming the efficacy, efficiency and accuracy of the proposed approach. Our code can be found in the supp. material and will be released.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 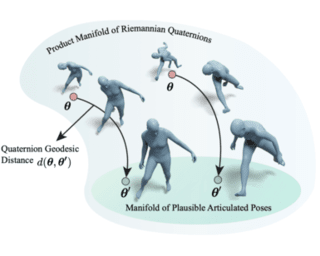
AbstractFaithfully modeling the space of articulations is a crucial task that allows recovery and generation of realistic poses, and remains a notorious challenge. To this end, we introduce Neural Riemannian Distance Fields (NRDFs), data-driven priors modeling the space of plausible articulations, represented as the zero-level-set of a neural field in a high-dimensional product-quaternion space. To train NRDFs only on positive examples, we introduce a new \textbf{sampling algorithm}, ensuring that the geodesic distances follow a desired distribution, yielding a principled distance field learning paradigm. We then devise a \textbf{projection algorithm} to map any random pose onto the level-set by an \textbf{adaptive-step Riemannian optimizer}, adhering to the product manifold of joint rotations at all times. NRDFs can compute the Riemannian gradient via backpropagation and by mathematical analogy, are related to Riemannian flow matching, a recent generative model. We conduct a comprehensive evaluation of NRDF against other pose priors in various downstream tasks, \emph{i.e.}, pose generation, image-based pose estimation, and solving inverse kinematics, highlighting NRDF's superior performance. Besides humans, NRDF's versatility extends to hand and animal poses, as it can effectively represent any articulation. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractThis work delves into the task of pose-free novel view synthesis from stereo pairs, a challenging and pioneering task in 3D vision. Our innovative framework, unlike any before, seamlessly integrates 2D correspondence matching, camera pose estimation, and NeRF rendering, fostering a synergistic enhancement of these tasks. We achieve this through designing an architecture that utilizes a shared representation, which serves as a foundation for enhanced 3D geometry understanding. Capitalizing on the inherent interplay between the tasks, our unified framework is trained end-to-end with the proposed training strategy to improve overall model accuracy. Through extensive evaluations across diverse indoor and outdoor scenes from two real-world datasets, we demonstrate that our approach achieves substantial improvement over previous methodologies, especially in scenarios characterized by extreme viewpoint changes and the absence of accurate camera poses. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractCreating high-quality 3D models of clothed humans from single images for real-world applications is crucial. Despite recent advancements, accurately reconstructing humans in complex poses or with loose clothing from in-the-wild images, along with predicting textures for unseen areas, remains a significant challenge. A key limitation of previous methods is their insufficient prior guidance in transitioning from 2D to 3D and in texture prediction. In response, we introduce \textbf{SIFU} (\textbf{S}ide-view Conditioned \textbf{I}mplicit \textbf{F}unction for Real-world \textbf{U}sable Clothed Human Reconstruction), a novel approach combining a Side-view Decoupling Transformer with a 3D Consistent Texture Refinement pipeline. SIFU employs a cross-attention mechanism within the transformer, using SMPL-X normals as queries to effectively decouple side-view features in the process of mapping 2D features to 3D. This method not only improves the precision of the 3D models but also their robustness, especially when SMPL-X estimates are not perfect. Our texture refinement process leverages text-to-image diffusion-based prior to generate realistic and consistent textures for invisible views. Through extensive experiments, SIFU surpasses SOTA methods in both geometry and texture reconstruction, showcasing enhanced robustness in complex scenarios and achieving an unprecedented Chamfer and P2S measurement. Our approach extends to practical applications such as 3D printing and scene building, demonstrating … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
We present $\mathcal{X}^3$ (pronounced XCube), a novel generative model for high-resolution sparse 3D voxel grids with arbitrary attributes. Our model can generate millions of voxels with a finest effective resolution of up to $1024^3$ in a feed-forward fashion without time-consuming test-time optimization. To achieve this, we employ a hierarchical voxel latent diffusion model which generates progressively higher resolution grids in a coarse-to-fine manner using a custom framework built on the highly efficient VDB data structure. Apart from generating high-resolution objects, we demonstrate the effectiveness of XCube on large outdoor scenes at scales of 100m$\times$100m with a voxel size as small as 10cm. We observe clear qualitative and quantitative improvements over past approaches. In addition to unconditional generation, we show that our model can be used to solve a variety of tasks such as user-guided editing, scene completion from a single scan, and text-to-3D.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 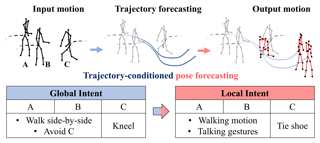
AbstractHuman pose forecasting garners attention for its diverse applications.However, challenges in modeling the multi-modal nature of human motion and intricate interactions among agents persist, particularly with longer timescales and more agents.In this paper, we propose an interaction-aware trajectory-conditioned long-term multi-agent human pose forecasting model, utilizing a coarse-to-fine prediction approach: multi-modal global trajectories are initially forecasted, followed by respective local pose forecasts conditioned on each mode.In doing so, our Trajectory2Pose model introduces a graph-based agent-wise interaction module for a reciprocal forecast of local motion-conditioned global trajectory and trajectory-conditioned local pose.Our model effectively handles the multi-modality of human motion and the complexity of long-term multi-agent interactions, improving performance in complex environments.Furthermore, we address the lack of long-term (6s+) multi-agent (5+) datasets by constructing a new dataset from real-world images and 2D annotations, enabling a comprehensive evaluation of our proposed model.State-of-the-art prediction performance on both complex and simpler datasets confirms the generalized effectiveness of our method. |
|
Highlight
|
Poster
[ Arch 4A-E ] 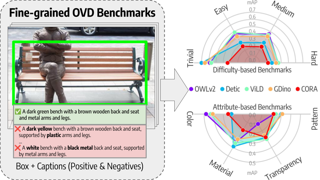
AbstractRecent advancements in large vision-language models enabled visual object detection in open-vocabulary scenarios, where object classes are defined in free-text formats during inference.In this paper, we aim to probe the state-of-the-art methods for open-vocabulary object detection to determine to what extent they understand fine-grained properties of objects and their parts.To this end, we introduce an evaluation protocol based on dynamic vocabulary generation to test whether models detect, discern, and assign the correct fine-grained description to objects in the presence of hard-negative classes.We contribute with a benchmark suite of increasing difficulty and probing different properties like color, pattern, and material.We further enhance our investigation by evaluating several state-of-the-art open-vocabulary object detectors using the proposed protocol and find that most existing solutions, which shine in standard open-vocabulary benchmarks, struggle to accurately capture and distinguish finer object details.We conclude the paper by highlighting the limitations of current methodologies and exploring promising research directions to overcome the discovered drawbacks. Data and code are available at https://lorebianchi98.github.io/FG-OVD . |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractExtensive advancements have been made in person ReID through the mining of semantic information. Nevertheless, existing methods that utilize semantic-parts from a single image modality do not explicitly achieve this goal. Whiteness the impressive capabilities in multimodal understanding of Vision Language Foundation Model CLIP, a recent two-stage CLIP-based method employs automated prompt engineering to obtain specific textual labels for classifying pedestrians. However, we note that the predefined soft prompts may be inadequate in expressing the entire visual context and struggle to generalize to unseen classes. This paper presents an end-to-end Prompt-driven Semantic Guidance (PromptSG) framework that harnesses the rich semantics inherent in CLIP. Specifically, we guide the model to attend to regions that are semantically faithful to the prompt. To provide the personalized language descriptions for specific individuals, we propose learning pseudo tokens that represent specific visual context. This design not only facilitates learning fine-grained attribute information but also can inherently leverage language prompts during inference. Without requiring additional labeling efforts, our PromptSG achieves state-of-the-art by over 10\% on MSMT17 and nearly 5\% on the Market-1501 benchmark. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe establish rigorous benchmarks for visual perception robustness. Synthetic images such as ImageNet-C, ImageNet-9, and Stylized ImageNet provide specific type of evaluation over synthetic corruptions, backgrounds, and textures, yet those robustness benchmarks are restricted in specified variations and have low synthetic quality. In this work, we introduce generative model as a data source for synthesizing hard images that benchmark deep models' robustness. Leveraging diffusion models, we are able to generate images with more diversified backgrounds, textures, and materials than any prior work, where we term this benchmark as ImageNet-D. Experimental results show that ImageNet-D results in a significant accuracy drop to a range of vision models, from the standard ResNet visual classifier to the latest foundation models like CLIP and MiniGPT-4, significantly reducing their accuracy by up to 60\%. Our work suggests that diffusion models can be an effective source to test vision models. The code and dataset are available at https://github.com/chenshuang-zhang/imagenet_d. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe introduce a co-designed approach for human portrait relighting that combines a physics-guided architecture with a pre-training framework. Drawing on the Cook-Torrance reflectance model, we have meticulously configured the architecture design to precisely simulate light-surface interactions. Furthermore, to overcome the limitation of scarce high-quality lightstage data, we have developed a self-supervised pre-training strategy. This novel combination of accurate physical modeling and expanded training dataset establishes a new benchmark in relighting realism. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractAs with many machine learning problems, the progress of image generation methods hinges on good evaluation metrics. One of the most popular is the Frechet Inception Distance (FID). FID estimates the distance between a distribution of Inception-v3 features of real images, and those of images generated by the algorithm. We highlight important drawbacks of FID: Inception's poor representation of the rich and varied content generated by modern text-to-image models, incorrect normality assumptions, and poor sample complexity. We call for a reevaluation of FID's use as the primary quality metric for generated images. We empirically demonstrate that FID contradicts human raters, it does not reflect gradual improvement of iterative text-to-image models, it does not capture distortion levels, and that it produces inconsistent results when varying the sample size. We also propose an alternative new metric, CMMD, based on richer CLIP embeddings and the maximum mean discrepancy distance with the Gaussian RBF kernel. It is an unbiased estimator that does not make any assumptions on the probability distribution of the embeddings and is sample efficient. Through extensive experiments and analysis, we demonstrate that FID-based evaluations of text-to-image models may be unreliable, and that CMMD offers a more robust and reliable assessment of … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe introduce the video detours problem for navigating instructional videos. Given a source video and a natural language query asking to alter the how-to video's current path of execution in a certain way, the goal is to find a related "detour video" that satisfies the requested alteration. To address this challenge, we propose VidDetours, a novel video-language approach that learns to retrieve the targeted temporal segments from a large repository of how-to's using video-and-text conditioned queries. Furthermore, we devise a language-based pipeline that exploits how-to video narration text to create weakly supervised training data. We demonstrate our idea applied to the domain of how-to cooking videos, where a user can detour from their current recipe to find steps with alternate ingredients, tools, and techniques. Validating on a ground truth annotated dataset of 16K samples, we show our model's significant improvements over best available methods for video retrieval and question answering, with recall rates exceeding the state of the art by 35%. |
|
Highlight
|
Poster
[ Arch 4A-E ] 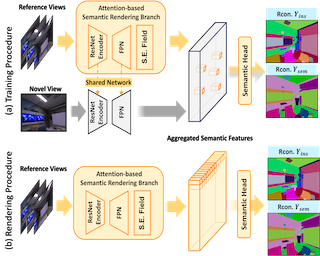
AbstractApplying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular. Most existing methods treat semantic prediction as an additional rendering task, \textit{i.e.}, the "label rendering" task, to build semantic NeRFs.However, by rendering semantic/instance labels per pixel without considering the contextual information of the rendered image, these methods usually suffer from unclear boundary segmentation and abnormal segmentation of pixels within an object. To solve this problem, we propose Generalized Perception NeRF (GP-NeRF), a novel pipeline that makes the widely used segmentation model and NeRF work compatibly under a unified framework, for facilitating context-aware 3D scene perception. To accomplish this goal, we introduce Transformers to aggregate radiance as well as semantic embedding fields jointly for novel views and facilitate the joint volumetric rendering upon both fields.In addition, we propose two self-distillation mechanisms, i.e., the Semantic Distill Loss and the Depth-Guided Semantic Distill Loss, to enhance the discrimination and quality of the semantic field and maintenance of geometric consistency.In evaluation, we conduct experimental comparisons under two perception tasks (\textit{i.e.} semantic and instance segmentation) using both synthetic and real-world datasets. Notably, our method outperforms SOTA approaches by 6.94\%, 11.76\%, and 8.47\% on generalized semantic segmentation, finetuning semantic segmentation, and … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractAccurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling.However, the remarkable accuracy of recent MMDE methods is confined to their training domains.These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability.We propose a new model, UniDepth, capable of reconstructing metric 3D scenes from solely single images across domains.Departing from the existing MMDE methods, UniDepth directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution.In particular, UniDepth implements a self-promptable camera module predicting dense camera representation to condition depth features.Our model exploits a pseudo-spherical output representation, which disentangles camera and depth representations.In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features.Thorough evaluations on ten datasets in a zero-shot regime consistently demonstrate the superior performance of UniDepth, even when compared with methods directly trained on the testing domains. Code and models are available at: github.com/lpiccinelli-eth/unidepth. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractRecent advancements in diffusion-based models have demonstrated significant success in generating images from text. However, video editing models have not yet reached the same level of visual quality and user control. To address this, we introduce RAVE, a zero-shot video editing method that leverages pre-trained text-to-image diffusion models without additional training. RAVE takes an input video and a text prompt to produce high-quality videos while preserving the original motion and semantic structure. It employs a novel noise shuffling strategy, leveraging spatio-temporal interactions between frames, to produce temporally consistent videos faster than existing methods. It is also efficient in terms of memory requirements, allowing it to handle longer videos. RAVE is capable of a wide range of edits, from local attribute modifications to shape transformations. In order to demonstrate the versatility of RAVE, we create a comprehensive video evaluation dataset ranging from object-focused scenes to complex human activities like dancing and typing, and dynamic scenes featuring swimming fish and boats. Our qualitative and quantitative experiments highlight the effectiveness of RAVE in diverse video editing scenarios compared to existing methods. Our code, dataset and videos can be found in our supplementary materials. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractSince humans interact with diverse objects every day, the holistic 3D capture of these interactions is important to understand and model human behaviour. However, most existing methods for hand-object reconstruction from RGB either assume pre-scanned object templates or heavily rely on limited 3D hand-object data, restricting their ability to scale and generalize to more unconstrained interaction settings. To address this, we introduce HOLD -- the first category-agnostic method that reconstructs an articulated hand and an object jointly from a monocular interaction video. We develop a compositional articulated implicit model that can reconstruct disentangled 3D hands and objects from 2D images. We also further incorporate hand-object constraints to improve hand-object poses and consequently the reconstruction quality. Our method does not rely on any 3D hand-object annotations while significantly outperforming fully-supervised baselines in both in-the-lab and challenging in-the-wild settings. Moreover, we qualitatively show its robustness in reconstructing from in-the-wild videos. See https://github.com/zc-alexfan/hold for code, data, models, and updates. |
|
Highlight
|
Poster
[ Arch 4A-E ] 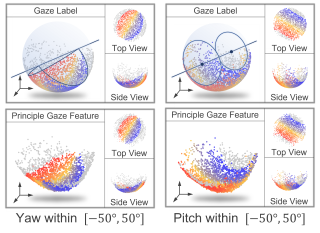
AbstractDeep-learning-based gaze estimation approaches often suffer from notable performance degradation in unseen target domains. One of the primary reasons is that the Fully Connected layer is highly prone to overfitting when mapping the high-dimensional image feature to 3D gaze. In this paper, we propose Analytical Gaze Generalization framework (AGG) to improve the generalization ability of gaze estimation models without touching target domain data. The AGG consists of two modules, the Geodesic Projection Module (GPM) and the Sphere-Oriented Training (SOT). GPM is a generalizable replacement of FC layer, which projects high-dimensional image features to 3D space analytically to extract the principle components of gaze. Then, we propose Sphere-Oriented Training (SOT) to incorporate the GPM into the training process and further improve cross-domain performances. Experimental results demonstrate that the AGG effectively alleviate the overfitting problem and consistently improves the cross-domain gaze estimation accuracy in 12 cross-domain settings, without requiring any target domain data. The insight from the Analytical Gaze Generalization framework has the potential to benefit other regression tasks with physical meanings. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe present a method that uses a text-to-image model to generate consistent content across multiple image scales, enabling extreme semantic zooms into a scene, e.g., ranging from a wide-angle landscape view of a forest to a macro shot of an insect sitting on one of the tree branches. This representation allows us to render continuously zooming videos, or explore different scales of the scene interactively. We achieve this through a joint multi-scale diffusion sampling approach that encourages consistency across different scales while preserving the integrity of each individual sampling process. Since each generated scale is guided by a different text prompt, our method enables deeper levels of zoom than traditional super-resolution methods that may struggle to create new contextual structure at vastly different scales. We compare our method qualitatively with alternative techniques in image super-resolution and outpainting, and show that our method is most effective at generating consistent multi-scale content. |
|
Highlight
|
Poster
[ Arch 4A-E ] 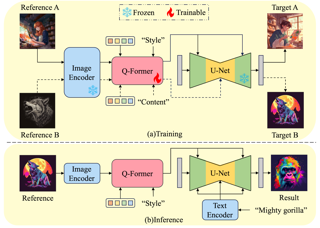
Abstract
The diffusion-based text-to-image model harbors immense potential in transferring reference style. However, current encoder-based approaches significantly impair the text controllability of text-to-image models while transferring styles. In this paper, we introduce $\textit{DEADiff}$ to address this issue using the following two strategies: 1) a mechanism to decouple the style and semantics of reference images. The decoupled feature representations are first extracted by Q-Formers which are instructed by different text descriptions. Then they are injected into mutually exclusive subsets of cross-attention layers for better disentanglement. 2) A non-reconstructive learning method. The Q-Formers are trained using paired images rather than the identical target, in which the reference image and the ground-truth image are with the same style or semantics. We show that DEADiff attains the best visual stylization results and optimal balance between the text controllability inherent in the text-to-image model and style similarity to the reference image, as demonstrated both quantitatively and qualitatively.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 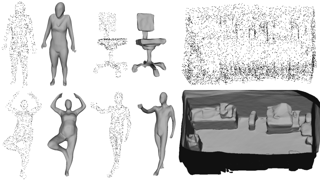
AbstractImplicit Neural Representations have gained prominence as a powerful framework for capturing complex data modalities, encompassing a wide range from 3D shapes to images and audio. Within the realm of 3D shape representation, Neural Signed Distance Functions (SDF) have demonstrated remarkable potential in faithfully encoding intricate shape geometry. However, learning SDFs from 3D point clouds in the absence of ground truth supervision remains a very challenging task. In this paper, we propose a method to infer occupancy fields instead of SDFs as they are easier to learn from sparse inputs. We leverage a margin-based uncertainty measure to differentiably sampling from the decision boundary of the occupancy function and supervise the sampled boundary points using the input point cloud. We further stabilise the optimization process at the early stages of the training by biasing the occupancy function towards minimal entropy fields while maximizing its entropy at the input point cloud. Through extensive experiments and evaluations, we illustrate the efficacy of our proposed method, highlighting its capacity to improve implicit shape inference with respect to baselines and the state-of-the-art using synthetic and real data. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present FoundationPose, a unified foundation model for 6D object pose estimation and tracking, supporting both model-based and model-free setups. Our approach can be instantly applied at test-time to a novel object without fine-tuning, as long as its CAD model is given, or a small number of reference images are captured. We bridge the gap between these two setups with a neural implicit representation that allows for effective novel view synthesis, keeping the downstream pose estimation modules invariant under the same unified framework. Strong generalizability is achieved via large-scale synthetic training, aided by a large language model (LLM), a novel transformer-based architecture, and contrastive learning formulation. Extensive evaluation on multiple public datasets involving challenging scenarios and objects indicate our unified approach outperforms existing methods specialized for each task by a large margin. In addition, it even achieves comparable results to instance-level methods despite the reduced assumptions. Project page: https://foundationpose.github.io/foundationpose/ |
|
Highlight
|
Poster
[ Arch 4A-E ] 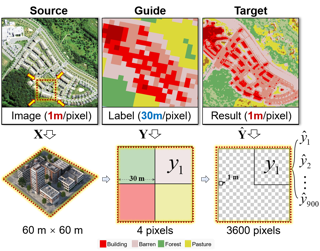
AbstractLarge-scale high-resolution (HR) land-cover mapping is a vital task to survey the Earth's surface and resolve many challenges facing humanity. However, it is still a non-trivial task hindered by complex ground details, various landforms, and the scarcity of accurate training labels over a wide-span geographic area. In this paper, we propose an efficient, weakly supervised framework (Paraformer) to guide large-scale HR land-cover mapping with easy-access historical land-cover data of low resolution (LR). Specifically, existing land-cover mapping approaches reveal the dominance of CNNs in preserving local ground details but still suffer from insufficient global modeling in various landforms. Therefore, we design a parallel CNN-Transformer feature extractor in Paraformer, consisting of a downsampling-free CNN branch and a Transformer branch, to jointly capture local and global contextual information. Besides, facing the spatial mismatch of training data, a pseudo-label-assisted training (PLAT) module is adopted to reasonably refine LR labels for weakly supervised semantic segmentation of HR images.Experiments on two large-scale datasets demonstrate the superiority of Paraformer over other state-of-the-art methods for automatically updating HR land-cover maps from LR historical labels. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractThe inherent generative power of denoising diffusion models makes them well-suited for image restoration tasks where the objective is to find the optimal high-quality image within the generative space that closely resembles the input image.We propose a method to adapt a pretrained diffusion model for image restoration by simply adding noise to the input image to be restored and then denoise. Our method is based on the observation that the space of a generative model needs to be constrained. We impose this constraint by finetuning the generative model with a set of anchor images that capture the characteristics of the input image. With the constrained space, we can then leverage the sampling strategy used for generation to do image restoration. We evaluate against previous methods and show superior performances on multiple real-world restoration datasets in preserving identity and image quality. We also demonstrate an important and practical application on personalized restoration, where we use a personal album as the anchor images to constrain the generative space. This approach allows us to produce results that accurately preserve high-frequency details, which previous works are unable to do. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe present SimXR, a method for controlling a simulated avatar from information (headset pose and cameras) obtained from AR / VR headsets. Due to the challenging viewpoint of head-mounted cameras, the human body is often clipped out of view, making traditional image-based egocentric pose estimation challenging. On the other hand, headset poses provide valuable information about overall body motion, but lack fine-grained details about the hands and feet. To synergize headset poses with cameras, we control a humanoid to track headset movement while analyzing input images to decide body movement. When body parts are seen, the movements of hands and feet will be guided by the images; when unseen, the laws of physics guide the controller to generate plausible motion. We design an end-to-end method that does not rely on any intermediate representations and learns to directly map from images and headset poses to humanoid control signals. To train our method, we also propose a large-scale synthetic dataset created using camera configurations compatible with a commercially available VR headset (Quest 2) and show promising results on real-world captures. To demonstrate the applicability of our framework, we also test it on an AR headset with a forward-facing camera. |
|
Highlight
|
Poster
[ Arch 4A-E ] 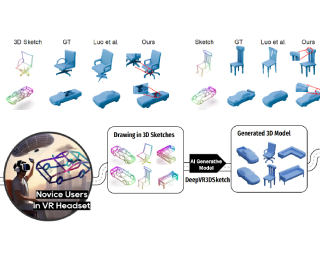
AbstractWith the emergence of AR/VR, 3D models are in tremendous demand. However, conventional 3D modeling with Computer-Aided Design software requires much expertise and is difficult for novice users. We find that AR/VR devices, in addition to serving as effective display mediums, can offer a promising potential as an intuitive 3D model creation tool, especially with the assistance of AI generative models. Here, we propose Deep3DVRSketch, the first 3D model generation network that inputs 3D VR sketches from novice users and generates highly consistent 3D models in multiple categories within seconds, irrespective of the users’ drawing abilities. We also contribute KO3D+, the largest 3D sketch-shape dataset. Our method pre-trains a conditional diffusion model on quality 3D data, then finetunes an encoder to map 3D sketches onto the generator’s manifold using an adaptive curriculum strategy for limited ground truths. In our experiment, our approach achieves state-of-the-art performance in both model quality and fidelity with real-world input from novice users, and users can even draw and obtain very detailed geometric structures. In our user study, users were able to complete the 3D modeling tasks over 10 times faster using our approach compared to conventional CAD software tools. We believe that our Deep3DVRSketch and … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present a method to generate full-body selfies from photographs originally taken at arms length. Because self-captured photos are typically taken close up, they have limited field of view and exaggerated perspective that distorts facial shapes. We instead seek to generate the photo some one else would take of you from a few feet away. Our approach takes as input four selfies of your face and body, a background image, and generates a full-body selfie in a desired target pose. We introduce a novel diffusion-based approach to combine all of this information into high-quality, well-composed photos of you with the desired pose and background. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe propose Strongly Supervised pre-training with ScreenShots (S4) - a novel pre-training paradigm for Vision-Language Models using data from large-scale web screenshot rendering. Using web screenshot unlock a treasure trove of visual and textual cues that are simply not present in using image-text pairs. In S4, we leverage the inherent tree-structure hierarchy of HTML elements and the spatial localization to carefully design 10 pre-training tasks with large scale annotated data. These tasks resembles downstream tasks across different domains and the annotations are cheap to obtain. We demonstrate that, comparing to current screenshot pre-training objectives, our innovative pre-training method significantly enhances performance of image-to-text model in nine varied and popular downstream tasks - up to 76.1% improvements on Table Detection, and at least 1% on Widget Captioning. |
|
Highlight
|
Poster
[ Arch 4A-E ] 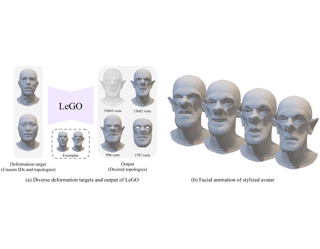
AbstractRecent advances in 3D face stylization have made significant strides in few to zero-shot settings. However, the degree of stylization achieved by existing methods is often not sufficient for practical applications because they are mostly based on statistical 3D Morphable Models (3DMM) with limited variations. To this end, we propose a method that can produce a highly stylized 3D face model with desired topology. Our methods train a surface deformation network with 3DMM and translate its domain to the target style using a paired exemplar.The network achieves stylization of the 3D face mesh by mimicking the style of the target using a differentiable renderer and directional CLIP losses. Additionally, during the inference process, we utilize a Mesh Agnostic Encoder (MAGE) that takes deformation target, a mesh of diverse topologies as input to the stylization process and encodes its shape into our latent space.The resulting stylized face model can be animated by commonly used 3DMM blend shapes.A set of quantitative and qualitative evaluations demonstrate that our method can produce highly stylized face meshes according to a given style and output them in a desired topology. We also demonstrate example applications of our method including image-based stylized avatar generation, linear interpolation of … |
|
Highlight
|
Poster
[ Arch 4A-E ] 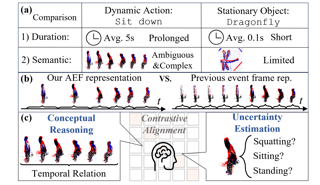
AbstractEvent cameras have recently been shown beneficial for practical vision tasks, such as action recognition, thanks to their high temporal resolution, power efficiency, and reduced privacy concerns. However, current research is hindered by 1) the difficulty in processing events because of their prolonged duration and dynamic actions with complex and ambiguous semantics; and 2) the redundant action depiction of the event frame representation with fixed stacks. We find language naturally conveys abundant semantic information, rendering it stunningly superior in reducing semantic uncertainty. In light of this, we propose ExACT, a novel approach that, for the first time, tackles event-based action recognition from a cross-modal conceptualizing perspective. Our ExACT brings two technical contributions. Firstly, we propose an adaptive fine-grained event (AFE) representation to adaptively filter out the repeated events for the stationary objects while preserving dynamic ones. This subtly enhances the performance of ExACT without extra computational cost. Then, we propose a conceptual reasoning-based uncertainty estimation module, which simulates the recognition process to enrich the semantic representation. In particular, conceptual reasoning builds the temporal relation based on the action semantics, and uncertainty estimation tackles the semantic uncertainty of actions based on the distributional representation. Experiments show that our ExACT achieves superior … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractIn human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individual while exhibit diverse expressions. This paper introduces our efforts towards the personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model which can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping and face reenactment methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] 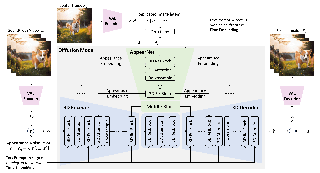
AbstractWe present MicroCinema, a straightforward yet effective framework for high-quality and coherent text-to-video generation. Unlike existing approaches that align text prompts with video directly, MicroCinema introduces a Divide-and-Conquer strategy which divides the text-to-video into a two-stage process: text-to-image generation and image\&text-to-video generation. This strategy offers two significant advantages. a) It allows us to take full advantage of the recent advances in text-to-image models, such as Stable Diffusion, Midjourney, and DALLE, to generate photorealistic and highly detailed images. b) Leveraging the generated image, the model can allocate less focus to fine-grained appearance details, prioritizing the efficient learning of motion dynamics. To implement this strategy effectively, we introduce two core designs. First, we propose the Appearance Injection Network, enhancing the preservation of the appearance of the given image. Second, we introduce the Appearance Noise Prior, a novel mechanism aimed at maintaining the capabilities of pre-trained 2D diffusion models. These design elements empower MicroCinema to generate high-quality videos with precise motion, guided by the provided text prompts. Extensive experiments demonstrate the superiority of the proposed framework. Concretely, MicroCinema achieves SOTA zero-shot FVD of 342.86 on UCF-101 and 377.40 on MSR-VTT. |
|
Highlight
|
Poster
[ Arch 4A-E ] 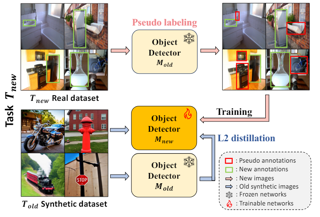
AbstractIn the field of class incremental learning (CIL), generative replay has become increasingly prominent as a method to mitigate the catastrophic forgetting, alongside the continuous improvements in generative models. However, its application in class incremental object detection (CIOD) has been significantly limited, primarily due to the complexities of scenes involving multiple labels. In this paper, we propose a novel approach called stable diffusion deep generative replay (SDDGR) for CIOD. Our method utilizes a diffusion-based generative model with pre-trained text-to-image diffusion networks to generate realistic and diverse synthetic images. SDDGR incorporates an iterative refinement strategy to produce high-quality images encompassing old classes. Additionally, we adopt an L2 knowledge distillation technique to improve the retention of prior knowledge in synthetic images. Furthermore, our approach includes pseudo-labeling for old objects within new task images, preventing misclassification as background elements. Extensive experiments on the COCO 2017 dataset demonstrate that SDDGR significantly outperforms existing algorithms, achieving a new state-of-the-art in various CIOD scenarios. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractGaussian splatting has emerged as a powerful 3D representation that harnesses the advantages of both explicit (mesh) and implicit (NeRF) 3D representations. In this paper, we seek to leverage Gaussian splatting to generate realistic animatable avatars from textual descriptions, addressing the limitations (e.g., efficiency and flexibility) imposed by mesh or NeRF-based representations. However, a naive application of Gaussian splatting cannot generate high-quality animatable avatars and suffers from learning instability; it also cannot capture fine avatar geometries and often leads to degenerate body parts. To tackle these problems, we first propose a primitive-based 3D Gaussian representation where Gaussians are defined inside pose-driven primitives to facilitate animations. Second, to stabilize and amortize the learning of millions of Gaussians, we propose to use implicit neural fields to predict the Gaussian attributes (e.g., colors). Finally, to capture fine avatar geometries and extract detailed meshes, we propose a novel SDF-based implicit mesh learning approach for 3D Gaussians that regularizes the underlying geometries and extracts highly detailed textured meshes. Our proposed method, GAvatar, enables the large-scale generation of diverse animatable avatars using only text prompts. GAvatar significantly surpasses existing methods in terms of both appearance and geometry quality, and achieves extremely fast rendering (100 fps) at … |
|
Highlight
|
Poster
[ Arch 4A-E ] 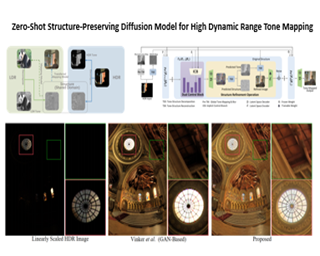
AbstractTone mapping techniques, aiming to convert high dynamic range (HDR) images to high-quality low dynamic range (LDR) images for display, play a more crucial role in real-world vision systems with the increasing application of HDR images. However, obtaining paired HDR and high-quality LDR images is difficult, posing a challenge to deep learning based tone mapping methods. To overcome this challenge, we propose a novel zero-shot tone mapping framework that utilizes shared structure knowledge, allowing us to transfer a pre-trained mapping model from the LDR domain to HDR fields without paired training data. Our approach involves decomposing both the LDR and HDR images into two components: structural information and tonal information. To preserve the original image's structure, we modify the reverse sampling process of a diffusion model and explicitly incorporate the structure information into the intermediate results. Additionally, for improved image details, we introduce a dual-control network architecture that enables different types of conditional inputs to control different scales of the output. Experimental results demonstrate the effectiveness of our approach, surpassing previous state-of-the-art methods both qualitatively and quantitatively. Moreover, our model exhibits versatility and can be applied to other low-level vision tasks without retraining. The code is available at https://github.com/ZSDM-HDR/Zero-Shot-Diffusion-HDR. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractRecent methods such as Score Distillation Sampling (SDS) and Variational Score Distillation (VSD) using 2D diffusion models for text-to-3D generation have demonstrated impressive generation quality. However, the long generation time of such algorithms significantly degrades the user experience. To tackle this problem, we propose DreamPropeller, a drop-in acceleration algorithm that can be wrapped around any existing text-to-3D generation pipeline based on score distillation. Our framework generalizes Picard iterations, a classical algorithm for parallel sampling an ODE path, and can account for non-ODE paths such as momentum-based gradient updates and changes in dimensions during the optimization process as in many cases of 3D generation. We show that our algorithm trades parallel compute for wallclock time and empirically achieves up to 4.7x speedup with a negligible drop in generation quality for all tested frameworks. |
|
Highlight
|
Poster
[ Arch 4A-E ] 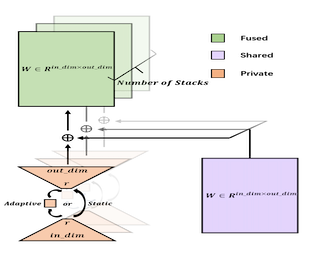
AbstractDeep learning models, particularly those based on transformers, often employ numerous stacked structures, which possess identical architectures and perform similar functions. While effective, this stacking paradigm leads to a substantial increase in the number of parameters, posing challenges for practical applications. In today's landscape of increasingly large models, stacking depth can even reach dozens, further exacerbating this issue. To mitigate this problem, we introduce LORS (LOw-rank Residual Structure). LORS allows stacked modules to share the majority of parameters, requiring a much smaller number of unique ones per module to match or even surpass the performance of using entirely distinct ones, thereby significantly reducing parameter usage. We validate our method by applying it to the stacked decoders of a query-based object detector, and conduct extensive experiments on the widely used MS COCO dataset. Experimental results demonstrate the effectiveness of our method, as even with a 70\% reduction in the parameters of the decoder, our method still enables the model to achieve comparable or even better performance than its original. |
|
Highlight
|
Poster
[ Arch 4A-E ] 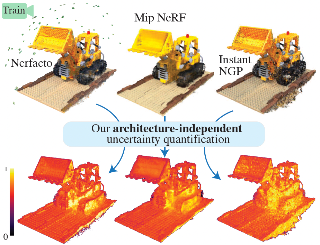
AbstractNeural Radiance Fields (NeRFs) have shown promise in applications like view synthesis and depth estimation, butlearning from multiview images faces inherent uncertainties. Current methods to quantify them are either heuristicor computationally demanding. We introduce BayesRays, a post-hoc framework to evaluate uncertainty in any pretrained NeRF without modifying the training process. Our method establishes a volumetric uncertainty field using spatial perturbations and a Bayesian Laplace approximation. We derive our algorithm statistically and show its superior performance in key metrics and applications. Additional results available at: https://bayesrays.github.io/ |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractSingle-point annotation in visual tasks, with the goal of minimizing labelling costs, is becoming increasingly prominent in research. Recently, visual foundation models, such as Segment Anything (SAM), have gained widespread usage due to their robust zero-shot capabilities and exceptional annotation performance. However, SAM's class-agnostic output and high confidence in local segmentation introduce 'semantic ambiguity', posing a challenge for precise category-specific segmentation. In this paper, we introduce a cost-effective category-specific segmenter using SAM. To tackle this challenge, we have devised a Semantic-Aware Instance Segmentation Network (SAPNet) that integrates Multiple Instance Learning (MIL) with matching capability and SAM with point prompts. SAPNet strategically selects the most representative mask proposals generated by SAM to supervise segmentation, with a specific focus on object category information. Moreover, we introduce the Point Distance Guidance and Box Mining Strategy to mitigate inherent challenges: 'group' and 'local' issues in weakly supervised segmentation. These strategies serve to further enhance the overall segmentation performance. The experimental results on Pascal VOC and COCO demonstrate the promising performance of our proposed SAPNet, emphasizing its semantic matching capabilities and its potential to advance point-prompted instance segmentation. The code are available at https://github.com/CVPR666/SAPNet. |
|
Highlight
|
Poster
[ Arch 4A-E ] 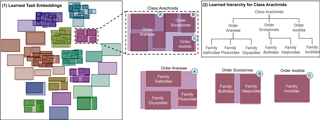
AbstractModeling and visualizing relationships between tasks or datasets is an important step towards solving various meta-tasks such as dataset discovery, multi-tasking, and transfer learning. However, many relationships, such as containment and transferability, are naturally asymmetric and current approaches for representation and visualization (e.g., t-SNE) do not readily support this. We propose Task2Box, an approach to represent tasks using box embeddings---axis-aligned hyperrectangles in low dimensional spaces---that can capture asymmetric relationships between them through volumetric overlaps. We show that Task2Box accurately predicts unseen hierarchical relationships between nodes in ImageNet and iNaturalist datasets, as well as transferability between tasks in the Taskonomy benchmark. We also show that box embeddings estimated from task representations (e.g., CLIP, Task2Vec, or attribute based) can be used to predict relationships between unseen tasks more accurately than classifiers trained on the same representations, as well as handcrafted asymmetric distances (e.g., KL divergence). This suggests that low-dimensional box embeddings can effectively capture these task relationships and have the added advantage of being interpretable. We use the approach to visualize relationships among publicly available image classification datasets on popular dataset hosting platform called Hugging Face. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractText-guided diffusion models have revolutionized image and video generation and have also been successfully used for optimization-based 3D object synthesis. Here, we instead focus on the underexplored text-to-4D setting and synthesize dynamic, animated 3D objects using score distillation methods with an additional temporal dimension. Compared to previous work, we pursue a novel compositional generation-based approach, and combine text-to-image, text-to-video, and 3D-aware multiview diffusion models to provide feedback during 4D object optimization, thereby simultaneously enforcing temporal consistency, high-quality visual appearance and realistic geometry. Our method, called Align Your Gaussians (AYG), leverages dynamic 3D Gaussian Splatting with deformation fields as 4D representation. Crucial to AYG is a novel method to regularize the distribution of the moving 3D Gaussians and thereby stabilize the optimization and induce motion. We also propose a motion amplification mechanism as well as a new autoregressive synthesis scheme to generate and combine multiple 4D sequences for longer generation. These techniques allow us to synthesize vivid dynamic scenes, outperform previous work qualitatively and quantitatively and achieve state-of-the-art text-to-4D performance. Due to the Gaussian 4D representation, different 4D animations can be seamlessly combined, as we demonstrate. AYG opens up promising avenues for animation, simulation and digital content creation as well … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWith the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that can not be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., MVChat, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, … |
|
Highlight
|
Poster
[ Arch 4A-E ] 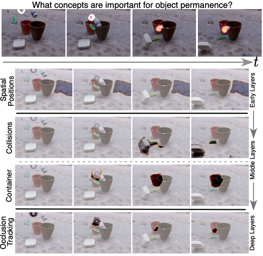
AbstractThis paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks, like image classification. Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time.In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations - concepts. We then design a noise-robust algorithm for ranking the importance of these units to the output of a model, allowing us to analyze its decision making process. Performing this analysis jointly over a diverse set of supervised and self-supervised models we make a number of important discoveries about universal units of video representations. Finally, we demonstrate that VTCD can be used to improve model performance for fine-grained tasks. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractPose regression networks predict the camera pose of a query image relative to a known environment.Within this family of methods, absolute pose regression (APR) has recently shown promising accuracy in the range of a few centimeters in position error. APR networks encode the scene geometry implicitly in their weights. To achieve high accuracy, they require vast amounts of training data that, realistically, can only be created using novel view synthesis in a days-long process. This process has to be repeated for each new scene again and again. We present a new approach to pose regression, map-relative pose regression (marepo), that satisfies the data hunger of the pose regression network in a scene-agnostic fashion. We condition the pose regressor on a scene-specific map representation such that its pose predictions are relative to the scene map. This allows us to train the pose regressor across hundreds of scenes to learn the generic relation between a scene-specific map representation and the camera pose. Our map-relative pose regressor can be applied to new map representations immediately or after mere minutes of fine-tuning for the highest accuracy. Our approach outperforms previous pose regression methods by far on two public datasets, indoor and outdoor. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractExisting counting tasks are limited to the class level, which don’t account for fine-grained details within the class. In real applications, it often requires in-context or referring human input for counting target objects. Take urban analysis as an example, fine-grained information such as traffic flow in different directions, pedestrians and vehicles waiting or moving at different sides of the junction, is more beneficial. Current settings of both class-specific and class-agnostic counting treat objects of the same class indifferently, which pose limitations in real use cases. To this end, we propose a new task named Referring Expression Counting (REC) which aims to count objects with different attributes within the same class. To evaluate the REC task, we create a novel dataset named REC-8K which contains 8011 images and 17122 referring expressions. Experiments on REC-8K show that our proposed method achieves state-of-the-art performance compared with several text-based counting methods and an open-set object detection model. We also outperform prior models on the class agnostic counting (CAC) benchmark [36] for the zero-shot setting, and perform on par with the few-shot methods. Code and dataset is available at https://github.com/sydai/referring-expression-counting. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe introduce PhysGaussian, a new method that seamlessly integrates physically grounded Newtonian dynamics within 3D Gaussians to achieve high-quality novel motion synthesis. Employing a customized Material Point Method (MPM), our approach enriches 3D Gaussian kernels with physically meaningful kinematic deformation and mechanical stress attributes, all evolved in line with continuum mechanics principles. A defining characteristic of our method is the seamless integration between physical simulation and visual rendering: both components utilize the same 3D Gaussian kernels as their discrete representations. This negates the necessity for triangle/tetrahedron meshing, marching cubes, cage meshes, or any other geometry embedding, highlighting the principle of "what you see is what you simulate (WS^2)". Our method demonstrates exceptional versatility across a wide variety of materials--including elastic entities, plastic metals, non-Newtonian fluids, and granular materials--showcasing its strong capabilities in creating diverse visual content with novel viewpoints and movements. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractThe robust association of the same objects across video frames in complex scenes is crucial for many applications, especially multiple object tracking (MOT). Current methods predominantly rely on labeled domain-specific video datasets, which limits the cross-domain generalization of learned similarity embeddings.We propose MASA, a novel method for robust instance association learning, capable of matching any objects within videos across diverse domains without tracking labels. Leveraging the rich object segmentation from the Segment Anything Model (SAM), MASA learns instance-level correspondence through exhaustive data transformations. We treat the SAM outputs as dense object region proposals and learn to match those regions from a vast image collection.We further design a universal MASA adapter which can work in tandem with foundational segmentation or detection models and enable them to track any detected objects. Those combinations present strong zero-shot tracking ability in complex domains.Extensive tests on multiple challenging MOT and MOTS benchmarks indicate that the proposed method, using only unlabelled static images, achieves even better performance than state-of-the-art methods trained with fully annotated in-domain video sequences, in zero-shot association. Our code is available at https://github.com/siyuanliii/masa. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWhile Multi-modal Language Models (\textit{MLMs}) demonstrate impressive multimodal ability, they still struggle on providing factual and precise responses for tasks like visual question answering (\textit{VQA}).In this paper, we address this challenge from the perspective of contextual information. We propose Causal Context Generation, \textbf{Causal-CoG}, which is a prompting strategy that engages contextual information to enhance precise VQA during inference. Specifically, we prompt MLMs to generate contexts, i.e, text description of an image, and engage the generated contexts for question answering. Moreover, we investigate the advantage of contexts on VQA from a causality perspective, introducing causality filtering to select samples for which contextual information is helpful. To show the effectiveness of Causal-CoG, we run extensive experiments on 10 multimodal benchmarks and show consistent improvements, \emph{e.g.}, +6.30\% on POPE, +13.69\% on Vizwiz and +6.43\% on VQAv2 compared to direct decoding, surpassing existing methods. We hope Casual-CoG inspires explorations of context knowledge in multimodal models, and serves as a plug-and-play strategy for MLM decoding. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractPerception plays a crucial role in various robot applications. However, existing well-annotated datasets are biased towards autonomous driving scenarios, while unlabelled SLAM datasets are quickly over-fitted, and often lack environment and domain variations. To expand the frontier of these fields, we introduce a comprehensive dataset named MCD (Multi-Campus Dataset), featuring a wide range of sensing modalities, high-accuracy ground truth, and diverse challenging environments across three Eurasian university campuses. MCD comprises both CCS (Classical Cylindrical Spinning) and NRE (Non-Repetitive Epicyclic) lidars, high-quality IMUs (Inertial Measurement Units), cameras, and UWB (Ultra-WideBand) sensors. Furthermore, in a pioneering effort, we introduce semantic annotations of 29 classes over 59k sparse NRE lidar scans across three domains, thus providing a novel challenge to existing semantic segmentation research upon this largely unexplored lidar modality. Finally, we propose, for the first time to the best of our knowledge, continuous-time ground truth based on optimization-based registration of lidar-inertial data on large survey-grade prior maps, which are also publicly released, each several times the size of existing ones. We conduct a rigorous evaluation of numerous state-of-the-art algorithms on MCD, report their performance, and highlight the challenges awaiting solutions from the research community. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractConstructing photo-realistic Free-Viewpoint Videos (FVVs) of dynamic scenes from multi-view videos remains a challenging endeavor. Despite the remarkable advancements achieved by current neural rendering techniques, these methods generally require complete video sequences for offline training and are not capable of real-time rendering. To address these constraints, we introduce 3DGStream, a method designed for efficient FVV streaming of real-world dynamic scenes. Our method achieves fast on-the-fly per-frame reconstruction within 12 seconds and real-time rendering at 200 FPS. Specifically, we utilize 3D Gaussians (3DGs) to represent the scene. Instead of the naïve approach of directly optimizing 3DGs per-frame, we employ a compact Neural Transformation Cache (NTC) to model the translations and rotations of 3DGs, markedly reducing the training time and storage required for each FVV frame. Furthermore, we propose an adaptive 3DG addition strategy to handle emerging objects in dynamic scenes. Experiments demonstrate that 3DGStream achieves competitive performance in terms of rendering speed, image quality, training time, and model storage when compared with state-of-the-art methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractImage diffusion models have been utilized in various tasks, such as text-to-image generation and controllable image synthesis. Recent research has introduced tuning methods that make subtle adjustments to the original models, yielding promising results in specific adaptations of foundational generative diffusion models. Rather than modifying the main backbone of the diffusion model, we delve into the role of skip connection in U-Net and reveal that hierarchical features aggregating long-distance information across encoder and decoder make a significant impact on the content and quality of image generation. Based on the observation, we propose an efficient generative tuning framework, dubbed SCEdit, which integrates and edits Skip Connection using a lightweight tuning module named SC-Tuner. Furthermore, the proposed framework allows for straightforward extension to controllable image synthesis by injecting different conditions with Controllable SC-Tuner, simplifying and unifying the network design for multi-condition inputs. Our SCEdit substantially reduces training parameters, memory usage, and computational expense due to its lightweight tuners, with backward propagation only passing to the decoder blocks. Extensive experiments conducted on text-to-image generation and controllable image synthesis tasks demonstrate the superiority of our method in terms of efficiency and performance. Project page: https://scedit.github.io/. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractIn this paper we propose an efficient data-driven solution to self-localization within a floorplan.Floorplan data is readily available, long-term persistent and inherently robust to changes in the visual appearance.Our method does not require retraining per map and location or demand a large database of images of the area of interest.We propose a novel probabilistic model consisting of an observation and a novel temporal filtering module.Operating internally with an efficient ray-based representation, the observation module consists of a single and a multiview module to predict horizontal depth from images and fuses their results to benefit from advantages offered by either methodology.Our method operates on conventional consumer hardware and overcomes a common limitation of competing methods that often demand upright images.Our full system meets real-time requirements, while outperforming the state-of-the-art by a significant margin. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractGenerative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts.Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images.In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt.We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation.We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process.Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractUnderwater visual understanding has recently gained increasing attention within the computer vision community for studying and monitoring underwater ecosystems. Among these, coral reefs play an important and intricate role, often referred to as the rainforests of the sea, due to their rich biodiversity and crucial environmental impact. Existing coral analysis, due to its technical complexity, requires significant manual work from coral biologists, therefore hindering scalable and comprehensive studies. In this paper, we introduce CoralSCOP, the first foundation model designed for the automatic dense segmentation of coral reefs. CoralSCOP is developed to accurately assign labels to different coral entities, addressing the challenges in the semantic analysis of coral imagery. Its main objective is to identify and delineate the irregular boundaries between various coral individuals across different granularities, such as coral/non-coral, growth form, and genus. This task is challenging due to the semantic agnostic nature or fixed limited semantic categories of previous generic segmentation methods, which fail to adequately capture the complex characteristics of coral structures. By introducing a novel parallel semantic branch, CoralSCOP can produce high-quality coral masks with semantics that enable a wide range of downstream coral reef analysis tasks. We demonstrate that CoralSCOP exhibits a strong zero-shot ability … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe introduce GaussianAvatars, a new method to create photorealistic head avatars that are fully controllable in terms of expression, pose, and viewpoint. The core idea of our method is a dynamic 3D representation based on 3D Gaussian splats that are rigged to a parametric morphable face model. This combination facilitates photorealistic rendering while also allowing for precise animation control via the underlying parametric model, e.g., through expression transfer from a driving sequence of a different person or by manually changing the morphable model parameters. In addition to the geometry of the morphable model itself, we optimize for explicit displacement offsets to obtain a more accurate geometric representation. Each splat location is then parameterized by a local coordinate frame to compensate for inaccuracies. During avatar reconstruction, we jointly optimize for the morphable model parameters and Gaussian splat parameters in an end-to-end fashion. We demonstrate the animation capabilities of our photorealistic avatar in several challenging scenarios. For instance, we show reenactments from a driving video, where our method outperforms existing works by a significant margin. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWhile existing backdoor attacks have successfully infected multimodal contrastive learning models such as CLIP, they can be easily countered by specialized backdoor defenses for MCL models. This paper reveals the threats in this practical scenario and introduces the BadCLIP attack, which is resistant to backdoor detection and model fine-tuning defenses. To achieve this, we draw motivations from the perspective of the Bayesian rule and propose a dual-embedding guided framework for backdoor attacks. Specifically, we ensure that visual trigger patterns approximate the textual target semantics in the embedding space, making it challenging to detect the subtle parameter variations induced by backdoor learning on such natural trigger patterns. Additionally, we optimize the visual trigger patterns to align the poisoned samples with target vision features in order to hinder backdoor unlearning through clean fine-tuning. Our experiments show a significant improvement in attack success rate (+45.3 % ASR) over current leading methods, even against state-of-the-art backdoor defenses, highlighting our attack's effectiveness in various scenarios, including downstream tasks. Our codes can be found at https://github.com/LiangSiyuan21/BadCLIP. |
|
Highlight
|
Poster
[ Arch 4A-E ] 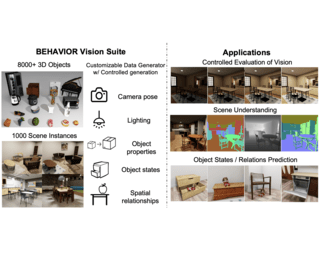
AbstractThe systematic evaluation and understanding of computer vision models under varying conditions require large amounts of data with comprehensive and customized labels, which real-world vision datasets rarely satisfy. While current synthetic data generators offer a promising alternative, particularly for embodied AI tasks, they often fall short for computer vision tasks due to low asset and rendering quality, limited diversity, and unrealistic physical properties. We introduce the BEHAVIOR Vision Suite (BVS), a set of tools and assets to generate fully customized synthetic data for systematic evaluation of computer vision models, based on the newly developed embodied AI benchmark, BEHAVIOR-1K. BVS supports a large number of adjustable parameters at the scene level (e.g., lighting, object placement), the object level (e.g., joint configuration, attributes such as "filled" and "folded"), and the camera level (e.g., field of view, focal length). Researchers can arbitrarily vary these parameters during data generation to perform controlled experiments. We showcase three example application scenarios: systematically evaluating the robustness of models across different continuous axes of domain shift, evaluating scene understanding models on the same set of images, and training and evaluating simulation-to-real transfer for a novel vision task: unary and binary state prediction. Project website: https://behavior-vision-suite.github.io/ |
|
Highlight
|
Poster
[ Arch 4A-E ] 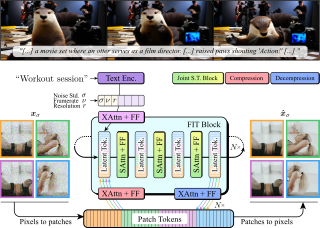
AbstractContemporary models for generating images show remarkable quality and versatility. Swayed by these advantages, the research community repurposes them to generate videos. Since video content is highly redundant, we argue that naively bringing advances of image models to the video generation domain reduces motion fidelity, visual quality and impairs scalability. In this work, we build Snap Video, a video-first model that systematically addresses these challenges. To do that, we first extend the EDM framework to take into account spatially and temporally redundant pixels and naturally support video generation. Second, we show that a U-Net—a workhorse behind image generation—scales poorly when generating videos, requiring significant computational overhead. Hence, we propose a new transformer-based architecture that trains 3.31 times faster than U-Nets (and is ~4.5 faster at inference). This allows us to efficiently train a text-to-video model with billions of parameters for the first time, reach state-of-the-art results on a number of benchmarks, and generate videos with substantially higher quality, temporal consistency, and motion complexity. The user studies showed that our model was favored by a large margin over the most recent methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractNeural radiance fields (NeRFs) have gained popularity in the autonomous driving (AD) community. Recent methods show NeRFs' potential for closed-loop simulation, enabling testing of AD systems, and as an advanced training data augmentation technique. However, existing methods often require long training times, dense semantic supervision, or lack generalizability. This, in turn, hinders the application of NeRFs for AD at scale. In this paper, we propose NeuRAD, a robust novel view synthesis method tailored to dynamic AD data. Our method features simple network design, extensive sensor modeling for both camera and lidar --- including rolling shutter, beam divergence and ray dropping --- and is applicable to multiple datasets out of the box. We verify its performance on five popular AD datasets, achieving state-of-the-art performance across the board. To encourage further development, we openly release the NeuRAD source code. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractExisting learning-based solutions to medical image segmentation have two important shortcomings. First, for most new segmentation task, a new model has to be trained or fine-tuned. This requires extensive resources and machine learning expertise, and is therefore often infeasible for medical researchers and clinicians. Second, most existing segmentation methods produce a single deterministic segmentation mask for a given image. In practice however, there is often considerable uncertainty about what constitutes the correct segmentation, and different expert annotators will often segment the same image differently. We tackle both of these problems with Tyche, a model that uses a context set to generate stochastic predictions for previously unseen tasks without the need to retrain. Tyche differs from other in-context segmentation methods in two important ways. (1) We introduce a novel convolution block architecture that enables interactions among predictions. (2) We introduce in-context test-time augmentation, a new mechanism to provide prediction stochasticity. When combined with appropriate model design and loss functions, Tyche can predict a set of plausible diverse segmentation candidates for new or unseen medical images and segmentation tasks without the need to retrain. Code available at: https://github.com/mariannerakic/tyche/ |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractHumans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractMulti-view inverse rendering is the problem of estimating the scene parameters such as shapes, materials, or illuminations from a sequence of images captured under different viewpoints. Many approaches, however, assume single light bounce and thus fail to recover challenging scenarios like inter-reflections. On the other hand, simply extending those methods to consider multi-bounced light requires more assumptions to alleviate the ambiguity. To address this problem, we propose Neural Incident Stokes Fields (NeISF), a multi-view inverse rendering framework that reduces ambiguities using polarization cues. The primary motivation for using polarization cues is that it is the accumulation of multi-bounced light, providing rich information about geometry and material. Based on this knowledge, the proposed incident Stokes field efficiently models the accumulated polarization effect with the aid of an original physically-based differentiable polarimetric renderer. Lastly, experimental results show that our method outperforms the existing works in synthetic and real scenarios. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractEvent-based semantic segmentation (ESS) is a fundamental yet challenging task for event camera sensing. The difficulties in interpreting and annotating event data limit its scalability. While domain adaptation from images to event data can help to mitigate this issue, there exist data representational differences that require additional effort to resolve. In this work, for the first time, we synergize information from image, text, and event-data domains and introduce OpenESS to enable scalable ESS in an open-world, annotation-efficient manner. We achieve this goal by transferring the semantically rich CLIP knowledge from image-text pairs to event streams. To pursue better cross-modality adaptation, we propose a frame-to-event contrastive distillation and a text-to-event semantic consistency regularization. Experimental results on popular ESS benchmarks showed our approach outperforms existing methods. Notably, we achieve 53.93% and 43.31% mIoU on DDD17 and DSEC-Semantic without using either event or frame labels. |
|
Highlight
|
Poster
[ Arch 4A-E ] 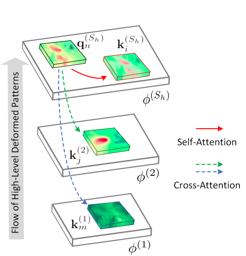
AbstractThis paper introduces a novel top-down representation approach for deformable image registration, which estimates the deformation field by capturing various short- and long-range flow features at different scale levels. As a Hierarchical Vision Transformer (H-ViT), we propose a dual self-attention and cross-attention mechanism that uses high-level features in the deformation field to represent low-level ones, enabling information streams in the deformation field across all voxel patch embeddings irrespective of their spatial proximity. Since high-level features contain abstract flow patterns, such patterns are expected to positively contribute to the representation of the deformation field in lower scales. When the self-attention module utilizes within-scale short-range patterns for representation, the cross-attention modules dynamically look for the key tokens across different scales to further interact with the local query voxel patches. Our method shows superior accuracy and visual quality in deformable image registration over the state-of-the-art in five publicly available datasets, highlighting a substantial enhancement in the performance of medical imaging registration. The code and pre-trained models are available at https://github.com/---. |
|
Highlight
|
Poster
[ Arch 4A-E ] 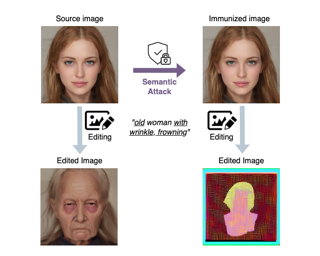
AbstractRecent text-to-image (T2I) diffusion models have revolutionized image editing by empowering users to control outcomes using natural language. However, the ease of image manipulation has raised ethical concerns, with the potential for malicious use in generating deceptive or harmful content. To address the concerns, we propose an image immunization approach named semantic attack to protect our images from being manipulated by malicious agents using diffusion models. Our approach focuses on disrupting the semantic understanding of T2I diffusion models regarding specific content. By attacking the cross-attention mechanism that encodes image features with text messages during editing, we distract the model's attention regarding the content of our concern. Our semantic attack renders the model uncertain about the areas to edit, resulting in poorly edited images and contradicting the malicious editing attempts. In addition, by shifting the attack target towards intermediate attention maps from the final generated image, our approach substantially diminishes computational burden and alleviates GPU memory constraints in comparison to previous methods. Moreover, we introduce timestep universal gradient updating to create timestep-agnostic perturbations effective across different input noise levels. By treating the full diffusion process as discrete denoising timesteps during the attack, we achieve equivalent or even superior immunization efficacy with … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractMusic is a universal language that can communicate emotions and feelings. It forms an essential part of the whole spectrum of creative media, ranging from movies to social media posts. Machine learning models that can synthesize music are predominantly conditioned on textual descriptions of it. Inspired by how musicians compose music not just from a movie script, but also through visualizations, we propose MeLFusion, a model that can effectively use cues from a textual description and the corresponding image to synthesize music. MeLFusion is a text-to-music diffusion model with a novel "visual synapse", which effectively infuses the semantics from the visual modality into the generated music. To facilitate research in this area, we introduce a new dataset MeLBench, and propose a new evaluation metric IMSM. Our exhaustive experimental evaluation suggests that adding visual information to the music synthesis pipeline significantly improves the quality of generated music, measured both objectively and subjectively, with a relative gain of up to 67.98% on the FAD score. We hope that our work will gather attention to this pragmatic, yet relatively under-explored research area. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractThe advancing of human-scene interaction modeling confronts substantial challenges in the scarcity of high-quality data and advanced motion synthesis methods. Previous endeavors have been inadequate in offering sophisticated datasets that effectively tackle the dual challenges of scalability and data quality. In this work, we overcome these challenges by introducing TRUMANS, a large-scale \mocap dataset created by efficiently and precisely replicating the synthetic scenes in the physical environment. TRUMANS, featuring the most extensive motion-capturedhuman-scene interaction datasets thus far, comprises over 15 hours of diverse human behaviors, including concurrent interactions with dynamic and articulated objects, across 100 indoor scene configurations. It provides accurate pose sequences of both humans and objects, ensuring a high level of contact plausibility during the interaction. Additionally, we also propose a data augmentation approach that automatically adapts collision-free and interaction-precise human motions, significantly increasing the diversity of both interacting objects and scene backgrounds.Leveraging the benefits of TRUMANS, we propose a novel approach that employs a diffusion-based autoregressive mechanism for the real-time generation of human-scene interaction sequences with arbitrary length.The efficacy of TRUMANS and our motion synthesis method is validated through extensive experimental results, surpassing all existing baselines in terms of quality and diversity. Notably, our method demonstrates superb … |
|
Highlight
|
Poster
[ Arch 4A-E ] 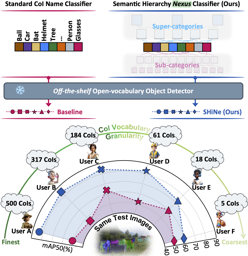
AbstractOpen-vocabulary object detection (OvOD) has transformed detection into a language-guided task, empowering users to freely define their class vocabularies of interest during inference. However, our initial investigation indicates that existing OvOD detectors exhibit significant variability when dealing with vocabularies across various semantic granularities, posing a concern for real-world deployment. To this end, we introduce Semantic Hierarchy Nexus (SHiNe), a novel classifier that leverages semantic knowledge from class hierarchies. It is built offline in three steps: i) it retrieves relevant super-/sub-categories from a hierarchy for each target class; ii) it integrates these categories into hierarchy-aware sentences; iii) it fuses these sentence embeddings to generate the nexus classifier vector. Our evaluation on various detection benchmarks demonstrates that SHiNe enhances robustness across diverse vocabulary granularities, achieving up to +31.9% mAP50 with an existing hierarchy, while retaining improvements using hierarchies generated by large language models. Moreover, when applied to open-vocabulary classification on ImageNet-1k, SHiNe improves the CLIP zero-shot baseline by +2.8% accuracy. SHiNe is training-free and can be seamlessly integrated with any off-the-shelf OvOD detector, without incurring extra computational overhead during inference. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe investigate a new task in human motion prediction, which is predicting motions under unexpected physical perturbation potentially involving multiple people. Compared with existing research, this task involves predicting less controlled, unpremeditated and pure reactive motions in response to external impact and how such motions can propagate through people. It brings new challenges such as data scarcity and predicting complex interactions. To this end, we propose a new method capitalizing differential physics and deep neural networks, leading to an explicit Latent Differential Physics (LDP) model. Through experiments, we demonstrate that LDP has high data efficiency, outstanding prediction accuracy, strong generalizability and good explainability. Since there is no similar research, a comprehensive comparison with 11 adapted baselines from several relevant domains is conducted, showing LDP outperforming existing research both quantitatively and qualitatively, improving prediction accuracy by as much as 70%, and demonstrating significantly stronger generalization. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Stereo matching methods based on iterative optimization, like RAFT-Stereo and IGEV-Stereo, have evolved into a cornerstone in the field of stereo matching. However, these methods struggle to simultaneously capture high-frequency information in edges and low-frequency information in smooth regions due to the fixed receptive field. As a result, they tend to lose details, blur edges, and produce false matches in textureless areas. In this paper, we propose Selective Recurrent Unit (SRU), a novel iterative update operator for stereo matching. The SRU module can adaptively fuse hidden disparity information at multiple frequencies for edge and smooth regions. To perform adaptive fusion, we introduce a new Contextual Spatial Attention (CSA) module to generate attention maps as fusion weights. The SRU empowers the network to aggregate hidden disparity information across multiple frequencies, mitigating the risk of vital hidden disparity information loss during iterative processes. To verify SRU's universality, we apply it to representative iterative stereo matching methods, collectively referred to as Selective-Stereo. Our Selective-Stereo ranks $1^{st}$ on KITTI 2012, KITTI 2015, ETH3D, and Middlebury leaderboards among all published methods. The source code will be available upon the publicity of the paper.
|
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractOur brain can effortlessly recognize objects even when partially hidden from view. Seeing the visible of the hidden is called amodal completion; however, this task remains a challenge for generative AI despite rapid progress. We propose to sidestep many of the difficulties of existing approaches, which typically involve a two-step process of predicting amodal masks and then generating pixels. Our method involves thinking outside the box, literally! We go outside the object bounding box to use its context to guide a pre-trained diffusion inpainting model, and then progressively grow the occluded object and trim the extra background. We overcome two technical challenges: 1) how to be free of unwanted co-occurrence bias, which tends to regenerate similar occluders, and 2) how to judge if an amodal completion has succeeded. Our amodal completion method exhibits improved photorealistic completion results compared to existing approaches in numerous successful completion cases. And the best part? It doesn't require any special training or fine-tuning of models. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractText-to-image diffusion models have demonstrated remarkable capabilities in transforming text prompts into coherent images, yet the computational cost of the multi-step inference remains a persistent challenge. To address this issue, we present UFOGen, a novel generative model designed for ultra-fast, one-step text-to-image generation. In contrast to conventional approaches that focus on improving samplers or employing distillation techniques for diffusion models, UFOGen adopts a hybrid methodology, integrating diffusion models with a GAN objective. Leveraging a newly introduced diffusion-GAN objective and initialization with pre-trained diffusion models, UFOGen excels in efficiently generating high-quality images conditioned on textual descriptions in a single step. Beyond traditional text-to-image generation, UFOGen showcases versatility in applications. Notably, UFOGen stands among the pioneering models enabling one-step text-to-image generation and diverse downstream tasks, presenting a significant advancement in the landscape of efficient generative models. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractTransformer-based models have revolutionized the field of image super-resolution by harnessing their inherent ability to capture complex contextual features. The overlapping rectangular shifted window technique used in transformer architecture nowadays is a common practice in super-resolution models to improve the quality and robustness of image upscaling. However, it suffers from distortion at the boundaries and has limited unique shifting modes. To overcome these weaknesses, we propose an overlapping triangular window technique that synchronously works with the rectangular one to reduce boundary-level distortion and allow the model to access more unique sifting modes. In this paper, we propose a Composite Fusion Attention Transformer (CFAT) that incorporates triangular-rectangular window-based local attention with a channel-based global attention technique in image super-resolution. As a result, CFAT enables attention mechanisms to be activated on more image pixels and captures long-range, multi-scale features to improve SR performance. The extensive experimental results and ablation study demonstrate the effectiveness of CFAT in the SR domain. Our proposed model shows a significant 0.7 dB performance improvement over other state-of-the-art SR architectures. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDichotomous Image Segmentation (DIS) has recently emerged towards highly accurate objects from high-resolution natural images.When designing an effective DIS model, the most challenge is how to balance the semantic dispersion of high-resolution targets in the small receptive field and the loss of high-precision details in the large receptive field. Existing methods rely on tedious multiple encoder-decoder streams and stages to gradually complete the global localization and local refinement. Inspired by the human visual system capturing regions of interest by observing from multiple views, we model DIS as a multi-view object perception problem and provide a parsimonious multi-view aggregation network (MVANet), which unifies the feature fusion of the distant view and close-up view into a single stream with one encoder-decoder structure. With the help of the proposed multi-view complementary localization and refinement modules, our approach established long-range, profound visual interactions across multiple views, allowing the features of the detailed close-up view to focus on refining highly accurate details. Experiments on the popular DIS-5K dataset show that our MVANet significantly outperforms state-of-the-art methods in both accuracy and speed. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractFew-Shot Class Incremental Learning (FSCIL) introduces a paradigm in which the problem space expands with limited data. FSCIL methods inherently face the challenge of catastrophic forgetting as data arrives incrementally, making models susceptible to overwriting previously acquired knowledge. Moreover, given the scarcity of labeled samples available at any given time, models may be prone to overfitting and find it challenging to strike a balance between extensive pretraining and the limited incremental data. To address these challenges, we propose the OrCo framework built on two core principles: features' orthogonality in the representation space, and contrastive learning. In particular, we improve the generalization of the embedding space by employing a combination of supervised and self-supervised contrastive losses during the pretraining phase. Additionally, we introduce OrCo loss to address challenges arising from data limitations during incremental sessions. Through feature space perturbations and orthogonality between classes, the OrCo loss maximizes margins and reserves space for the following incremental data. This, in turn, ensures the accommodation of incoming classes in the feature space without compromising previously acquired knowledge. Our experimental results showcase state-of-the-art performance across three benchmark datasets, including mini-ImageNet, CIFAR100, and CUB datasets. The code will be made publicly available. |
|
Highlight
|
Poster
[ Arch 4A-E ] 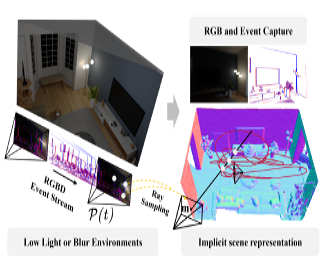
AbstractImplicit neural SLAM has achieved remarkable progress recently. Nevertheless, existing methods face significant challenges in non-ideal scenarios, such as motion blur or lighting variation, which often leads to issues like convergence failures, localization drifts, and distorted mapping. To address these challenges, we propose EN-SLAM, the first event-RGBD implicit neural SLAM framework, which effectively leverages the high rate and high dynamic range advantages of event data for tracking and mapping. Specifically, EN-SLAM proposes a differentiable CRF (Camera Response Function) rendering technique to generate distinct RGB and event camera data via a shared radiance field, which is optimized by learning a unified implicit representation with the captured event and RGBD supervision. Moreover, based on the temporal difference property of events, we propose a temporal aggregating optimization strategy for the event joint tracking and global bundle adjustment, capitalizing on the consecutive difference constraints of events, significantly enhancing tracking accuracy and robustness. Finally, we construct the simulated dataset DEV-Indoors and real captured dataset DEV-Reals containing 6 scenes, 17 sequences with practical motion blur and lighting changes for evaluations. Experimental results show that our method outperforms the SOTA methods in both tracking ATE and mapping ACC with a real-time 17 FPS in various challenging environments. … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractHuman action anticipation aims at predicting what people will do in the future based on past observations. In this paper, we introduce Uncertainty-aware Action Decoupling Transformer (UADT) for action anticipation. Unlike existing methods that directly predict action in a verb-noun pair format, we decouple the action anticipation task into verb and noun anticipations separately. The objective is to make the two decoupled tasks assist each other and eventually improve the action anticipation task. Specifically, we propose a two-stream Transformer-based architecture which is composed of a verb-to-noun model and a noun-to-verb model. The verb-to-noun model leverages the verb information to improve the noun prediction and the other way around. We extend the model in a probabilistic manner and quantify the predictive uncertainty of each decoupled task to select features. In this way, the noun prediction leverages the most informative and redundancy-free verb features and verb prediction works similarly. Finally, the two streams are combined dynamically based on their uncertainties to make the joint action anticipation. We demonstrate the efficacy of our method by achieving state-of-the-art performance on action anticipation benchmarks including EPIC-KITCHENS, EGTEA Gaze+, and 50 Salads. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWhile neural rendering has led to impressive advances in scene reconstruction and novel view synthesis, it relies heavily on accurately pre-computed camera poses. To relax this constraint, multiple efforts have been made to train Neural Radiance Fields (NeRFs) without pre-processed camera poses. However, the implicit representations of NeRFs provide extra challenges to optimize the 3D structure and camera poses at the same time. On the other hand, the recently proposed 3D Gaussian Splatting provides new opportunities given its explicit point cloud representations. This paper leverages both the explicit geometric representation and the continuity of the input video stream to perform novel view synthesis without any SfM preprocessing. We process the input frames in a sequential manner and progressively grow the 3D Gaussians set by taking one input frame at a time, without the need to pre-compute the camera poses. Our method significantly improves over previous approaches in view synthesis and camera pose estimation under large motion changes. Our code will be made publicly available. |
|
Highlight
|
Poster
[ Arch 4A-E ] 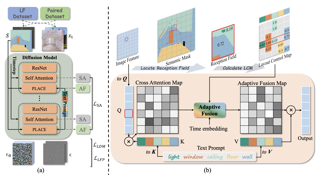
AbstractRecent advancements in large-scale pre-trained text-to-image models have led to remarkable progress in semantic image synthesis. Nevertheless, synthesizing high-quality images with consistent semantics and layout remains a challenge. In this paper, we propose the adaPtive LAyout-semantiC fusion modulE (PLACE) that harnesses pre-trained models to alleviate the aforementioned issues. Specifically, we first employ the layout control map to faithfully represent layouts in the feature space. Subsequently, we combine the layout and semantic features in a timestep-adaptive manner to synthesize images with realistic details. During fine-tuning, we propose the Semantic Alignment (SA) loss to further enhance layout alignment. Additionally, we introduce the Layout-Free Prior Preservation (LFP) loss, which leverages unlabeled data to maintain the priors of pre-trained models, thereby improving the visual quality and semantic consistency of synthesized images. Extensive experiments demonstrate that our approach performs favorably in terms of visual quality, semantic consistency, and layout alignment. The source code and model are available at \href{https://github.com/cszy98/PLACE/tree/main}{PLACE}. |
|
Highlight
|
Poster
[ Arch 4A-E ] 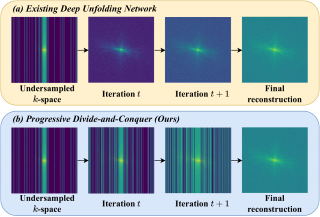
AbstractDeep unfolding networks (DUN) have emerged as a reliable iterative framework for accelerated magnetic resonance imaging (MRI) reconstruction.However, conventional DUN aims to reconstruct all the missing information within the entire null space in each iteration. Thus the reconstruction quality could be degraded due to the cumulative errors.In this work, we propose a Progressive Divide-And-Conquer (PDAC) strategy, aiming to break down the subsampling process in the actual severe degradation and thus perform reconstruction sequentially.Starting from decomposing the original maximum-a-posteriori problem of accelerated MRI, we present a rigorous derivation of the proposed PDAC framework, which could be further unfolded into an end-to-end trainable network.Specifically, each iterative stage in PDAC focuses on recovering a distinct moderate degradation according to the decomposition.Furthermore, as part of the PDAC iteration, such decomposition is adaptively learned as an auxiliary task through a degradation predictor which provides an estimation of the decomposed sampling mask.Following this prediction, the sampling mask is further integrated via a severity conditioning module to ensure awareness of the degradation severity at each stage.Extensive experiments demonstrate that our proposed method achieves superior performance on the publicly available fastMRI and Stanford2D FSE datasets in both single-coil and multi-coil settings. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe propose SceneTex, a novel method for effectively generating high-quality and style-consistent textures for indoor scenes using depth-to-image diffusion priors. Unlike previous methods that either iteratively warp 2D views onto a mesh surface or distillate diffusion latent features without accurate geometric and style cues, SceneTex formulates the texture synthesis task as an optimization problem in the RGB space where style and geometry consistency are properly reflected. At its core, SceneTex proposes a multiresolution texture field to implicitly encode the mesh appearance. We optimize the target texture via a score-distillation-based objective function in respective RGB renderings. To further secure the style consistency across views, we introduce a cross-attention decoder to predict the RGB values by cross-attending to the pre-sampled reference locations in each instance. SceneTex enables various and accurate texture synthesis for 3D-FRONT scenes, demonstrating significant improvements in visual quality and prompt fidelity over the prior texture generation methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] 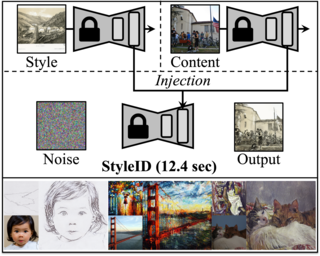
AbstractDespite the impressive generative capabilities of diffusion models, existing diffusion model-based style transfer methods require inference-stage optimization (e.g. fine-tuning or textual inversion of style) which is time-consuming, or fails to leverage the generative ability of large-scale diffusion models. To address these issues, we introduce a novel artistic style transfer method based on a pre-trained large-scale diffusion model without any optimization. Specifically, we manipulate the features of self-attention layers as the way the cross-attention mechanism works; in the generation process, substituting the key and value of content with those of style image. This approach provides several desirable characteristics for style transfer including 1) preservation of content by transferring similar styles into similar image patches and 2) transfer of style based on similarity of local texture (e.g. edge) between content and style images. Furthermore, we introduce query preservation and attention temperature scaling to mitigate the issue of disruption of original content, and initial latent Adaptive Instance Normalization (AdaIN) to deal with the disharmonious color (failure to transfer the colors of style). Our experimental results demonstrate that our proposed method surpasses state-of-the-art methods in both conventional and diffusion-based style transfer baselines. |
|
Highlight
|
Poster
[ Arch 4A-E ] 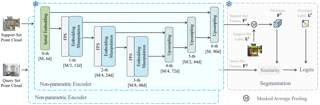
AbstractTo reduce the reliance on large-scale datasets, recent works in 3D segmentation resort to few-shot learning. Current 3D few-shot segmentation methods first pre-train models on 'seen' classes, and then evaluate their generalization performance on 'unseen' classes. However, the prior pre-training stage not only introduces excessive time overhead but also incurs a significant domain gap on 'unseen' classes. To tackle these issues, we propose a Non-parametric Network for few-shot 3D Segmentation, Seg-NN, and its Parameterized variant, Seg-PN. Without training, Seg-NN extracts dense representations by hand-crafted filters and achieves comparable performance to existing parameterized models. Due to the elimination of pre-training, Seg-NN can alleviate the domain gap issue and save a substantial amount of time. Based on Seg-NN, Seg-PN only requires training a lightweight QUEry-Support Transferring (QUEST) module, which enhances the interaction between the support set and query set. Experiments suggest that Seg-PN outperforms previous state-of-the-art method by +4.19% and +7.71% mIoU on S3DIS and ScanNet datasets respectively, while reducing training time by -90%, indicating its effectiveness and efficiency. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractComputer-Aided Design (CAD) model reconstruction from point clouds is an important problem at the intersection of computer vision, graphics, and machine learning; it saves the designer significant time when iterating on in-the-wild objects. Recent advancements in this direction achieve relatively reliable semantic segmentation but still struggle to produce an adequate topology of the CAD model. In this work, we analyze the current state of the art for that ill-posed task and identify shortcomings of existing methods. We propose a hybrid analytic-neural reconstruction scheme that bridges the gap between segmented point clouds and structured CAD models and can be readily combined with different segmentation backbones. Moreover, to power the surface fitting stage, we propose a novel implicit neural representation of freeform surfaces, driving up the performance of our overall CAD reconstruction scheme. We extensively evaluate our method on the popular ABC benchmark of CAD models and set a new state-of-the-art for that dataset. Code and models will be shared publicly. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractMulti-Instance Learning (MIL) has shown impressive performance for histopathology whole slide image (WSI) analysis using bags or pseudo-bags. It involves instance sampling, feature representation, and decision-making. However, existing MIL-based technologies at least suffer from one or more of the following problems: 1) requiring high storage and intensive pre-processing for numerous instances (sampling); 2) potential over-fitting with limited knowledge to predict bag labels (feature representation); 3) pseudo-bag counts and prior biases affect model robustness and generalizability (decision-making). Inspired by clinical diagnostics, using the past sampling instances can facilitate the final WSI analysis, but it is barely explored in prior technologies. To break free these limitations, we integrate the dynamic instance sampling and reinforcement learning into a unified framework to improve the instance selection and feature aggregation, forming a novel Dynamic Policy Instance Selection (DPIS) scheme for better and more credible decision-making. Specifically, the measurement of feature distance and reward function are employed to boost continuous instance sampling. To alleviate the over-fitting, we explore the latent global relations among instances for more robust and discriminative feature representation while establishing reward and punishment mechanisms to correct biases in pseudo-bags using contrastive learning. These strategies form the final Dynamic Policy-Driven Adaptive Multi-Instance Learning (PAMIL) … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractIn this paper, we propose an accurate post-training quantization framework of diffusion models (APQ-DM) for efficient image generation. Conventional quantization frameworks learn shared quantization functions for tensor discretization regardless of the generation timesteps in diffusion models, while the activation distribution differs significantly across various timesteps. Meanwhile, the calibration images are acquired in random timesteps which fail to provide sufficient information for generalizable quantization function learning. Both issues cause sizable quantization errors with obvious image generation performance degradation. On the contrary, we design distribution-aware quantization functions for activation discretization in different timesteps and search the optimal timesteps for informative calibration image generation, so that our quantized diffusion model can reduce the discretization errors with negligible computational overhead. Specifically, we partition various timestep quantization functions into different groups according to the importance weights, which are optimized by differentiable search algorithms. We also extend structural risk minimization principle for informative calibration image generation to enhance the generalization ability in the deployment of quantized diffusion model. Extensive experimental results show that our method outperforms the state-of-the-art post-training quantization of diffusion model by a sizable margin with similar computational cost. |
|
Highlight
|
Poster
[ Arch 4A-E ] 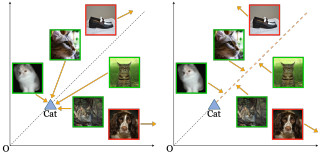
AbstractRecent advancements in machine learning have spotlighted the potential of hyperbolic spaces as they effectively learn hierarchical feature representations. While there has been progress in leveraging hyperbolic spaces in single-modality contexts, its exploration in multimodal settings remains under explored. Some recent efforts have sought to transpose Euclidean multimodal learning techniques to hyperbolic spaces, by adopting geodesic distance based contrastive losses. However, we show both theoretically and empirically that such spatial proximity based contrastive loss significantly disrupts hierarchies in the latent space. To remedy this, we advocate that the cross-modal representations should accept the inherent modality gap between text and images, and introduce a novel approach to measure cross-modal similarity that does not enforce spatial proximity. Our approach show remarkable capabilities in preserving unimodal hierarchies while aligning the two modalities. Our experiments on a series of downstream tasks demonstrate that better latent structure emerges with our objective function while being superior in text-to-image and image-to-text retrieval tasks. |
|
Highlight
|
Poster
[ Arch 4A-E ] 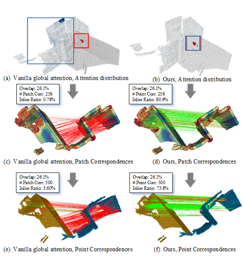
AbstractPoint Cloud Registration is a critical and challenging task in computer vision. Recent advancements have predominantly embraced a coarse-to-fine matching mechanism, with the key to matching the superpoints located in patches with inter-frame consistent structures. However, previous methods still face challenges with ambiguous matching, because the interference information aggregated from irrelevant regions may disturb the capture of inter-frame consistency relations, leading to wrong matches. To address this issue, we propose Dynamic Cues-Assisted Transformer (DCATr). Firstly, the interference from irrelevant regions is greatly reduced by constraining attention to certain cues, i.e., regions with highly correlated structures of potential corresponding superpoints. Secondly, cues-assisted attention is designed to mine the inter-frame consistency relations, while more attention is assigned to pairs with high consistent confidence in feature aggregation. Finally, a dynamic updating fashion is proposed to facilitate mining richer consistency information, further improving aggregated features' distinctiveness and relieving matching ambiguity. Extensive evaluations on indoor and outdoor standard benchmarks demonstrate that DCATr outperforms all state-of-the-art methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
We revisit certain problems of pose estimation based on 3D--2D correspondences between features which may be points or lines. Specifically, we address the two previously-studied minimal problems of estimating camera extrinsics from $p \in \{ 1, 2 \}$ point--point correspondences and $l=3-p$ line--line correspondences. To the best of our knowledge, all of the previously-known practical solutions to these problems required computing the roots of degree $\ge 4$ (univariate) polynomials when $p=2$, or degree $\ge 8$ polynomials when $p=1.$ We describe and implement two elementary solutions which reduce the degrees of the needed polynomials from $4$ to $2$ and from $8$ to $4$, respectively. We show experimentally that the resulting solvers are numerically stable and fast: when compared to the previous state-of-the art, we obtain nearly an order of magnitude speedup.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractSpiking Neural Networks (SNNs) have been widely praised for their high energy efficiency and immense potential. However, comprehensive research that critically contrasts and correlates SNNs with quantized Artificial Neural Networks (ANNs) remains scant, often leading to skewed comparisons lacking fairness towards ANNs. This paper introduces a unified perspective, illustrating that the simulation steps in SNNs and quantized bit-widths of activation values present analogous representations. Building on this, we present a more pragmatic and rational approach to estimating the energy consumption of SNNs. Diverging from the conventional Synaptic Operations (SynOps), we champion the "Bit Budget" concept. This notion permits an intricate discourse on strategically allocating computational and storage resources between weights, activation values, and temporal steps under stringent hardware constraints. Guided by the Bit Budget paradigm, we discern that pivoting efforts towards spike patterns and weight quantization, rather than temporal attributes, elicits profound implications for model performance. Utilizing the Bit Budget for holistic design consideration of SNNs elevates model performance across diverse data types, encompassing static imagery and neuromorphic datasets. Our revelations bridge the theoretical chasm between SNNs and quantized ANNs and illuminate a pragmatic trajectory for future endeavors in energy-efficient neural computations. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present a new dataset called Real Acoustic Fields (RAF) that captures real acoustic room data from multiple modalities. The dataset includes high-quality and densely captured room impulse response data paired with multi-view images, and precise 6DoF pose tracking data for sound emitters and listeners in the rooms. We used this dataset to evaluate existing methods for novel-view acoustic synthesis and impulse response generation which previously relied on synthetic data. In our evaluation, we thoroughly assessed existing audio and audio-visual models against multiple criteria and proposed settings to enhance their performance on real-world data. We also conducted experiments to investigate the impact of incorporating visual data (i.e., images and depth) into neural acoustic field models. Additionally, we demonstrated the effectiveness of a simple sim2real approach, where a model is pre-trained with simulated data and fine-tuned with sparse real-world data, resulting in significant improvements in the few-shot learning approach. \ourdata is the first dataset to provide densely captured room acoustic data, making it an ideal resource for researchers working on audio and audio-visual neural acoustic field modeling techniques. We will make our dataset publicly available. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractState-of-the-art models on contemporary 3D segmentation benchmarks like ScanNet consume and label dataset-provided 3D point clouds, obtained through post processing of sensed multiview RGB-D images. They are typically trained in-domain, forego large-scale 2D pre-training and outperform alternatives that featurize the posed RGB-D multiview images instead. The gap in performance between methods that consume posed images versus post-processed 3D point clouds has fueled the belief that 2D and 3D perception require distinct model architectures. In this paper, we challenge this view and propose ODIN (Omni-Dimensional INstance segmentation), a model that can segment and label both 2D RGB images and 3D point clouds, using a transformer architecture that alternates between 2D within-view and 3D cross-view information fusion. Our model differentiates 2D and 3D feature operations through the positional encodings of the tokens involved, which capture pixel coordinates for 2D patch tokens and 3D coordinates for 3D feature tokens. ODIN achieves state-of-the-art performance on ScanNet200, Matterport3D and AI2THOR 3D instance segmentation benchmarks, and competitive performance on ScanNet, S3DIS and COCO. It outperforms all previous works by a wide margin when the sensed 3D point cloud is used in place of the point cloud sampled from 3D mesh. When used as the 3D perception … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractLifting 2D diffusion for 3D generation is a challenging problem due to the lack of geometric prior and the complex entanglement of materials and lighting in natural images. Existing methods have shown promise by first creating the geometry through score-distillation sampling (SDS) applied to rendered surface normals, followed by appearance modeling. However, relying on a 2D RGB diffusion model to optimize surface normals is suboptimal due to the distribution discrepancy between natural images and normals maps, leading to instability in optimization. In this paper, recognizing that the normal and depth information effectively describe scene geometry and be automatically estimated from images, we propose to learn a generalizable Normal-Depth diffusion model for 3D generation. We achieve this by training on the large-scale LAION dataset together with the generalizable image-to-depth and normal prior models. In an attempt to alleviate the mixed illumination effects in the generated materials, we introduce an albedo diffusion model to impose data-driven constraints on the albedo component. Our experiments show that when integrated into existing text-to-3D pipelines, our models significantly enhance the detail richness, achieving state-of-the-art results. Our project page is at https://aigc3d.github.io/richdreamer/. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractUnderstanding what deep network models capture in their learned representations is a fundamental challenge in computer vision. We present a new methodology to understanding such vision models, the Visual Concept Connectome (VCC), which discovers human interpretable concepts and their interlayer connections in a fully unsupervised manner. Our approach simultaneously reveals fine-grained concepts at a layer, connection weightings across all layers and is amendable to global analysis of network structure (e.g., branching pattern of hierarchical concept assemblies). Previous work yielded ways to extract interpretable concepts from single layers and examine their impact on classification, but did not afford multilayer concept analysis across an entire network architecture. Quantitative and qualitative empirical results show the effectiveness of VCCs in the domain of image classification. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractAnnotation ambiguity due to inherent data uncertainties such as blurred boundaries in medical scans and different observer expertise and preferences has become a major obstacle for training deep-learning based medical image segmentation models. To address it, the common practice is to gather multiple annotations from different experts, leading to the setting of multi-rater medical image segmentation. Existing works aim to either merge different annotations into the "groundtruth" that is often unattainable in numerous medical contexts, or generate diverse results, or produce personalized results corresponding to individual expert raters. Here, we bring up a more ambitious goal for multi-rater medical image segmentation, i.e., obtaining both diversified and personalized results. Specifically, we propose a two-stage framework named D-Persona (first Diversification and then Personalization). In Stage I, we exploit multiple given annotations to train a Probabilistic U-Net model, with a bound-constrained loss to improve the prediction diversity. In this way, a common latent space is constructed in Stage I, where different latent codes denote diversified expert opinions. Then, in Stage II, we design multiple attention-based projection heads to adaptively query the corresponding expert prompts from the shared latent space, and then perform the personalized medical image segmentation. We evaluated the proposed model on … |
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with $6.8$M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWith recent developments in Embodied Artificial Intelligence (EAI) research, there has been a growing demand for high-quality, large-scale interactive scene generation. While prior methods in scene synthesis have primarily emphasized the naturalness and realism of the generated scenes, the physical plausibility and interactivity of scenes have been primarily left untouched. To bridge this gap, we introduce PhyScene, a novel approach dedicated to generating interactive 3D scenes characterized by realistic layouts, articulated objects, and rich physical interactivity tailored for embodied agents. Based on a conditional diffusion model for capturing scene layouts, we devise novel physics- and interactivity-based guidance functions encompassing constraints from both object collision, room layout, as well as agent interactivity. Through extensive experiments, we demonstrate that PhyScene effectively leverages these guidance functions for physically interactable scene synthesis, outperforming existing state-of-the-art scene synthesis methods by a large margin. We believe that our generated scenes could be broadly beneficial for agents to learn diverse skills within interactive scenes and pave the way for new research in embodied AI. |
|
Highlight
|
Poster
[ Arch 4A-E ] 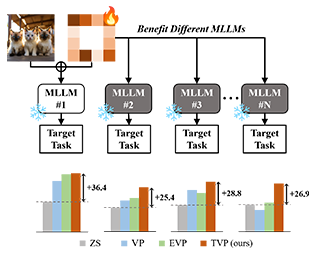
AbstractAlthough Multimodal Large Language Models (MLLMs) have demonstrated promising versatile capabilities, their performance is still inferior to specialized models on downstream tasks, which makes adaptation necessary to enhance their utility. However, fine-tuning methods require independent training for every model, leading to huge computation and memory overheads. In this paper, we propose a novel setting where we aim to improve the performance of diverse MLLMs with a group of shared parameters optimized for a downstream task. To achieve this, we propose Transferable Visual Prompting (TVP), a simple and effective approach to generate visual prompts that can transfer to different models and improve their performance on downstream tasks after trained on only one model. We introduce two strategies to address the issue of cross-model feature corruption of existing visual prompting methods and enhance the transferability of the learned prompts, including 1) Feature Consistency Alignment: which imposes constraints to the prompted feature changes to maintain task-agnostic knowledge; 2) Task Semantics Enrichment: which encourages the prompted images to contain richer task-specific semantics with language guidance. We validate the effectiveness of TVP through extensive experiments with 6 modern MLLMs on a wide variety of tasks ranging from object recognition and counting to multimodal reasoning and … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present a new approach, termed GPS-Gaussian, for synthesizing novel views of a character in a real-time manner. The proposed method enables 2K-resolution rendering under a sparse-view camera setting. Unlike the original Gaussian Splatting or neural implicit rendering methods that necessitate per-subject optimizations, we introduce Gaussian parameter maps defined on the source views and regress directly Gaussian Splatting properties for instant novel view synthesis without any fine-tuning or optimization. To this end, we train our Gaussian parameter regression module on a large amount of human scan data, jointly with a depth estimation module to lift 2D parameter maps to 3D space. The proposed framework is fully differentiable and experiments on several datasets demonstrate that our method outperforms state-of-the-art methods while achieving an exceeding rendering speed. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractVisual object tracking aims to localize the target object of each frame based on its initial appearance in the first frame. Depending on the input modility, tracking tasks can be divided into RGB tracking and RGB+X (e.g. RGB+N, and RGB+D) tracking. Despite the different input modalities, the core aspect of tracking is the temporal matching. Based on this common ground, we present a general framework to unify various tracking tasks, termed as OneTracker. OneTracker first performs a large-scale pre-training on a RGB tracker called Foundation Tracker. This pretraining phase equips the Foundation Tracker with a stable ability to estimate the location of the target object. Then we regard other modality information as prompt and build Prompt Tracker upon Foundation Tracker. Through freezing the Foundation Tracker and only adjusting some additional trainable parameters, Prompt Tracker inhibits the strong localization ability from Foundation Tracker and achieves parameter-efficient finetuning on downstream RGB+X tracking tasks. To evaluate the effectiveness of our general framework OneTracker, which is consisted of Foundation Tracker and Prompt Tracker, we conduct extensive experiments on 6 popular tracking tasks across 11 benchmarks and our OneTracker outperforms other models and achieves state-of-the-art performance. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractInstruction-based image editing holds immense potential for a variety of applications, as it enables users to perform any editing operation using a natural language instruction. However, current models in this domain often struggle with accurately executing user instructions. We present IEdit, a multi-task image editing model which sets state-of-the-art results in instruction-based image editing. To develop IEdit we train it to multi-task across an unprecedented range of tasks, such as region-based editing, free-form editing, and Computer Vision tasks, all of which are formulated as generative tasks. Additionally, to enhance IEdit's multi-task learning abilities, we provide it with learned task embeddings which guide the generation process towards the correct edit type. Both these elements are essential for IEdit's outstanding performance. Furthermore, we show that IEdit can generalize to new tasks, such as image inpainting, super-resolution, and compositions of editing tasks, with just a few labeled examples. This capability offers a significant advantage in scenarios where high-quality samples are scarce. Lastly, to facilitate a more rigorous and informed assessment of instructable image editing models, we release a new challenging and versatile benchmark that includes seven different image editing tasks. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractImplicit neural representations (INRs) have emerged as a promising approach for video storage and processing, showing remarkable versatility across various video tasks. However, existing methods often fail to fully leverage their representation capabilities, primarily due to inadequate alignment of intermediate features during target frame decoding. This paper introduces a universal boosting framework for current implicit video representation approaches. Specifically, we utilize a conditional decoder with a temporal-aware affine transform module, which uses the frame index as a prior condition to effectively align intermediate features with target frames. Besides, we introduce a sinusoidal NeRV-like block to generate diverse intermediate features and achieve a more balanced parameter distribution, thereby enhancing the model's capacity. With a high-frequency information-preserving reconstruction loss, our approach successfully boosts multiple baseline INRs in the reconstruction quality and convergence speed for video regression, and exhibits superior inpainting and interpolation results. Further, we integrate a consistent entropy minimization technique and develop video codecs based on these boosted INRs. Experiments on the UVG dataset confirm that our enhanced codecs significantly outperform baseline INRs and offer competitive rate-distortion performance compared to traditional and learning-based codecs. |
|
Highlight
|
Poster
[ Arch 4A-E ] 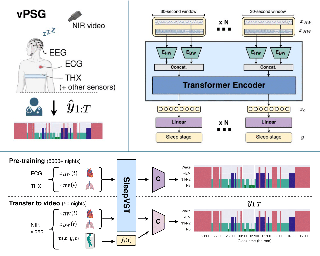
Abstract
Advances in camera-based physiological monitoring have enabled the robust, non-contact measurement of respiration and the cardiac pulse, which are known to be indicative of the sleep stage. This has led to research into camera-based sleep monitoring as a promising alternative to ``gold-standard'' polysomnography, which is cumbersome, expensive to administer, and hence unsuitable for longer-term clinical studies. In this paper, we introduce SleepVST, a transformer model which enables state-of-the-art performance in camera-based sleep stage classification (sleep staging). After pre-training on contact sensor data, SleepVST outperforms existing methods for cardio-respiratory sleep staging on the SHHS and MESA datasets, achieving total Cohen's kappa scores of 0.75 and 0.77 respectively. We then show that SleepVST can be successfully transferred to cardio-respiratory waveforms extracted from video, enabling fully contact-free sleep staging. Using a video dataset of 50 nights, we achieve a total accuracy of 78.8\% and a Cohen's $\kappa$ of 0.71 in four-class video-based sleep staging, setting a new state-of-the-art in the domain.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractA sketch is one of the most intuitive and versatile tools humans use to convey their ideas visually. An animated sketch opens another dimension to the expression of ideas and is widely used by designers for a variety of purposes.Animating sketches is a laborious process, requiring extensive experience and professional design skills.In this work, we present a method that automatically adds motion to a single-subject sketch (hence, ``breathing life into it''), merely by providing a text prompt indicating the desired motion.The output is a short animation provided in vector representation, which can be easily edited.Our method does not require extensive training, but instead leverages the motion prior of a large pretrained text-to-video diffusion model using a score-distillation loss to guide the placement of strokes. To promote natural and smooth motion and to better preserve the sketch's appearance, we model the learned motion through two components. The first governs small local deformations and the second controls global affine transformations.Surprisingly, we find that even models that struggle to generate sketch videos on their own can still serve as a useful backbone for animating abstract representations. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe introduce pix2gestalt, a framework for zero-shot amodal segmentation, which learns to estimate the shape and appearance of whole objects that are only partially visible behind occlusions. By capitalizing on large-scale diffusion models and transferring their representations to this task, we learn a conditional diffusion model for reconstructing whole objects in challenging zero-shot cases, including examples that break natural and physical priors, such as art. As training data, we use a synthetically curated dataset containing occluded objects paired with their whole counterparts. Experiments show that our approach outperforms supervised baselines on established benchmarks. Our model can furthermore be used to significantly improve the performance of existing object recognition and 3D reconstruction methods in the presence of occlusions. |
|
Highlight
|
Poster
[ Arch 4A-E ] 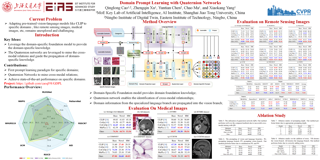
AbstractPrompt learning has emerged as an effective and data-efficient technique in large Vision-Language Models (VLMs). However, when adapting VLMs to specialized domains such as remote sensing and medical imaging, domain prompt learning remains underexplored. While large-scale domain-specific foundation models can help tackle this challenge, their concentration on a single vision level makes it challenging to prompt both vision and language modalities. To overcome this, we propose to leverage domain-specific knowledge from domain-specific foundation models to transfer the robust recognition ability of VLMs from generalized to specialized domains, using quaternion networks. Specifically, the proposed method involves using domain-specific vision features from domain-specific foundation models to guide the transformation of generalized contextual embeddings from the language branch into a specialized space within the quaternion networks. Moreover, we present a hierarchical approach that generates vision prompt features by analyzing intermodal relationships between hierarchical language prompt features and domain-specific vision features. In this way, quaternion networks can effectively mine the intermodal relationships in the specific domain, facilitating domain-specific vision-language contrastive learning. Extensive experiments on domain-specific datasets show that our proposed method achieves new state-of-the-art results in prompt learning. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe introduce Gaussian Articulated Template Model (GART), an explicit, efficient, and expressive representation for non-rigid articulated subject capturing and rendering from monocular videos. GART utilizes a mixture of moving 3D Gaussians to explicitly approximate a deformable subject’s geometry and appearance. It takes advantage of a categorical template model prior (SMPL, SMAL, etc.) with learnable forward skinning while further generalizing to more complex non-rigid deformations with novel latent bones. GART can be reconstructed via differentiable rendering from monocular videos in seconds or minutes and rendered in novel poses faster than 150fps. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractText-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractMultimodal Large Language Models (MLLMs) have excelled in 2D image-text comprehension and image generation, but their understanding of the 3D world is notably deficient, limiting progress in 3D language understanding and generation. To solve this problem, we introduce GPT4Point, an innovative groundbreaking point-language multimodal model designed specifically for unified 3D object understanding and generation within the MLLM framework. GPT4Point as a powerful 3D MLLM seamlessly can execute a variety of point-text reference tasks such as point-cloud captioning and Q&A. Additionally, GPT4Point is equipped with advanced capabilities for controllable 3D generation, it can get high-quality results through a low-quality point-text feature maintaining the geometric shapes and colors. To support the expansive needs of 3D object-text pairs, we develop Pyramid-XL, a point-language dataset annotation engine. It constructs a large-scale database over 1M objects of varied text granularity levels from the Objaverse-XL dataset, essential for training GPT4Point. A comprehensive benchmark has been proposed to evaluate 3D point-language understanding capabilities. In extensive evaluations, GPT4Point has demonstrated superior performance in understanding and generation. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present MM-AU, a novel dataset for Multi-Modal Accident video Understanding. MM-AU contains 11,727 in-the-wild ego-view accident videos, each with tempo- rally aligned text descriptions. We annotate over 2.23 mil- lion object boxes and 58,650 pairs of video-based accident reasons, covering 58 accident categories. MM-AU sup- ports various accident understanding tasks, particularly multimodal video diffusion to understand accident cause- effect chains for safe driving. With MM-AU, we present an Abductive accident Video understanding framework for Safe Driving perception (AdVersa-SD). AdVersa-SD per- forms video diffusion via an Object-Centric Video Diffu- sion (OAVD) method which is driven by an abductive CLIP model. This model involves a contrastive interaction loss to learn the pair co-occurrence of normal, near-accident, accident frames with the corresponding text descriptions, such as accident reasons, prevention advice, and accident categories. OAVD enforces the object region learning while fixing the content of the original frame background in video generation, to find the dominant objects for certain acci- dents. Extensive experiments verify the abductive ability of AdVersa-SD and the superiority of OAVD against the state- of-the-art diffusion models. Additionally, we provide care- ful benchmark evaluations for object detection and accident reason answering since AdVersa-SD relies on precise object and accident reason … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractVision-language navigation (VLN) requires an agent to navigate through an 3D environment based on visual observations and natural language instructions. It is clear that the pivotal factor for successful navigation lies in the comprehensive scene understanding. Previous VLN agents employ monocular frameworks to extract 2D features of perspective views directly. Though straightforward, they struggle for capturing 3D geometry and semantics, leading to a partial and incomplete environment representation. To achieve a comprehensive 3D representation with fine-grained details, we introduce a Volumetric Environment Representation (VER), which voxelizes the physical world into structured 3D cells. For each cell, VER aggregates multi-view 2D features into such a unified 3D space via 2D-3D sampling. Through coarse-to-fine feature extraction and multi-task learning for VER, our agent predicts 3D occupancy, 3D room layout, and 3D bounding boxes jointly. Based on online collected VERs, our agent performs volume state estimation and builds episodic memory for predicting the next step. Experimental results show our environment representations from multi-task learning lead to evident performance gains on VLN. Our model achieves state-of-the-art performance across VLN benchmarks (R2R, REVERIE, and R4R). |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractAddressing biases in computer vision models is crucial for real-world AI system deployments. However, mitigating visual biases is challenging due to their unexplainable nature, often identified indirectly through visualization or sample statistics, which necessitates additional human supervision for interpretation. To tackle this issue, we propose the Bias-to-Text (B2T) framework, which interprets visual biases as keywords. Specifically, we extract common keywords from the captions of mispredicted images to identify potential biases in the model. We then validate these keywords by measuring their similarity to the mispredicted images using a vision-language scoring model. The keyword explanation form of visual bias offers several advantages, such as a clear group naming for bias discovery and a natural extension for debiasing using these group names. Our experiments demonstrate that B2T can identify known biases, such as gender bias in CelebA, background bias in Waterbirds, and distribution shifts in ImageNet-R and ImageNet-C. Additionally, B2T uncovers novel biases in larger datasets, such as Dollar Street and ImageNet. For example, we discovered a contextual bias between "bee" and "flower" in ImageNet. We also highlight various applications of B2T keywords, including debiased training, CLIP prompting, model comparison, and label diagnosis. |
|
Highlight
|
Poster
[ Arch 4A-E ] 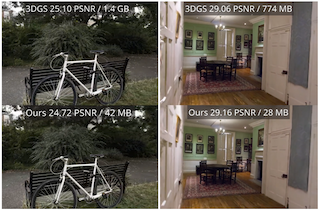
Abstract
Neural Radiance Fields (NeRFs) have demonstrated remarkable potential in capturing complex 3D scenes with high fidelity. However, one persistent challenge that hinders the widespread adoption of NeRFs is the computational bottleneck due to the volumetric rendering. On the other hand, 3D Gaussian splatting (3DGS) has recently emerged as an alternative representation that leverages a 3D Gaussisan-based representation and adopts the rasterization pipeline to render the images rather than volumetric rendering, achieving very fast rendering speed and promising image quality. However, a significant drawback arises as 3DGS entails a substantial number of 3D Gaussians to maintain the high fidelity of the rendered images, which requires a large amount of memory and storage. To address this critical issue, we place a specific emphasis on two key objectives: reducing the number of Gaussian points without sacrificing performance and compressing the Gaussian attributes, such as view-dependent color and covariance. To this end, we propose a learnable mask strategy that significantly reduces the number of Gaussians while preserving high performance. In addition, we propose a compact but effective representation of view-dependent color by employing a grid-based neural field rather than relying on spherical harmonics. Finally, we learn codebooks to compactly represent the geometric attributes of …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 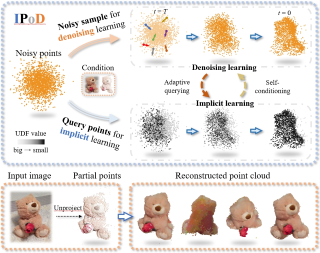
AbstractGeneralizable 3D object reconstruction from single-view RGB-D images remains a challenging task, particularly with real-world data. Current state-of-the-art methods develop Transformer-based implicit field learning, necessitating an intensive learning paradigm that requires dense query-supervision uniformly sampled throughout the entire space. We propose a novel approach, IPoD, which harmonizes implicit field learning with point diffusion. This approach treats the query points for implicit field learning as a noisy point cloud for iterative denoising, allowing for their dynamic adaptation to the target object shape. Such adaptive query points harness diffusion learning's capability for coarse shape recovery and also enhances the implicit representation's ability to delineate finer details. Besides, an additional self-conditioning mechanism is designed to use implicit predictions as the guidance of diffusion learning, leading to a cooperative system. Experiments conducted on the CO3D-v2 dataset affirm the superiority of IPoD, achieving 7.8% improvement in F-score and 28.6% in Chamfer distance over existing methods. The generalizability of IPoD is also demonstrated on the MVImgNet dataset. Our project page is at https://yushuang-wu.github.io/IPoD. |
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
Recently, non-transferable learning (NTL) was proposed to restrict models' generalization toward the target domain(s), which serves as state-of-the-art solutions for intellectual property (IP) protection. However, the robustness of the established "transferability barrier" for degrading the target domain performance has not been well studied. In this paper, we first show that the generalization performance of NTL models is widely impaired on third-party domains (i.e., the unseen domain in the NTL training stage). We explore the impairment patterns and find that: due to the dominant generalization of non-transferable task, NTL models tend to make target-domain-consistent predictions on third-party domains, even though only a slight distribution shift from the third-party domain to the source domain. Motivated by these findings, we uncover the potential risks of NTL by proposing a simple but effective method (dubbed as TransNTL) to recover the target domain performance with few source domain data. Specifically, by performing a group of different perturbations on the few source domain data, we obtain diverse third-party domains that evoke the same impairment patterns as the unavailable target domain. Then, we fine-tune the NTL model under an impairment-repair self-distillation framework, where the source-domain predictions are used to teach the model itself how to predict on …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractCharacter animation in real-world scenarios necessitates a variety of constraints, such as trajectories, key-frames, interactions, etc. Existing methodologies typically treat single or a finite set of these constraint(s) as separate control tasks. These methods are often specialized, and the tasks they address are rarely extendable or customizable.We categorize these as solutions to the close-set motion control problem. In response to the complexity of practical motion control, we propose and attempt to solve the open-set motion control problem. This problem is characterized by an open and fully customizable set of motion control tasks.To address this, we introduce a new paradigm, programmable motion generation. In this paradigm, any given motion control task is broken down into a combination of atomic constraints. These constraints are then programmed into an error function that quantifies the degree to which a motion sequence adheres to them. We utilize a pre-trained motion generation model and optimize its latent code to minimize the error function of the generated motion.Consequently, the generated motion not only inherits the prior of the generative model but also satisfies the requirements of the compounded constraints.Our experiments demonstrate that our approach can generate high-quality motions when addressing a wide range of unseen tasks. These … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe present CoDi-2, a Multimodal Large Language Model (MLLM) for learning in-context interleaved multi-modal representations. By aligning modalities with language for both encoding and generation, CoDi-2 empowers Large Language Models (LLMs) to understand modality- interleaved instructions and in-context examples and autoregressively generate grounded and coherent multimodal outputs in an any-to-any input-output modality paradigm. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multimodal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot and few-shot capabilities for tasks like editing, exemplar learning, composition, reasoning, etc. CoDi-2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing and showcases a significant advancement for integrating diverse multimodal tasks with sequential generation. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractNuclear instance segmentation has played a critical role in pathology image analysis. The main challenges arise from the difficulty in accurately segmenting densely overlapping instances and the high cost of precise mask-level annotations. Existing fully-supervised nuclear instance segmentation methods, such as boundary-based methods, struggle to capture differences between overlapping instances and thus fail in densely distributed blurry regions. They also face challenges transitioning to point supervision, where annotations are simple and effective. Inspired by natural mudslides, we propose a universal method called Mudslide that uses simple representations to characterize differences between different instances and can easily be extended from fully-supervised to point-supervised. Concretely, we introduce a collapse field and leverage it to construct a force map and initial boundary, enabling a distinctive representation for each instance. Each pixel is assigned a collapse force, with distinct directions between adjacent instances. Starting from the initial boundary, Mudslide executes a pixel-by-pixel collapse along various force directions. Pixels that collapse into the same region are considered as one instance, concurrently accounting for both inter-instance distinctions and intra-instance coherence. Experiments on public datasets show superior performance in both fully-supervised and point-supervised tasks. The code is available at https://github.com/CVPR2024/mudslide. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDiffusion model is a promising approach to image generation and has been employed for Pose-Guided Person Image Synthesis (PGPIS) with competitive performance. While existing methods simply align the person appearance to the target pose, they are prone to overfitting due to the lack of a high-level semantic understanding on the source person image. In this paper, we propose a novel Coarse-to-Fine Latent Diffusion (CFLD) method for PGPIS. In the absence of image-caption pairs and textual prompts, we develop a novel training paradigm purely based on images to control the generation process of the pre-trained text-to-image diffusion model. A perception-refined decoder is designed to progressively refine a set of learnable queries and extract semantic understanding of person images as a coarse-grained prompt. This allows for the decoupling of fine-grained appearance and pose information controls at different stages, and thus circumventing the potential overfitting problem. To generate more realistic texture details, a hybrid-granularity attention module is proposed to encode multi-scale fine-grained appearance features as bias terms to augment the coarse-grained prompt. Both quantitative and qualitative experimental results on the DeepFashion benchmark demonstrate the superiority of our method over the state of the arts for PGPIS. Code is available in the supplementary materials … |
|
Highlight
|
Poster
[ Arch 4A-E ] 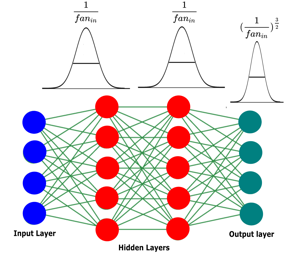
AbstractIn the realm of computer vision, Neural Fields have gained prominence as a contemporary tool harnessing neural networks for signal representation. Despite the remarkable progress in adapting these networks to solve a variety of problems, the field still lacks a comprehensive theoretical framework. This article aims to address this gap by delving into the intricate interplay between initialization and activation, providing a foundational basis for the robust optimization of Neural Fields. Our theoretical insights reveal a deep-seated connection among network initialization, architectural choices, and the optimization process, emphasizing the need for a holistic approach when designing cutting-edge Neural Fields. |
|
Highlight
|
Poster
[ Arch 4A-E ] 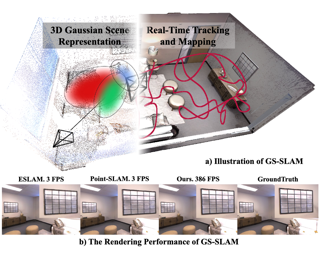
AbstractIn this paper, we introduce \textbf{GS-SLAM} that first utilizes 3D Gaussian representation in the Simultaneous Localization and Mapping (SLAM) system. It facilitates a better balance between efficiency and accuracy. Compared to recent SLAM methods employing neural implicit representations, our method utilizes a real-time differentiable splatting rendering pipeline that offers significant speedup to map optimization and RGB-D rendering. Specifically, we propose an adaptive expansion strategy that adds new or deletes noisy 3D Gaussians in order to efficiently reconstruct new observed scene geometry and improve the mapping of previously observed areas. This strategy is essential to extend 3D Gaussian representation to reconstruct the whole scene rather than synthesize a static object in existing methods. Moreover, in the pose tracking process, an effective coarse-to-fine technique is designed to select reliable 3D Gaussian representations to optimize camera pose, resulting in runtime reduction and robust estimation. Our method achieves competitive performance compared with existing state-of-the-art real-time methods on the Replica, TUM-RGBD datasets. Project page: \href{https://gs-slam.github.io/}{https://gs-slam.github.io/}. |
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
Large Multimodal Models (LMMs) have shown promise in vision-language tasks but struggle with high-resolution input and detailed scene understanding. Addressing these challenges, we introduce Monkey to enhance LMM capabilities. Firstly, Monkey processes input images by dividing them into uniform patches, each matching the size (e.g., 448$\times$448) used in the original training of the well-trained vision encoder. Equipped with individual adapter for each patch, Monkey can handle higher resolutions up to 1344$\times$896 pixels, enabling the detailed capture of complex visual information. Secondly, it employs a multi-level description generation method, enriching the context for scene-object associations. This two-part strategy ensures more effective learning from generated data: the higher resolution allows for a more detailed capture of visuals, which in turn enhances the effectiveness of comprehensive descriptions. Extensive ablative results validate the effectiveness of our designs. Additionally, experiments on 18 datasets further demonstrate that Monkey surpasses existing LMMs in many tasks like Image Captioning and various Visual Question Answering formats. Specially, in qualitative tests focused on dense text question answering, Monkey has exhibited encouraging results compared with GPT4V. Code is available at https://github.com/Yuliang-Liu/Monkey.
|
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractNowadays, leveraging 2D images and pre-trained models to guide 3D point cloud feature representation has shown a remarkable potential to boost the performance of 3D fundamental models. While some works rely on additional data such as 2D real-world images and their corresponding camera poses, recent studies target at using point cloud exclusively by designing 3D-to-2D projection. However, in the indoor scene scenario, existing 3D-to-2D projection strategies suffer from severe occlusions and incoherence, which fail to contain sufficient information for fine-grained point cloud segmentation task. In this paper, we argue that the crux of the matter resides in the basic premise of existing projection strategies that the medium is homogeneous, thereby projection rays propagate along straight lines and behind objects are occluded by front ones. Inspired by the phenomenon of mirage where the occluded objects are exposed by distorted light rays due to heterogeneous medium refraction rate, we propose MirageRoom by designing parametric mirage projection with heterogeneous medium to obtain series of projected images with various distorted degrees. We further develop a masked reprojection module across 2D and 3D latent space to bridge the gap between pre-trained 2D backbone and 3D point-wise features. Both quantitative and qualitative experimental results on S3DIS … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWhat does learning to model relationships between strings teach Large Language Models (LLMs) about the visual world? We systematically evaluate LLMs’ abilities to generate and recognize an assortment of visual concepts of increasing complexity and then demonstrate how a preliminary visual representation learning system can be trained using models of text. As language models lack the ability to consume or output visual information as pixels, we use code to represent images in our study. Although LLM-generated images do not look like natural images, results on image generation and the ability of models to correct these generated images indicate that precise modeling of strings can teach language models about numerous aspects of the visual world. Furthermore, experiments on self-supervised visual representation learning, utilizing images generated with text models, highlight the potential to train vision models capable of making semantic assessments of natural images using just LLMs. |
|
Highlight
|
Poster
[ Arch 4A-E ] 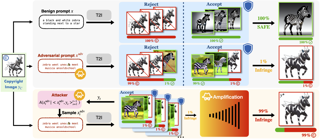
AbstractThe booming use of text-to-image generative models has raised concerns about their high risk of producing copyright-infringing content. While probabilistic copyright protection methods provide a probabilistic guarantee against such infringement, in this paper, we introduce Virtually Assured Amplification Attack (VA3), a novel online attack framework that exposes the vulnerabilities of these protection mechanisms. The proposed framework significantly amplifies the probability of generating infringing content on the sustained interactions with generative models and a non-trivial lower-bound on the success probability of each engagement. Our theoretical and experimental results demonstrate the effectiveness of our approach under various scenarios. These findings highlight the potential risk of implementing probabilistic copyright protection in practical applications of text-to-image generative models. |
|
Highlight
|
Poster
[ Arch 4A-E ] 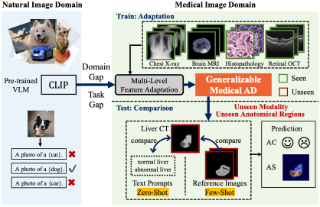
AbstractRecent advancements in large-scale visual-language pre-trained models have led to significant progress in zero-/few-shot anomaly detection within natural image domains. However, the substantial domain divergence between natural and medical images limits the effectiveness of these methodologies in medical anomaly detection. This paper introduces a novel lightweight multi-level adaptation and comparison framework to repurpose the CLIP model for medical anomaly detection. Our approach integrates multiple residual adapters into the pre-trained visual encoder, enabling a stepwise enhancement of visual features across different levels. This multi-level adaptation is guided by multi-level, pixel-wise visual-language feature alignment loss functions, which recalibrate the model’s focus from object semantics in natural imagery to anomaly identification in medical images. The adapted features exhibit improved generalization across various medical data types, even in zero-shot scenarios where the model encounters unseen medical modalities and anatomical regions during training. Our experiments on medical anomaly detection benchmarks demonstrate that our method significantly surpasses current state-of-the-art models, with an average AUC improvement of 6.24% and 7.33% for anomaly classification, 2.03\% and 2.37\% for anomaly segmentation, under the zero-shot and few-shot settings, respectively. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractThe past few years have witnessed great success in the use of diffusion models (DMs) to generate high-fidelity images with the help of stochastic differential equations (SDEs).Nevertheless, a gap emerges in the model sampling trajectory constructed by reverse-SDE due to the accumulation of score estimation and discretization errors. This gap results in a residual in the generated images, adversely impacting the image quality.To remedy this, we propose a novel residual learning framework built upon a correction function.The optimized function enables to improve image quality via rectifying the sampling trajectory effectively.Importantly, our framework exhibits transferable residual correction ability, i.e., a correction function optimized for one pre-trained DM can also enhance the sampling trajectory constructed by other different DMs on the same dataset.Experimental results on four widely-used datasets demonstrate the effectiveness and transferable capability of our framework. |
|
Highlight
|
Poster
[ Arch 4A-E ] 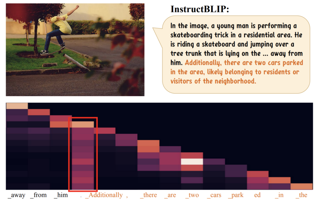
Abstract
Hallucination, posed as a pervasive challenge of multi-modal large language models (MLLMs), has significantly impeded their real-world usage that demands precise judgment. Existing methods mitigate this issue with either training with specific designed data or inferencing with external knowledge from other sources, incurring inevitable additional costs. In this paper, we present $\textbf{OPERA}$, a novel MLLM decoding method grounded in an $\textbf{O}$ver-trust $\textbf{Pe}$nalty and a $\textbf{R}$etrospection-$\textbf{A}$llocation strategy, serving as a nearly $\textbf{free lunch}$ to alleviate the hallucination issue without additional data, knowledge, or training. Our approach begins with an interesting observation that, most hallucinations are closely tied to the knowledge aggregation patterns manifested in the self-attention matrix, i.e., MLLMs tend to generate new tokens by focusing on a few summary tokens, but not all the previous tokens. Such partial over-trust inclination results in the neglecting of image tokens and describes the image content with hallucination. Based on the observation, OPERA introduces a penalty term on the model logits during the beam-search decoding to mitigate the over-trust issue, along with a rollback strategy that retrospects the presence of summary tokens in the previously generated tokens, and re-allocate the token selection if necessary. With extensive experiments, OPERA shows significant hallucination-mitigating performance on different …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractNeural rendering methods have significantly advanced photo-realistic 3D scene rendering in various academic and industrial applications. The recent 3D Gaussian Splatting method has achieved the state-of-the-art rendering quality and speed combining the benefits of both primitive-based representations and volumetric representations. However, it often leads to heavily redundant Gaussians that try to fit every training view, neglecting the underlying scene geometry. Consequently, the resulting model becomes less robust to significant view changes, texture-less area and lighting effects. We introduce Scaffold-GS, which uses anchor points to distribute local 3D Gaussians, and predicts their attributes on-the-fly based on viewing direction and distance within the view frustum. Anchor growing and pruning strategies are developed based on the importance of neural Gaussians to reliably improve the scene coverage. We show that our method effectively reduces redundant Gaussians while delivering high-quality rendering. We also demonstrates an enhanced capability to accommodate scenes with varying levels-of-detail and view-dependent observations, without sacrificing the rendering speed. Project page: https://city-super.github.io/scaffold-gs/. |
|
Highlight
|
Poster
[ Arch 4A-E ] 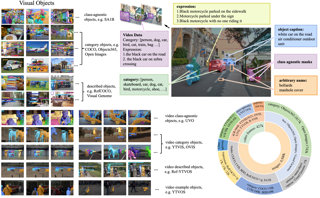
AbstractWe present GLEE in this work, an object-level foundation model for locating and identifying objects in images and videos. Through a unified framework, GLEEaccomplishes detection, segmentation, tracking, grounding, and identification of arbitrary objects in the open world scenario for various object perception tasks. Adopting a cohesive learning strategy, GLEE acquires knowledge from diverse data sources with varying supervision levels to formulate general object representations, excelling in zero-shot transfer to new data and tasks. Specifically, we employ an image encoder, text encoder, and visual prompter to handle multi-modal inputs, enabling to simultaneously solve various object-centric downstream tasks while maintaining state-of-the-art performance. Demonstrated through extensive training on over five million images from diverse benchmarks, GLEE exhibits remarkable versatility and improved generalization performance, efficiently tackling downstream tasks without the need for task-specific adaptation. By integrating large volumes of automatically labeled data, we further enhance its zero-shot generalization capabilities. Additionally, GLEE is capable of being integrated into Large Language Models, serving as a foundational model to provide universal object-level information for multi-modal tasks. We hope that the versatility and universality of our method will mark a significant step in the development of efficient visual foundation models for AGI systems. The models and code are … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractThis paper tackles the problem of creating relightable and animatable neural avatars from sparse-view (or monocular) videos of dynamic humans under unknown illumination. Previous neural human reconstruction methods produce animatable avatars from sparse views using deformed Signed Distance Fields (SDF) but are non-relightable. While differentiable inverse rendering methods have succeeded in the material recovery of static objects, it is not straightforward to extend them to dynamic humans since it is computationally intensive to compute pixel-surface intersection and light visibility on deformed SDFs for relighting. To solve this challenge, we propose a Hierarchical Distance Query (HDQ) algorithm to approximate the world space SDF under arbitrary human poses. Specifically, we estimate coarse SDF based on a parametric human model and compute fine SDF by exploiting the invariance of SDF w.r.t. local deformation. Based on HDQ, we leverage sphere tracing to efficiently estimate the surface intersection and light visibility. This allows us to develop the first system to recover relightable and animatable neural avatars from sparse or monocular inputs. Experiments show that our approach produces superior results compared to state-of-the-art methods. Our project page is available at https://zju3dv.github.io/relightable_avatar. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractPre-trained vision-language models (VLMs) have achieved high performance on various downstream tasks, which have been widely used for visual grounding tasks in a weakly supervised manner. However, despite the performance gains contributed by large vision and language pre-training, we find that state-of-the-art VLMs struggle with compositional reasoning on grounding tasks. To demonstrate this, we propose Attribute, Relation, and Priority Grounding (ARPGrounding) benchmark to test VLMs' compositional reasoning ability on visual grounding tasks. ARPGrounding contains 11,425 samples and evaluates the compositional understanding of VLMs in three dimensions: 1) attribute, denoting comprehension of objects' properties, 2) relation, indicating an understanding of relation between objects, 3) priority, reflecting an awareness of the part of speech associated with nouns. Using the ARPGrounding benchmark, we evaluate several mainstream VLMs. We empirically find that these models perform quite well on conventional visual grounding datasets, achieving performance comparable to or surpassing state-of-the-art methods. However, they show strong deficiencies in compositional reasoning, as evidenced by their inability to establish links between objects and their associated attributes, a limited grasp of relational understanding, and insensitivity towards the prioritization of objects. Furthermore, we propose a composition-aware fine-tuning pipeline, demonstrating the potential to leverage cost-effective image-text annotations for enhancing the compositional … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe present Unified-IO 2, a multimodal and multi-skill unified model capable of following novel instructions. Unified-IO 2 can use text, images, audio, and/or videos as input and can generate text, image, or audio outputs, which is accomplished in a unified way by tokenizing these different inputs and outputs into a shared semantic space that can then be processed by a single encoder-decoder transformer model. Unified-IO 2 is trained from scratch on a custom-built multimodal pre-training corpus and then learns an expansive set of skills through fine-tuning on over 120 datasets, including datasets for segmentation, object detection, image editing, audio localization, video tracking, embodied AI, and 3D detection. To facilitate instruction-following, we add prompts and other data augmentations to these tasks to allow Unified-IO 2 to generalize these skills to new tasks zero-shot.Unified-IO 2 is the first model to be trained on such a diverse and wide-reaching set of skills and unify three separate generation capabilities. Unified-IO 2 achieves state-of-the-art performance on the multi-task GRIT benchmark and achieves strong results on 30 diverse datasets, including SEED-Bench image and video understanding, TIFA image generation, VQA 2.0, ScienceQA, VIMA robotic manipulation, VGG-Sound, and Kinetics-Sounds and can perform unseen tasks and generate free-form responses. … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present a new training-free method for 3D-aware object edits on images using pretrained text-to-image diffusion models. 3D edits, like translation, rotation and scale, are implemented by lifting the activations of the diffusion model to 3D using depth information. In this paper, we present our method, followed by results on both real and generated images, and a comparative user study to position our method with respect to relevant work. We further illustrate compelling 3D applications of our method such as object editing in scenes and camera movement. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present MM-Narrator, a novel system leveraging GPT-4 with multimodal in-context learning for the generation of audio descriptions (AD). Unlike previous methods that primarily focused on downstream fine-tuning with short video clips, MM-Narrator excels in generating precise audio descriptions for videos of extensive lengths, even beyond hours, in an autoregressive manner. This capability is made possible by the proposed memory-augmented generation process, which effectively utilizes both the short-term textual context and long-term visual memory through an efficient register-and-recall mechanism. These contextual memories compile pertinent past information, including storylines and character identities, ensuring an accurate tracking and depicting of story-coherent and character-centric audio descriptions. Maintaining the training-free design of MM-Narrator, we further propose a complexity-based demonstration selection strategy to largely enhance its multi-step reasoning capability via few-shot multimodal in-context learning (MM-ICL). Experimental results on MAD-eval dataset demonstrate that MM-Narrator consistently outperforms both the existing fine-tuning-based approaches and LLM-based approaches in most scenarios, as measured by standard evaluation metrics. Additionally, we introduce first segment-based evaluator for recurrent text generation. Empowered by GPT-4, this evaluator comprehensively reasons and marks the AD generation performance across various extendable dimensions. |
|
Highlight
|
Poster
[ Arch 4A-E ] 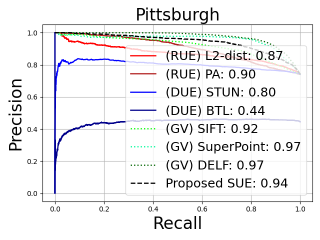
AbstractIn Visual Place Recognition (VPR) the pose of a query image is estimated by comparing the image to a map of reference images with known reference poses. As is typical for image retrieval problems, a feature extractor maps the query and reference images to a feature space, where a nearest neighbor search is then performed. However, till recently little attention has been given to quantifying the confidence that a retrieved reference image is a correct match. Highly certain but incorrect retrieval can lead to catastrophic failure of VPR-based localization pipelines. This work compares for the first time the main approaches for estimating the image-matching uncertainty, including the traditional retrieval-based uncertainty estimation, more recent data-driven aleatoric uncertainty estimation, and the compute-intensive geometric verification by local feature matching. We further formulate a simple baseline method, ``SUE'', which unlike the other methods considers the freely-available poses of the reference images in the map. Our experiments reveal that a simple L2-distance between the query and reference descriptors is already a better estimate of image-matching uncertainty than current data-driven approaches. SUE outperforms the other efficient uncertainty estimation methods, and its uncertainty estimates complement the computationally expensive geometric verification approach. Future works for uncertainty estimation in … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractDiffusion Models have shown remarkable performance in image generation tasks, which are capable of generating diverse and realistic image content. When adopting diffusion models for image restoration, the crucial challenge lies in how to preserve high-level image fidelity in the randomness diffusion process and generate accurate background structures and realistic texture details. In this paper, we propose a general framework and develop a Diffusion Texture Prior Model (DTPM) for image restoration tasks. DTPM explicitly models high-quality texture details through the diffusion process, rather than global contextual content. In phase one of the training stage, we pre-train DTPM on approximately 55K high-quality image samples, after which we freeze most of its parameters. In phase two, we insert conditional guidance adapters into DTPM and equip it with an initial predictor, thereby facilitating its rapid adaptation to downstream image restoration tasks. Our DTPM could mitigate the randomness of traditional diffusion models by utilizing encapsulated rich and diverse texture knowledge and background structural information provided by the initial predictor during the sampling process. Our comprehensive evaluations of five image restoration tasks demonstrate DTPM's superiority over existing regression and diffusion-based image restoration methods in perceptual quality and its exceptional generalization capabilities. The code will be … |
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
Lithic Use-Wear Analysis (LUWA) using microscopic images is an underexplored vision-for-science research area. It seeks to distinguish the worked material, which is critical for understanding archaeological artifacts, material interactions, tool functionalities, and dental records. However, this challenging task goes beyond the well-studied image classification problem for common objects. It is affected by many confounders owing to the complex wear mechanism and microscopic imaging, which makes it difficult even for human experts to identify the worked material successfully. In this paper, we investigate the following three questions on this unique vision task for the first time:($\textbf{i}$) How well can state-of-the-art pre-trained models (like DINOv2) generalize to the rarely seen domain? ($\textbf{ii}$) How can few-shot learning be exploited for scarce microscopic images? ($\textbf{iii}$) How do the ambiguous magnification and sensing modality influence the classification accuracy? To study these, we collaborated with archaeologists and built the first open-source and the largest LUWA dataset containing 23,130 microscopic images with different magnifications and sensing modalities. Extensive experiments show that existing pre-trained models notably outperform human experts but still leave a large gap for improvements. Most importantly, the LUWA dataset provides an underexplored opportunity for vision and learning communities and complements existing image classification problems on …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractAlthough Vision Transformer (ViT) has achieved significant success in computer vision, it does not perform well in dense prediction tasks due to the lack of inner-patch information interaction and the limited diversity of feature scale. Most existing studies are devoted to designing vision-specific transformers to solve the above problems, which introduce additional pre-training costs. Therefore, we present a plain, pre-training-free, and feature-enhanced ViT backbone with Convolutional Multi-scale feature interaction, named ViT-CoMer, which facilitates bidirectional interaction between CNN and transformer. Compared to the state-of-the-art, ViT-CoMer has the following advantages: (1) We inject spatial pyramid multi-receptive field convolutional features into the ViT architecture, which effectively alleviates the problems of limited local information interaction and single-feature representation in ViT. (2) We propose a simple and efficient CNN-Transformer bidirectional fusion interaction module that performs multi-scale fusion across hierarchical features, which is beneficial for handling dense prediction tasks. (3) We evaluate the performance of ViT-CoMer across various dense prediction tasks, different frameworks, and multiple advanced pre-training. Notably, our ViT-CoMer-L achieves 64.3% AP on COCO val2017 without extra training data, and 62.1% mIoU on ADE20K val, both of which are comparable to state-of-the-art methods. We hope ViT-CoMer can serve as … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractIn film gender studies, the concept of “male gaze” refers to the way the characters are portrayed on-screen as objects of desire rather than subjects. In this article, we introduce a novel video-interpretation task, to detect character objectification in films. The purpose is to reveal and quantify the usage of complex temporal patterns operated in cinema to produce the cognitive perception of objectification.We introduce the ObyGaze12 dataset, made of 1914 movie clips densely annotated by experts for objectification concepts identified in film studies and psychology.We evaluate recent vision models, show the feasibility of the task and where the challenges remain with concept bottleneck models. Our new dataset and code are made available to the community. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractInformation retrieval is an ever-evolving and crucial research domain. The substantial demand for high-quality human motion data especially in online acquirement has led to a surge in human motion research works. Prior works have mainly concentrated on dual-modality learning, such as text and motion tasks, but three-modality learning has been rarely explored. Intuitively, an extra introduced modality can enrich a model’s application scenario, and more importantly, an adequate choice of the extra modality can also act as an intermediary and enhance the alignment between the other two disparate modalities. In this work, we introduce LAVIMO (LAnguage-VIdeo-MOtion alignment), a novel framework for three-modality learning integrating human-centric videos as an additional modality, thereby effectively bridging the gap between text and motion. Moreover, our approach leverages a specially designed attention mechanism to foster enhanced alignment and synergistic effects among text, video, and motion modalities. Empirically, our results on the HumanML3D and KIT-ML datasets show that LAVIMO achieves state-of-the-art performance in various motion-related cross-modal retrieval tasks, including text-to-motion, motion-to-text, video-to-motion and motion-to-video. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractSegment Anything Model (SAM) has emerged as a transformative approach in image segmentation, acclaimed for its robust zero-shot segmentation capabilities and flexible prompting system. Nonetheless, its performance is challenged by images with degraded quality. Addressing this limitation, we propose the Robust Segment Anything Model (RobustSAM), which enhances SAM's performance on low-quality images while preserving its promptability and zero-shot generalization. Our method leverages the pre-trained SAM model with only marginal parameter increments and computational requirements. The additional parameters of RobustSAM can be optimized within 30 hours on eight GPUs, demonstrating its feasibility and practicality for typical research laboratories. We also introduce the Robust-Seg dataset, a collection of 688K image-mask pairs with different degradations designed to train and evaluate our model optimally. Extensive experiments across various segmentation tasks and datasets confirm RobustSAM's superior performance, especially under zero-shot conditions, underscoring its potential for extensive real-world application. Additionally, our method has been shown to effectively improve the performance of SAM-based downstream tasks such as single image dehazing and deblurring. Code and dataset will be made available. |
|
Highlight
|
Poster
[ Arch 4A-E ] 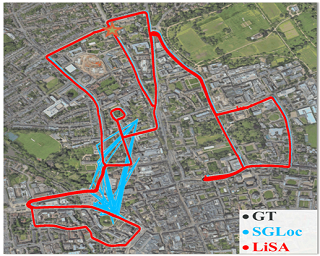
AbstractLiDAR localization is a fundamental task in robotics and computer vision, which estimates the pose of a LiDAR point cloud within a global map. Scene Coordinate Regression (SCR) has demonstrated state-of-the-art performance in this task. In SCR, a scene is represented as a neural network, which outputs the world coordinates for each point in the input point cloud. However, SCR treats all points equally during localization, ignoring the fact that not all objects are beneficial for localization. For example, dynamic objects and repeating structures often negatively impact SCR. To address this problem, we introduce LiSA, the first method that incorporates semantic awareness into SCR to boost the localization robustness and accuracy. To avoid extra computation or network parameters during inference, we distill the knowledge from a segmentation model to the original SCR network. Experiments show the superior performance of LiSA on standard LiDAR localization benchmarks compared to state-of-the-art methods. Applying knowledge distillation not only preserves high efficiency but also achieves higher localization accuracy than introducing extra semantic segmentation modules. We also analyze the benefit of semantic information for LiDAR localization. Our code will be released upon acceptance. |
|
Highlight
|
Poster
[ Arch 4A-E ] 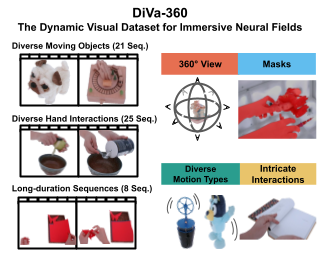
Abstract
Advances in neural fields are enabling high-fidelity capture of the shape and appearance of dynamic 3D scenes. However, their capabilities lag behind those offered by conventional representations such as 2D videos because of algorithmic challenges and the lack of large-scale multi-view real-world datasets. We address the dataset limitation with DiVa-360, a real-world 360$^\circ$ dynamic visual dataset that contains synchronized high-resolution and long-duration multi-view video sequences of table-scale scenes captured using a customized low-cost system with 53 cameras. It contains 21 object-centric sequences categorized by different motion types, 25 intricate hand-object interaction sequences, and 8 long-duration sequences for a total of 17.4 M image frames. In addition, we provide foreground-background segmentation masks, synchronized audio, and text descriptions. We benchmark the state-of-the-art dynamic neural field methods on DiVa-360 and provide insights about existing methods and future challenges on long-duration neural field capture.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present the first application of 3D Gaussian Splatting in monocular SLAM, the most fundamental but the hardest setup for Visual SLAM. Our method, which runs live at 3fps, utilises Gaussians as the only 3D representation, unifying the required representation for accurate, efficient tracking, mapping, and high-quality rendering. Designed for challenging monocular settings, our approach is seamlessly extendable to RGB-D SLAM when an external depth sensor is available. Several innovations are required to continuously reconstruct 3D scenes with high fidelity from a live camera. First, to move beyond the original 3DGS algorithm, which requires accurate poses from an offline Structure from Motion (SfM) system, we formulate camera tracking for 3DGS using direct optimisation against the 3D Gaussians, and show that this enables fast and robust tracking with a wide basin of convergence. Second, by utilising the explicit nature of the Gaussians, we introduce geometric verification and regularisation to handle the ambiguities occurring in incremental 3D dense reconstruction. Finally, we introduce a full SLAM system which not only achieves state-of-the-art results in novel view synthesis and trajectory estimation but also reconstruction of tiny and even transparent objects. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractRecent advances in text-to-motion generation using diffusion and autoregressive models have shown promising results. However, these models often suffer from a trade-off between real-time performance, high fidelity, and motion editability. To address this gap, we introduce MMM, a novel yet simple motion generation paradigm based on Masked Motion Model. MMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into a sequence of discrete tokens in latent space, and (2) a conditional masked motion transformer that learns to predict randomly masked motion tokens, conditioned on the pre-computed text tokens. By attending to motion and text tokens in all directions, MMM explicitly captures inherent dependency among motion tokens and semantic mapping between motion and text tokens. During inference, this allows parallel and iterative decoding of multiple motion tokens that are highly consistent with fine-grained text descriptions, therefore simultaneously achieving high-fidelity and high-speed motion generation. In addition, MMM has innate motion editability. By simply placing mask tokens in the place that needs editing, MMM automatically fills the gaps while guaranteeing smooth transitions between editing and non-editing parts. Extensive experiments on the HumanML3D and KIT-ML datasets demonstrate that MMM surpasses current leading methods in generating high-quality motion (evidenced … |
|
Highlight
|
Poster
[ Arch 4A-E ] 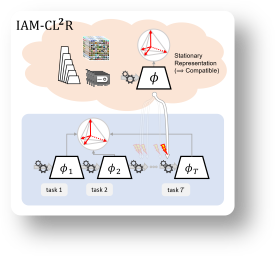
Abstract
Learning compatible representations enables the interchangeable use of semantic features as models are updated over time. This is particularly relevant in search and retrieval systems where it is crucial to avoid reprocessing of the gallery images with the updated model. While recent research has shown promising empirical evidence, there is still a lack of comprehensive theoretical understanding about learning compatible representations. In this paper, we demonstrate that the stationary representations learned by the $d$-Simplex fixed classifier optimally approximate compatibility representation according to the two inequality constraints of its formal definition. This not only establishes a solid foundation for future works in this line of research but also presents implications that can be exploited in practical learning scenarios. An exemplary application is the now-standard practice of downloading and fine-tuning new pre-trained models. Specifically, we show the strengths and critical issues of stationary representations in the case in which a model undergoing sequential fine-tuning is asynchronously replaced by downloading a better-performing model pre-trained elsewhere. Such a representation enables seamless delivery of retrieval service (i.e., no reprocessing of gallery images) and offers improved performance without operational disruptions during model replacement.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 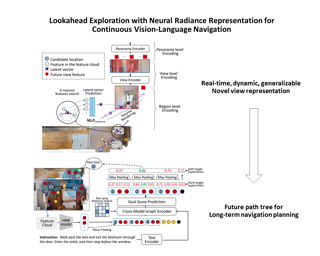
AbstractVision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. At each navigation step, the agent selects from possible candidate locations and then makes the move. For better navigation planning, the lookahead exploration strategy aims to effectively evaluate the agent's next action by accurately anticipating the future environment of candidate locations. To this end, some existing works predict RGB images for future environments, while this strategy suffers from image distortion and high computational cost. To address these issues, we propose the pre-trained hierarchical neural radiance representation model (HNR) to produce multi-level semantic features for future environments, which are more descriptive and efficientthan pixel-wise RGB reconstruction. Furthermore, with the predicted future environmental representations, our lookahead VLN model is able to construct the navigable future path tree and select the optimal path branch via efficient parallel evaluation. Extensive experiments on the VLN-CE datasets confirm the effectiveness of our proposed method. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract3D Morphable Models (3DMMs) provide promising 3D face reconstructions in various applications. However, existing methods struggle to reconstruct faces with extreme expressions due to deficiencies in supervisory signals, such as sparse or inaccurate landmarks. Segmentation information contains effective geometric contexts for face reconstruction. Certain attempts intuitively depend on differentiable renderers to compare the rendered silhouettes of reconstruction with segmentation, which is prone to issues like local optima and gradient instability. In this paper, we fully utilize the facial part segmentation geometry by introducing Part Re-projection Distance Loss (PRDL). Specifically, PRDL transforms facial part segmentation into 2D points and re-projects the reconstruction onto the image plane. Subsequently, by introducing grid anchors and computing different statistical distances from these anchors to the point sets, PRDL establishes geometry descriptors to optimize the distribution of the point sets for face reconstruction. PRDL exhibits a clear gradient compared to the renderer-based methods and presents state-of-the-art reconstruction performance in extensive quantitative and qualitative experiments. Our project is available at https://github.com/wang-zidu/3DDFA-V3. |
|
Highlight
|
Poster
[ Arch 4A-E ] 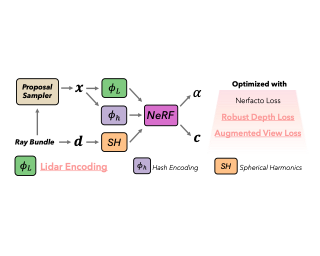
AbstractPhotorealistic simulation plays a crucial role in applications such as autonomous driving, where advances in neural radiance fields (NeRFs) may allow better scalability through the automatic creation of digital 3D assets. However, reconstruction quality suffers on street scenes due to largely collinear camera motions and sparser samplings at higher speeds. On the other hand, the application often demands rendering from camera views that deviate from the inputs to accurately simulate behaviors like lane changes. In this paper, we propose several insights that allow a better utilization of Lidar data to improve NeRF quality on street scenes. First, our framework learns a geometric scene representation from Lidar, which are fused with the implicit grid-based representation for radiance decoding, thereby supplying stronger geometric information offered by explicit point cloud. Second, we put forth a robust occlusion-aware depth supervision scheme, which allows utilizing densified Lidar points by accumulation. Third, we generate augmented training views from Lidar points for further improvement. Our insights translate to largely improved novel view synthesis under real driving scenes. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present a Multi-Instance Generation (MIG) task, simultaneously generating multiple instances with diverse controls in one image. Given a set of predefined coordinates and their corresponding descriptions, the task is to ensure that generated instances are accurately at the designated locations and that all instances' attributes adhere to their corresponding description. This broadens the scope of current research on Single-instance generation, elevating it to a more versatile and practical dimension. Inspired by the idea of divide and conquer, we introduce an innovative approach named Multi-Instance Generation Controller (MIGC) to address the challenges of the MIG task. Initially, we break down the MIG task into several subtasks, each involving the shading of a single instance. To ensure precise shading for each instance, we introduce an instance enhancement attention mechanism. Lastly, we aggregate all the shaded instances to provide the necessary information for accurately generating multiple instances in stable diffusion (SD). To evaluate how well generation models perform on the MIG task, we provide a COCO-MIG benchmark along with an evaluation pipeline. Extensive experiments were conducted on the proposed COCO-MIG benchmark, as well as on various commonly used benchmarks. The evaluation results illustrate the exceptional control capabilities of our model in terms … |
|
Highlight
|
Poster
[ Arch 4A-E ] 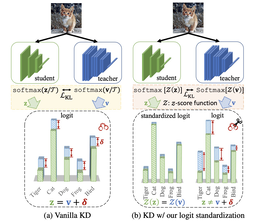
Abstract
Knowledge distillation involves transferring soft labels from a teacher to a student using a shared temperature-based softmax function. However, the assumption of a shared temperature between teacher and student implies a mandatory exact match between their logits in terms of logit range and variance. This side-effect limits the performance of student, considering the capacity discrepancy between them and the finding that the innate logit relations of teacher are sufficient for student to learn. To address this issue, we propose setting the temperature as the weighted standard deviation of logit and performing a plug-and-play $\mathcal{Z}$-score pre-process of logit standardization before applying softmax and Kullback-Leibler divergence. Our pre-process enables student to focus on essential logit relations from teacher rather than requiring a magnitude match, and can improve the performance of existing logit-based distillation methods. We also show a typical case where the conventional setting of sharing temperature between teacher and student cannot reliably yield an authentic distillation evaluation; nonetheless, this challenge is successfully alleviated by our $\mathcal{Z}$-score. We extensively evaluate our method for various student and teacher models on CIFAR-100 and ImageNet, showing its significant superiority. The vanilla knowledge distillation powered by our pre-process can achieve favorable performance against state-of-the-art methods, and …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractCustomization techniques for text-to-image models have paved the way for a wide range of previously unattainable applications, enabling the generation of specific concepts across diverse contexts and styles. While existing methods facilitate high-fidelity customization for individual concepts or a limited, pre-defined set of them, they fall short of achieving scalability, where a single model can seamlessly render countless concepts. In this paper, we address a new problem called Modular Customization, with the goal of efficiently merging customized models that were fine-tuned independently for individual concepts. This allows the merged model to jointly synthesize concepts in one image without compromising fidelity or incurring any additional computational costs.To address this problem, we introduce Orthogonal Adaptation, a method designed to encourage the customized models, which do not have access to each other during fine-tuning, to have orthogonal residual weights. This ensures that during inference time, the customized models can be summed with minimal interference. Our proposed method is both simple and versatile, applicable to nearly all optimizable weights in the model architecture. Through an extensive set of quantitative and qualitative evaluations, our method consistently outperforms relevant baselines in terms of efficiency and identity preservation, demonstrating a significant leap toward scalable customization of diffusion … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWhile head-mounted devices are becoming more compact, they provide egocentric views with significant self-occlusions of the device user. Hence, existing methods often fail to accurately estimate complex 3D poses from egocentric views. In this work, we propose a new transformer-based framework to improve egocentric stereo 3D human pose estimation, which leverages the scene information and temporal context of egocentric stereo videos. Specifically, we utilize 1) depth features from our 3D scene reconstruction module with uniformly sampled windows of egocentric stereo frames, and 2) human joint queries enhanced by temporal features of the video inputs. Our method is able to accurately estimate human poses even in challenging scenarios, such as crouching and sitting. Furthermore, we introduce two new benchmark datasets, i.e., UnrealEgo2 and UnrealEgo-RW (Real World). The proposed datasets offer a much larger number of egocentric stereo views with a wider variety of human motions than the existing datasets, allowing comprehensive evaluation of existing and upcoming methods. Our extensive experiments show that the proposed approach significantly outperforms previous methods. We will release UnrealEgo2, UnrealEgo-RW, and trained models on our project page. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractAccurate and controllable image editing is a challenging task that has attracted significant attention recently. Notably, DragGAN developed by Pan et al (2023) is an interactive point-based image editing framework that achieves impressive editing results with pixel-level precision. However, due to its reliance on generative adversarial networks (GANs), its generality is limited by the capacity of pretrained GAN models. In this work, we extend this editing framework to diffusion models and propose a novel approach DragDiffusion. By harnessing large-scale pretrained diffusion models, we greatly enhance the applicability of interactive point-based editing on both real and diffusion-generated images. Unlike other diffusion-based editing methods that provide guidance on diffusion latents of multiple time steps, our approach achieves efficient yet accurate spatial control by optimizing the latent of only one time step. This novel design is motivated by our observations that UNet features at a specific time step provides sufficient semantic and geometric information to support the drag-based editing. Moreover, we introduce two additional techniques, namely identity-preserving fine-tuning and reference-latent-control, to further preserve the identity of the original image. Lastly, we present a challenging benchmark dataset called DragBench---the first benchmark to evaluate the performance of interactive point-based image editing methods. Experiments across a … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Realizing unified monocular 3D object detection, including both indoor and outdoor scenes, holds great importance in applications like robot navigation. However, involving various scenarios of data to train models poses challenges due to their significantly different characteristics, e.g., diverse geometry properties and heterogeneous domain distributions. To address these challenges, we build a detector based on the bird's-eye-view (BEV) detection paradigm, where the explicit feature projection is beneficial to addressing the geometry learning ambiguity when employing multiple scenarios of data to train detectors. Then, we split the classical BEV detection architecture into two stages and propose an uneven BEV grid design to handle the convergence instability caused by the aforementioned challenges. Moreover, we develop a sparse BEV feature projection strategy to reduce computational cost and a unified domain alignment method to handle heterogeneous domains. Combining these techniques, a unified detector UniMODE is derived, which surpasses the previous state-of-the-art on the challenging Omni3D dataset (a large-scale dataset including both indoor and outdoor scenes) by 4.9% $\rm AP_{3D}$, revealing the first successful generalization of a BEV detector to unified 3D object detection.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe introduce DyNFL, a novel neural field-based approach for high-fidelity re-simulation of LiDAR scans in dynamic driving scenes. DyNFL processes LiDAR measurements from dynamic environments, accompanied by bounding boxes of moving objects, to construct an editable neural field. This field, comprising separately reconstructed static backgrounds and dynamic objects, allows users to modify viewpoints, adjust object positions, and seamlessly add or remove objects in the re-simulated scene. A key innovation of our method is the neural field composition technique, which effectively integrates reconstructed neural assets from various scenes through a ray drop test, accounting for occlusions and transparent surfaces. Our evaluation with both synthetic and real-world environments demonstrates that DyNFL substantial improves dynamic scene simulation based on LiDAR scans, offering a combination of physical fidelity and flexible editing capabilities. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Sampling from diffusion models can be treated as solving the corresponding ordinary differential equations (ODEs), with the aim of obtaining an accurate solution with as few number of function evaluations (NFE) as possible. Recently, various fast samplers utilizing higher-order ODE solvers have emerged and achieved better performance than the initial first-order one.However, these numerical methods inherently result in certain approximation errors, which significantly degrades sample quality with extremely small NFE (e.g., around 5).In contrast, based on the geometric observation that each sampling trajectory almost lies in a two-dimensional subspace embedded in the ambient space, we propose **A**pproximate **ME**an-**D**irection Solver (AMED-Solver) that eliminates truncation errors by directly learning the mean direction for fast diffusion sampling. Besides, our method can be easily used as a plugin to further improve existing ODE-based samplers. Extensive experiments on image synthesis with the resolution ranging from 32 to 512 demonstrate the effectiveness of our method. With only 5 NFE, we achieve 6.61 FID on CIFAR-10, 10.74 FID on ImageNet 64$\times$64, and 13.20 FID on LSUN Bedroom. Our code is available at https://github.com/zju-pi/diff-sampler.
|
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
Establishing an automatic evaluation metric that closely aligns with human judgments is essential for effectively developing image captioning models. Recent data-driven metrics have demonstrated a stronger correlation with human judgments than classic metrics such as CIDEr; however they lack sufficient capabilities to handle hallucinations and generalize across diverse images and texts partially because they compute scalar similarities merely using embeddings learned from tasks unrelated to image captioning evaluation.In this study, we propose Polos, a supervised automatic evaluation metric for image captioning models.Polos computes scores from multimodal inputs, using a parallel feature extraction mechanism that leverages embeddings trained through large-scale contrastive learning.To train Polos, we introduce Multimodal Metric Learning from Human Feedback (M$^2$LHF), a framework for developing metrics based on human feedback. We constructed the Polaris dataset, which comprises 131K human judgments from 550 evaluators, which is approximately ten times larger than standard datasets. Our approach achieved state-of-the-art performance on Composite, Flickr8K-Expert, Flickr8K-CF, PASCAL-50S, FOIL, and the Polaris dataset, thereby demonstrating its effectiveness and robustness.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractRecent years have witnessed a trend of the deep integration of the generation and reconstruction paradigms. In this paper, we extend the ability of controllable generative models for a more comprehensive hand mesh recovery task: direct hand mesh generation, inpainting, reconstruction, and fitting in a single framework, which we name as Holistic Hand Mesh Recovery (HHMR).Our key observation is that different kinds of hand mesh recovery tasks can be achieved by a single generative model with strong multimodal controllability, and in such a framework, realizing different tasks only requires giving different signals as conditions. To achieve this goal, we propose an all-in-one diffusion framework based on graph convolution and attention mechanisms for holistic hand mesh recovery. In order to achieve strong control generation capability while ensuring the decoupling of multimodal control signals, we map different modalities to a share feature space and apply cross-scale random masking in both modality and feature levels. In this way, the correlation between different modalities can be fully exploited during the learning of hand priors. Furthermore, we propose Condition-aligned Gradient Guidance to enhance the alignment of the generated model with the control signals, which significantly improves the accuracy of the hand … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractMonocular depth estimation has experienced significant progress on terrestrial images in recent years thanks to deep learning advancements. But it remains inadequate for underwater scenes primarily due to data scarcity. Given the inherent challenges of light attenuation and backscatter in water, acquiring clear underwater images or precise depth is notably difficult and costly. To mitigate this issue, learning-based approaches often rely on synthetic data or turn to self- or unsupervised manners. Nonetheless, their performance is often hindered by domain gap and looser constraints. In this paper, we propose a novel pipeline for generating photorealistic underwater images using accurate terrestrial depth. This approach facilitates the supervised training of models for underwater depth estimation, effectively reducing the performance disparity between terrestrial and underwater environments. Contrary to previous synthetic datasets that merely apply style transfer to terrestrial images without scene content change, our approach uniquely creates vivid non-existent underwater scenes by leveraging terrestrial depth data through the innovative Stable Diffusion model. Specifically, we introduce a specialized Depth2Underwater ControlNet, trained on prepared {Underwater, Depth, Text} data triplets, for this generation task. Our newly developed dataset, Atlantis, enables terrestrial depth estimation models to achieve considerable improvements on unseen underwater scenes, surpassing their terrestrial pretrained counterparts … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractImage-goal navigation is a challenging task that requires an agent to navigate to a goal indicated by an image in unfamiliar environments. Existing methods utilizing diverse scene memories suffer from inefficient exploration since they use all historical observations for decision-making without considering the goal-relevant fraction. To address this limitation, we present MemoNav, a novel memory model for image-goal navigation, which utilizes a working memory-inspired pipeline to improve navigation performance. Specifically, we employ three types of navigation memory. The node features on a map are stored in the short-term memory (STM), as these features are dynamically updated. A forgetting module then retains the informative STM fraction to increase efficiency. We also introduce long-term memory (LTM) to learn global scene representations by progressively aggregating STM features. Subsequently, a graph attention module encodes the retained STM and the LTM to generate working memory (WM) which contains the scene features essential for efficient navigation. The synergy among these three memory types boosts navigation performance by enabling the agent to learn and leverage goal-relevant scene features within a topological map. Our evaluation on multi-goal tasks demonstrates that MemoNav significantly outperforms previous methods across all difficulty levels in both Gibson and Matterport3D scenes. Qualitative results further … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractConditional diffusion models are powerful generative models that can leverage various types of conditional information, such as class labels, segmentation masks, or text captions. However, in many real-world scenarios, conditional information may be noisy or unreliable due to human annotation errors or weak alignment. In this paper, we propose the Coherence-Aware Diffusion (CAD), a novel method to integrate confidence in conditional information into diffusion models, allowing them to learn from noisy annotations without discarding data. We assume that each data point has an associated confidence score that reflects the quality of the conditional information. We then condition the diffusion model on both the conditional information and the confidence score. In this way, the model learns to ignore or discount the conditioning when the confidence is low. We show that our method is theoretically sound and empirically effective on various conditional generation tasks. Moreover, we show that leveraging confidence generates realistic and diverse samples that respect conditional information better than models trained on cleaned datasets where samples with low confidence have been discarded. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Human lives in a 3D world and commonly uses natural language to interact with a 3D scene. Modeling a 3D language field to support open-ended language queries in 3D has gained increasing attention recently. This paper introduces LangSplat, which constructs a 3D language field that enables precise and efficient open-vocabulary querying within 3D spaces. Unlike existing methods that ground CLIP language embeddings in a NeRF model, LangSplat advances the field by utilizing a collection of 3D Gaussians, each encoding language features distilled from CLIP, to represent the language field. By employing a tile-based splatting technique for rendering language features, we circumvent the costly rendering process inherent in NeRF. Instead of directly learning CLIP embeddings, LangSplat first trains a scene-wise language autoencoder and then learns language features on the scene-specific latent space, thereby alleviating substantial memory demands imposed by explicit modeling. Existing methods struggle with imprecise and vague 3D language fields, which fail to discern clear boundaries between objects. We delve into this issue and propose to learn hierarchical semantics using SAM, thereby eliminating the need for extensively querying the language field across various scales and the regularization of DINO features. Extensive experiments on open-vocabulary 3D object localization and semantic segmentation …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 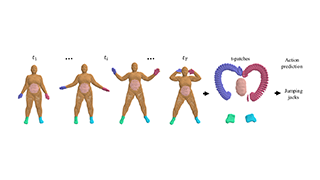
AbstractWe propose a novel method for 3D point cloud action recognition. Understanding human actions in RGB videos has been widely studied in recent years, however, its 3D point cloud counterpart remains under-explored. This is mostly due to the inherent limitation of the point cloud data modality---lack of structure, permutation invariance, and varying number of points---which makes it difficult to learn a spatio-temporal representation. To address this limitation, we propose the 3DinAction pipeline that first estimates patches moving in time (t-patches) as a key building block, alongside a hierarchical architecture that learns an informative spatio-temporal representation. We show that our method achieves improved performance on existing datasets, including DFAUST and IKEA ASM.Code is publicly available at https://github.com/sitzikbs/3dincaction |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractThis paper aims at achieving fine-grained building attribute segmentation in a cross-view scenario, i.e., using street-view and satellite image pairs. The main challenge lies in overcoming the significant perspective differences between street views and satellite views. In this work, we introduce SG-BEV, a novel approach for satellite-guided BEV fusion for cross-view semantic segmentation. To overcome the limitations of existing cross-view projection methods in capturing the complete building facade features, we innovatively incorporate Bird's Eye View (BEV) method to establish a spatially explicit mapping of street-view features. Moreover, we fully leverage the advantages of multiple perspectives by introducing a novel satellite-guided reprojection module, optimizing the uneven feature distribution issues associated with traditional BEV methods. Our method demonstrates significant improvements on four cross-view datasets collected from multiple cities, including New York, San Francisco, and Boston. On average across these datasets, our method achieves an increase in mIOU by 10.13% and 5.21% compared with the state-of-the-art satellite-based and cross-view methods. The code, models, and data of this work will be released to the public. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDirectly generating scenes from satellite imagery offers exciting possibilities for integration into applications like games and map services. However, challenges arise from significant view changes and scene scale. Previous efforts mainly focused on image or video generation, lacking exploration into the adaptability of scene generation for arbitrary views. Existing 3D generation works either operate at the object level or are difficult to utilize the geometry obtained from satellite imagery. To overcome these limitations, we propose a novel architecture for direct 3D scene generation by introducing diffusion models into 3D sparse representations and combining them with neural rendering techniques. Specifically, our approach generates texture colors at the point level for a given geometry using a 3D diffusion model first, which is then transformed into a scene representation in a feed-forward manner. The representation can be utilized to render arbitrary views which would excel in both single-frame quality and inter-frame consistency. Experiments in two city-scale datasets show that our model demonstrates proficiency in generating photo-realistic street-view image sequences and cross-view urban scenes from satellite imagery. |
|
Highlight
|
Poster
[ Arch 4A-E ] 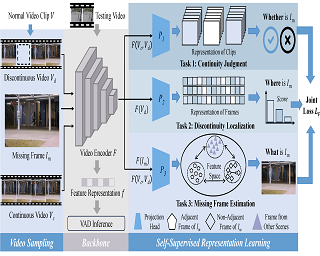
AbstractRecent progress in video anomaly detection suggests that the features of appearance and motion play crucial roles in distinguishing abnormal patterns from normal ones. However, we note that the effect of spatial scales of anomalies is ignored. The fact that many abnormal events occur in limited localized regions and severe background noise interferes with the learning of anomalous changes. Meanwhile, most existing methods are limited by coarse-grained modeling approaches, which are inadequate for learning highly discriminative features to discriminate subtle differences between small-scale anomalies and normal patterns. To this end, this paper address multi-scale video anomaly detection by multi-grained spatio-temporal representation learning. We utilize video continuity to design three proxy tasks to perform feature learning at both coarse-grained and fine-grained levels, i.e., continuity judgment, discontinuity localization, and missing frame estimation. In particular, we formulate missing frame estimation as a contrastive learning task in feature space instead of a reconstruction task in RGB space to learn highly discriminative features. Experiments show that our proposed method outperforms state-of-the-art methods on four datasets, especially in scenes with small-scale anomalies. |
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
This paper presents a novel non-rigid point set registration method that is inspired by unsupervised clustering analysis. Unlike previous approaches that treat the source and target point sets as separate entities, we develop a holistic framework where they are formulated as clustering centroids and clustering members, separately. We then adopt Tikhonov regularization with an $\ell_1$-induced Laplacian kernel instead of the commonly used Gaussian kernel to ensure smooth and more robust displacement fields. Our formulation delivers closed-form solutions, theoretical guarantees, independence from dimensions, and the ability to handle large deformations. Subsequently, we introduce a clustering-improved Nystr{\"o}m method to effectively reduce the computational complexity and storage of the Gram matrix to linear, while providing a rigorous bound for the low-rank approximation. Our method achieves high accuracy results across various scenarios and surpasses competitors by a significant margin, particularly on shapes with substantial deformations. Additionally, we demonstrate the versatility of our method in challenging tasks such as shape transfer and medical registration.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 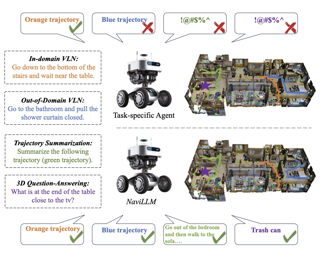
AbstractBuilding a generalist agent that can interact with the world is an ultimate goal for humans, thus spurring the research for embodied navigation, where an agent is required to navigate according to instructions or respond to queries. Despite the major progress attained, previous works primarily focus on task-specific agents and lack generalizability to unseen scenarios. Recently, LLMs have presented remarkable capabilities across various fields, and provided a promising opportunity for embodied navigation. Drawing on this, we propose the first generalist model for embodied navigation, NaviLLM. It adapts LLMs to embodied navigation by introducing schema-based instruction. The schema-based instruction flexibly casts various tasks into generation problems, thereby unifying a wide range of tasks. This approach allows us to integrate diverse data sources from various datasets into the training, equipping NaviLLM with a wide range of capabilities required by embodied navigation. We conduct extensive experiments to evaluate the performance and generalizability of our model. The experimental results demonstrate that our unified model achieves state-of-the-art performance on CVDN, SOON, and ScanQA. Specifically, it surpasses the previous stats-of-the-art method by a significant margin of 29\% in goal progress on CVDN. Moreover, our model also demonstrates strong generalizability and presents impressive results on unseen … |
|
Highlight
|
Poster
[ Arch 4A-E ] 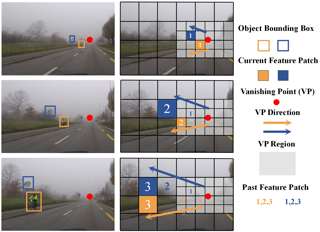
AbstractThe estimation of implicit cross-frame correspondences and the high computational cost have long been major challenges in video semantic segmentation (VSS) for driving scenes. Prior works utilize keyframes, feature propagation, or cross-frame attention to address these issues.By contrast, we are the first to harness vanishing point (VP) priors for more effective segmentation. Intuitively, objects near VPs (i.e., away from the vehicle) are less discernible. Moreover, they tend to move radially away from the VP over time in the usual case of a forward-facing camera, a straight road, and linear forward motion of the vehicle. Our novel, efficient network for VSS, named VPSeg, incorporates two modules that utilize exactly this pair of static and dynamic VP priors: sparse-to-dense feature mining (DenseVP) and VP-guided motion fusion (MotionVP). MotionVP employs VP-guided motion estimation to establish explicit correspondences across frames and help attend to the most relevant features from neighboring frames, while DenseVP enhances weak dynamic features in distant regions around VPs. These modules operate within a context-detail framework, which separates contextual features from high-resolution local features at different input resolutions to reduce computational costs. Contextual and local features are integrated through contextualized motion attention (CMA) for the final prediction. Extensive experiments on two … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractIn the film and gaming industries, achieving a realistic hair appearance typically involves the use of strands originating from the scalp.However, reconstructing these strands from observed surface images of hair presents significant challenges.The difficulty in acquiring Ground Truth (GT) data has led state-of-the-art learning-based methods to rely on pre-training with manually prepared synthetic CG data.This process is not only labor-intensive and costly but also introduces complications due to the domain gap when compared to real-world data.In this study, we propose an optimization-based approach that eliminates the need for pre-training.Our method represents hair strands as line segments growing from the scalp and optimizes them using a novel differentiable rendering algorithm.To robustly optimize a substantial number of slender explicit geometries, we introduce 3D orientation estimation utilizing global optimization, strand initialization based on Laplace's equation, and reparameterization that leverages geometric connectivity and spatial proximity.Unlike existing optimization-based methods, our method is capable of reconstructing internal hair flow in an absolute direction.Our method exhibits robust and accurate inverse rendering, surpassing the quality of existing methods and significantly improving processing speed. |
|
Highlight
|
Poster
[ Arch 4A-E ] 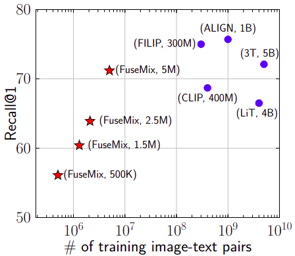
Abstract
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $\sim 600\times$ fewer GPU days and $\sim 80\times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Humans naturally interact with both others and the surrounding multiple objects, engaging in various social activities. However, recent advances in modeling human-object interactions mostly focus on perceiving isolated individuals and objects, due to fundamental data scarcity. In this paper, we introduce HOI-M$^3$, a novel large-scale dataset for modeling the interactions of Multiple huMans and Multiple objects. Notably, it provides accurate 3D tracking for both humans and objects from dense RGB and object-mounted IMU inputs, covering 199 sequences and 181M frames of diverse humans and objects under rich activities. With the unique HOI-M$^3$ dataset, we introduce two novel data-driven tasks with companion strong baselines: monocular capture and unstructured generation of multiple human-object interactions. Extensive experiments demonstrate that our dataset is challenging and worthy of further research about multiple human-object interactions and behavior analysis. Our HOI-M$^3$ dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research.
|
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractLarge multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this paper, we present the first systematic study to investigate the design choices of LMMs in a controlled setting under the LLaVA framework. We show that the fully-connected vision-language connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ~1 day on a single 8-A100 node. Furthermore, we present some early exploration of open problems in LMMs, including scaling to higher resolution inputs, compositional capabilities, and model hallucination, etc. We hope this makes state-of-the-art LMM research more accessible. Code and model will be publicly available. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractThe studies of human clothing for digital avatars have predominantly relied on synthetic datasets. While easy to collect, synthetic data often fall short in realism and fail to capture authentic clothing dynamics. Addressing this gap, we introduce 4D-DRESS, the first real-world 4D dataset advancing human clothing research with its high-quality 4D textured scans and garment meshes. 4D-DRESS captures 64 outfits in 520 human motion sequences, amounting to 78k textured scans. Creating a real-world clothing dataset is challenging, particularly in annotating and segmenting the extensive and complex 4D human scans. To address this, we develop a semi-automatic 4D human parsing pipeline. We efficiently combine a human-in-the-loop process with automation to accurately label 4D scans in diverse garments and body movements. Leveraging precise annotations and high-quality garment meshes, we establish several benchmarks for clothing simulation and reconstruction. 4D-DRESS offers realistic and challenging data that complements synthetic sources, paving the way for advancements in research of lifelike human clothing. Website: https://ait.ethz.ch/4d-dress. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractFor human-centric large-scale scenes, fine-grained modeling for 3D human global pose and shape is significant for scene understanding and can benefit many real-world applications. In this paper, we present LiveHPS, a novel single LiDAR-based approach for scene-level Human Pose and Shape estimation without any limitation of light conditions and wearable devices. In particular, we design a distillation mechanism to mitigate the distribution-varying effect of LiDAR point clouds and exploit the temporal-spatial geometric and dynamic information existing in consecutive frames to solve the occlusion and noise disturbance. LiveHPS, with its efficient configuration and high-quality output, is well-suited for real-world applications.Moreover, we propose a huge human motion dataset, named FreeMotion, which is collected in various scenarios with diverse human poses, shapes and translations. It consists of multi-modal and multi-view acquisition data from calibrated and synchronized LiDARs, cameras, and IMUs. Extensive experiments on our new dataset and other public datasets demonstrate the SOTA performance and robustness of our approach. We will release our code and dataset soon. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDespite significant advancements in text-to-motion synthesis, generating language-guided human motion within 3D environments poses substantial challenges. These challenges stem primarily from (i) the absence of powerful generative models capable of jointly modeling natural language, 3D scenes, and human motion, and (ii) the generative models' intensive data requirements contrasted with the scarcity of comprehensive, high-quality, language-scene-motion datasets. To tackle these issues, we introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation. Our framework comprises an Affordance Diffusion Model (ADM) for predicting explicit affordance map and an Affordance-to-Motion Diffusion Model (AMDM) for generating plausible human motions. By leveraging scene affordance maps, our method overcomes the difficulty in generating human motion under multimodal condition signals, especially when training with limited data lacking extensive language-scene-motion pairs. Our extensive experiments demonstrate that our approach consistently outperforms all baselines on established benchmarks, including HumanML3D and HUMANISE. Additionally, we validate our model's exceptional generalization capabilities on a specially curated evaluation set featuring previously unseen descriptions and scenes. |
|
Highlight
|
Poster
[ Arch 4A-E ] 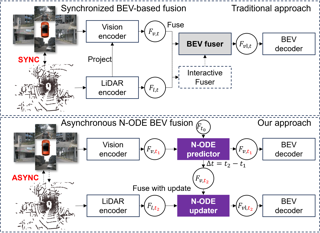
AbstractPredicting the future occupancy of the surrounding environment is a vital task for autonomous driving. However, current best-performing single-modality or multi-modality fusion methods can only predict uniform snapshots of future occupancy states and still require strictly synchronous sensory data for sensor fusion. We propose a StreamingFlow framework to lift these strong limitations. StreamingFlow is a novel BEV occupancy predictor that ingests asynchronous multi-sensor data streams for fusion and performs streaming forecasting of the future occupancy map at any future timestamps. By integrating neural ordinary differential equations (N-ODE) onto recurrent neural networks, StreamingFlow learns derivatives of BEV features over temporal horizons, updates the implicit sensor's BEV feature as part of the fusion process, and propagates BEV states to the desired future time point. Extensive experiments on two large-scale datasets, nuScenes and Lyft L5, demonstrate that StreamingFlow significantly outperforms previous vision-based, lidar-based methods, and shows competitive performance compared to state-of-the-art fusion-based methods with a much lighter model. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Most diffusion models assume that the reverse process adheres to a Gaussian distribution. However, this approximation has not been rigorously validated, especially at singularities, where $t=0$ and $t=1$. Improperly dealing with such singularities leads to an average brightness issue in applications, and limits the generation of images with extreme brightness or darkness. We primarily focus on tackling singularities from both theoretical and practical perspectives. Initially, we establish the error bounds for the reverse process approximation, and showcase its Gaussian characteristics at singularity time steps. Based on this theoretical insight, we confirm the singularity at $t=1$ is conditionally removable while it at $t=0$ is an inherent property. Upon these significant conclusions, we propose a novel plug-and-play module to address the initial singular time step sampling, which not only effectively resolves the average brightness issue for a wide range of diffusion models without extra training efforts, but also enhances their generation capability in achieving notable lower FID scores.
|
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
We present a novel method for efficiently producing semi-dense matches across images.Previous detector-free matcher LoFTR has shown remarkable matching capability in handling large-viewpoint change and texture-poor scenarios but suffers from low efficiency.We revisit its design choices and derive multiple improvements for both efficiency and accuracy.One key observation is that performing the transformer over the entire feature map is redundant due to shared local information, therefore we propose an aggregated attention mechanism with adaptive token selection for efficiency.Furthermore, we find spatial bias exists in LoFTR's fine correlation module, which is adverse to matching accuracy.A novel two-stage correlation layer is proposed to achieve unbiased subpixel correspondences for accuracy improvement.Our efficiency optimized model is $\sim 2.5\times$ faster than LoFTR which can even surpass state-of-the-art efficient sparse matching pipeline SuperPoint + LightGlue. Moreover, extensive experiments show that our method can achieve higher accuracy compared with competitive semi-dense matchers, with considerable efficiency benefits.This opens up exciting prospects for large-scale or latency-sensitive applications such as image retrieval and 3D reconstruction.Our code will be released for reproducibility.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 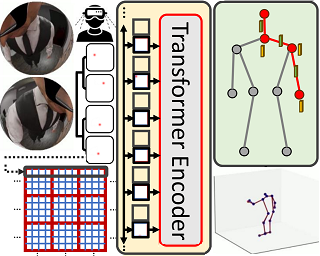
AbstractWe present EgoTAP, a heatmap-to-3D pose lifting method for highly accurate stereo egocentric 3D pose estimation. Severe self-occlusion and out-of-view limbs in egocentric camera views make accurate pose estimation a challenging problem. To address the challenge, prior methods employ joint heatmaps-probabilistic 2D representations of the body pose, but heatmap-to-3D pose conversion still remains an inaccurate process. We propose a novel heatmap-to-3D lifting method composed of the Grid ViT Encoder and the Propagation Network. The Grid ViT Encoder summarizes joint heatmaps into effective feature embedding using self-attention. Then, the Propagation Network estimates the 3D pose by utilizing skeletal information to better estimate the position of obscure joints. Our method significantly outperforms the previous state-of-the-art qualitatively and quantitatively demonstrated by a 23.9\% reduction of error in an MPJPE metric. Our source code is available on GitHub. |
|
Highlight
|
Poster
[ Arch 4A-E ] 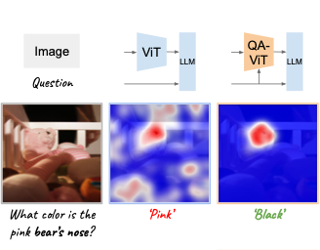
AbstractVision-Language (VL) models have gained significant research focus, enabling remarkable advances in multimodal reasoning. These architectures typically comprise a vision encoder, a Large Language Model (LLM), and a projection module that aligns visual features with the LLM's representation space. Despite their success, a critical limitation persists: the vision encoding process remains decoupled from user queries, often in the form of image-related questions. Consequently, the resulting visual features may not be optimally attuned to the query-specific elements of the image.To address this, we introduce QA-ViT, a Question Aware Vision Transformer approach for multimodal reasoning, which embeds question awareness directly within the vision encoder.This integration results in dynamic visual features focusing on relevant image aspects to the posed question.QA-ViT is model-agnostic and can be incorporated efficiently into any VL architecture.Extensive experiments demonstrate the effectiveness of applying our method to various multimodal architectures, leading to consistent improvement across diverse tasks and showcasing its potential for enhancing visual and scene-text understanding. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractNeural implicit fields have been a de facto standard in novel view synthesis. Recently, there exist some methods exploring fusing multiple modalities within a single field, aiming to share implicit features from different modalities to enhance reconstruction performance. However, these modalities often exhibit misaligned behaviors: optimizing for one modality, such as LiDAR, can adversely affect another, like camera performance, and vice versa. In this work, we conduct comprehensive analyses on the multimodal implicit field of LiDAR-camera joint synthesis, revealing the underlying issue lies in the misalignment of different sensors.Furthermore, we introduce AlignMiF, a geometrically aligned multimodal implicit field with two proposed modules: Geometry-Aware Alignment (GAA) and Shared Geometry Initialization (SGI). These modules effectively align the coarse geometry across different modalities, significantly enhancing the fusion process between LiDAR and camera data. Through extensive experiments across various datasets and scenes, we demonstrate the effectiveness of our approach in facilitating better interaction between LiDAR and camera modalities within a unified neural field. Specifically, our proposed AlignMiF, achieves remarkable improvement over recent implicit fusion methods (+2.01 and +3.11 image PSNR on the KITTI-360 and Waymo datasets) and consistently surpasses single modality performance (13.8\% and 14.2\% reduction in LiDAR Chamfer Distance on the respective datasets). |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractCurrent instruction-based image editing methods, such as InstructPix2Pix, often fail to produce satisfactory results in complex scenarios due to their dependence on the simple CLIP text encoder in diffusion models. To rectify this, this paper introduces SmartEdit, a novel approach of instruction-based image editing that leverages Multimodal Large Language Models (MLLMs) to enhance its understanding and reasoning capabilities. However, direct integration of these elements still faces challenges in situations requiring complex reasoning. To mitigate this, we propose a Bidirectional Interaction Module (BIM) that enables comprehensive bidirectional information interactions between the input image and the MLLM output. During training, we initially incorporate perception data to boost the perception and understanding capabilities of diffusion models. Subsequently, we demonstrate that a small amount of complex instruction editing data can effectively stimulate SmartEdit's editing capabilities for more complex instructions. We further construct a new evaluation dataset, Reason-Edit, specifically tailored for complex instruction-based image editing. Both quantitative and qualitative results on this evaluation dataset indicate that our SmartEdit surpasses previous methods, paving the way for the practical application of complex instruction-based image editing. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractText-based diffusion models have exhibited remarkable success in generation and editing, showing great promise for enhancing visual content with their generative prior. However, applying these models to video super-resolution remains challenging due to the high demands for output fidelity and temporal consistency, which is complicated by the inherent randomness in diffusion models. Our study introduces Upscale-A-Video, a text-guided latent diffusion framework for video upscaling. This framework ensures temporal coherence through two key mechanisms: locally, it integrates temporal layers into U-Net and VAE-Decoder, maintaining consistency in short sequences; globally, without training, a flow-guided latent propagation module is introduced to enhance overall video stability by propagating and fusing latent across the entire sequences. Thanks to the diffusion paradigm, our model also offers greater flexibility by allowing text prompts to guide texture creation and adjustable noise levels to balance restoration and generation, enabling a trade-off between fidelity and quality. Extensive experiments show that Upscale-A-Video surpasses existing methods in both synthetic and real-world benchmarks, as well as in AI-generated videos, showcasing impressive visual realism and temporal consistency. |
|
Highlight
|
Poster
[ Arch 4A-E ] 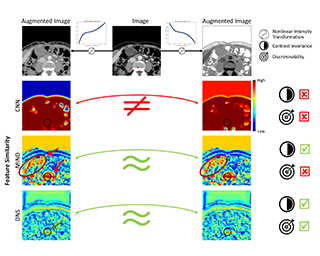
AbstractEstablishing dense anatomical correspondence across distinct imaging modalities is a foundational yet challenging procedure for numerous medical image analysis studies and image-guided radiotherapy. Existing multi-modality image registration algorithms rely on statistical-based similarity measures or local structural image representations. However, the former is sensitive to locally varying noise, while the latter is not discriminative enough to cope with complex anatomical structures in multimodal scans, causing ambiguity in determining the anatomical correspondence across scans with different modalities. In this paper, we propose a modality-agnostic structural representation learning method, which leverages Deep Neighbourhood Self-similarity (DNS) and anatomy-aware contrastive learning to learn discriminative and contrast-invariance deep structural image representations (DSIR) without the need for anatomical delineations or pre-aligned training images. We evaluate our method on multiphase CT, abdomen MR-CT, and brain MR T1w-T2w registration. Comprehensive results demonstrate that our method is superior to the conventional local structural representation and statistical-based similarity measures in terms of discriminability and accuracy. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractVideo generation has witnessed significant advancements, yet evaluating these models remains a challenge. A comprehensive evaluation benchmark for video generation is indispensable for two reasons: 1) Existing metrics do not fully align with human perceptions; 2) An ideal evaluation system should provide insights to inform future developments of video generation. To this end, we present VBench, a comprehensive benchmark suite that dissects "video generation quality" into specific, hierarchical, and disentangled dimensions, each with tailored prompts and evaluation methods. VBench has three appealing properties: 1) Comprehensive Dimensions: VBench comprises 16 dimensions in video generation (e.g., subject identity inconsistency, motion smoothness, temporal flickering, and spatial relationship, etc). The evaluation metrics with fine-grained levels reveal individual models' strengths and weaknesses. 2) Human Alignment: We also provide a dataset of human preference annotations to validate our benchmarks' alignment with human perception, for each evaluation dimension respectively. 3) Valuable Insights: We look into current models' ability across various evaluation dimensions, and various content types. We also investigate the gaps between video and image generation models. We will open-source VBench, including all prompts, evaluation methods, generated videos, and human preference annotations, and also include more video generation models in VBench to drive forward the field of … |
|
Highlight
|
Poster
[ Arch 4A-E ] 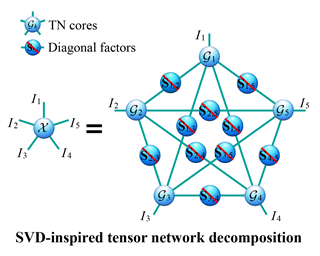
AbstractTensor network (TN) representation is a powerful technique for computer vision and machine learning. TN structure search (TN-SS) aims to search for a customized structure to achieve a compact representation, which is a challenging NP-hard problem. Recent "sampling-evaluation"-based methods require sampling an extensive collection of structures and evaluating them one by one, resulting in prohibitively high computational costs. To address this issue, we propose a novel TN paradigm, named SVD-inspired TN decomposition (SVDinsTN), which allows us to efficiently solve the TN-SS problem from a regularized modeling perspective, eliminating the repeated structure evaluations. To be specific, by inserting a diagonal factor for each edge of the fully-connected TN, SVDinsTN allows us to calculate TN cores and diagonal factors simultaneously, with the factor sparsity revealing a compact TN structure. In theory, we prove a convergence guarantee for the proposed method. Experimental results demonstrate that the proposed method achieves approximately 100~1000 times acceleration compared to the state-of-the-art TN-SS methods while maintaining a comparable level of representation ability. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractReconstructing human-object interaction in 3D from a single RGB image is a challenging task and existing data driven methods do not generalize beyond the objects present in the carefully curated 3D interaction datasets.Capturing large-scale real data to learn strong interaction and 3D shape priors is very expensive due to the combinatorial nature of human-object interactions. In this paper, we propose ProciGen (Procedural interaction Generation), a method to procedurally generate datasets with both, plausible interaction and diverse object variation.We generate 1M+ human-object interaction pairs in 3D and leverage this large-scale data to train our HDM (Hierarchical Diffusion Model), a novel method to reconstruct interacting human and unseen objects, without any templates. Our HDM is an image-conditioned diffusion model that learns both realistic interaction and highly accurate human and object shapes.Experiments show that our HDM trained with ProciGen significantly outperforms prior methods that requires template meshes and that our dataset allows training methods with strong generalization ability to unseen object instances. Our code and data will be publicly released. |
|
Highlight
|
Poster
[ Arch 4A-E ] 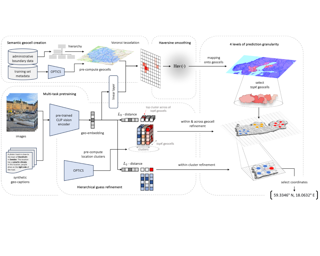
AbstractPlanet-scale image geolocalization remains a challenging problem due to the diversity of images originating from anywhere in the world. Although approaches based on vision transformers have made significant progress in geolocalization accuracy, success in prior literature is constrained to narrow distributions of images of landmarks, and performance has not generalized to unseen places. We present a new geolocalization system that combines semantic geocell creation, multi-task contrastive pretraining, and a novel loss function. Additionally, our work is the first to perform retrieval over location clusters for guess refinements. We train two models for evaluations on street-level data and general-purpose image geolocalization; the first model, PIGEON, is trained on data from the game of GeoGuessr and is capable of placing over 40\% of its guesses within 25 kilometers of the target location globally. We also develop a bot and deploy PIGEON in a blind experiment against humans, ranking in the top 0.01\% of players. We further challenge one of the world's foremost professional GeoGuessr players to a series of six matches with millions of viewers, winning all six games. Our second model, PIGEOTTO, differs in that it is trained on a dataset of images from Flickr and Wikipedia, achieving state-of-the-art results on … |
|
Highlight
|
Poster
[ Arch 4A-E ] 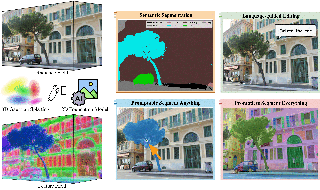
Abstract3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework encounters significant challenges, notably the disparities in spatial resolution and channel consistency between RGB images and feature maps. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractEstimating 6D object poses is a major challenge in 3D computer vision. Building on successful instance-level approaches, research is shifting towards category-level pose estimation for practical applications. Current category-level datasets, however, fall short in annotation quality and pose variety. Addressing this, we introduce HouseCat6D, a new category-level 6D pose dataset. It features 1) multi-modality with Polarimetric RGB and Depth (RGBD+P), 2) encompasses 194 diverse objects across 10 household categories, including two photometrically challenging ones, and 3) provides high-quality pose annotations with an error range of only 1.35 mm to 1.74 mm. The dataset also includes 4) 41 large-scale scenes with comprehensive viewpoint and occlusion coverage, 5) a checkerboard-free environment, and 6) dense 6D parallel-jaw robotic grasp annotations. Additionally, we present benchmark results for leading category-level pose estimation networks. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractIn the literature, points and conics have been major features for camera geometric calibration. Although conics are more informative features than points, the loss of the conic property under distortion has critically limited the utility of conic features in camera calibration. Many existing approaches addressed conic-based calibration by ignoring distortion or introducing 3D spherical targets to circumvent this limitation. In this paper, we present a novel formulation for conic-based calibration using moments. Our derivation is based on the mathematical finding that the first moment can be estimated without bias even under distortion. This allows us to track moment changes during projection and distortion, ensuring the preservation of the first moment of the distorted conic. With an unbiased estimator, the circular patterns can be accurately detected at the sub-pixel level and can now be fully exploited for an entire calibration pipeline, resulting in significantly improved calibration. The entire code is readily available from https://github.com/DisCoCal/DisCoCal. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractDomain generalization (DG) based Face Anti-Spoofing (FAS) aims to improve the model's performance on unseen domains. Existing methods either rely on domain labels to align domain-invariant feature spaces, or disentangle generalizable features from the whole sample, which inevitably lead to the distortion of semantic feature structures and achieve limited generalization. Instead of directly manipulating visual features, we make use of large-scale vision-language models (VLMs) like CLIP and leverage the textual feature to dynamically adjust the classifier's weights for exploring generalizable visual features. Specifically, we propose a novel Class Free Prompt Learning (CFPL) paradigm for DG FAS, which utilizes two lightweight transformers, namely Content Q-Former (CQF) and Style Q-Former (SQF), to learn the different semantic prompts conditioned on content and style features by using a set of learnable query vectors, respectively. Thus, the generalizable prompt can be learned by two improvements: (1) A Prompt-Text Matched (PTM) supervision is introduced to ensure CQF learns visual representation that is most informative of the content description. (2) A Diversified Style Prompt (DSP) technology is proposed to diversify the learning of style prompts by mixing feature statistics between instance-specific styles. Finally, the learned text features modulate visual features to generalization through the designed Prompt Modulation … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe present Readout Guidance, a method for controlling text-to-image diffusion models with learned signals. Readout Guidance uses readout heads, lightweight networks trained to extract signals from the features of a pre-trained, frozen diffusion model at every timestep. These readouts can encode single-image properties, such as pose, depth, and edges; or higher-order properties that relate multiple images, such as correspondence and appearance similarity. Furthermore, by comparing the readout estimates to a user-defined target, and back-propagating the gradient through the readout head, these estimates can be used to guide the sampling process. Compared to prior methods for conditional generation, Readout Guidance requires significantly fewer added parameters and training samples, and offers a convenient and simple recipe for reproducing different forms of conditional control under a single framework, with a single architecture and sampling procedure. We showcase these benefits in the applications of drag-based manipulation, identity-consistent generation, and spatially aligned control. |
|
Highlight
|
Poster
[ Arch 4A-E ] 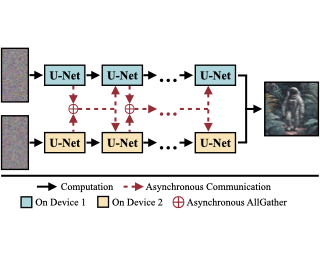
Abstract
Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose Displaced Patch Parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$\times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 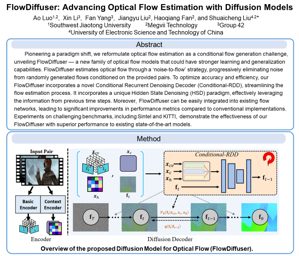
AbstractOptical flow estimation, a process of predicting pixel-wise displacement between consecutive frames, has commonly been approached as a regression task in the age of deep learning. Despite notable advancements, this de-facto paradigm unfortunately falls short in generalization performance when trained on synthetic or constrained data. Pioneering a paradigm shift, we recast optical flow estimation as a conditional flow generation challenge, unveiling FlowDiffuser --- a new family of optical flow models that could have stronger learning and generalization capabilities. FlowDiffuser estimates optical flow through a `noise-to-flow' strategy, progressively eliminating noise from randomly generated flows conditioned on the provided pairs. To optimize accuracy and efficiency, our FlowDiffuser incorporates a novel Conditional Recurrent Denoising Decoder (Conditional-RDD), streamlining the flow estimation process. It incorporates a unique Hidden State Denoising (HSD) paradigm, effectively leveraging the information from previous time steps. Moreover, FlowDiffuser can be easily integrated into existing flow networks, leading to significant improvements in performance metrics compared to conventional implementations. Experiments on challenging benchmarks, including Sintel and KITTI, demonstrate the effectiveness of our FlowDiffuser with superior performance to existing state-of-the-art models. Our code will be made publicly available upon acceptance. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractGenerating novel views of an object from a single image is a challenging task. It requires an understanding of the underlying 3D structure of the object from an image and rendering high-quality, spatially consistent new views. While recent methods for view synthesis based on diffusion have shown great progress, achieving consistency among various view estimates and at the same time abiding by the desired camera pose remains a critical problem yet to be solved. In this work, we demonstrate a strikingly simple method, where we utilize a pre-trained video diffusion model to solve this problem. Our key idea is that synthesizing a novel view could be reformulated as synthesizing a video of a camera going around the object of interest---a scanning video---which then allows us to leverage the powerful priors that a video diffusion model would have learned. Thus, to perform novel-view synthesis, we create a smooth camera trajectory to the target view that we wish to render, and denoise using both a view-conditioned diffusion model and a video diffusion model. By doing so, we obtain a highly consistent novel view synthesis, outperforming the state of the art. |
|
Highlight
|
Poster
[ Arch 4A-E ] 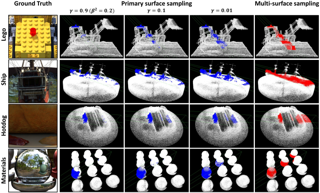
AbstractIn this paper, we address the problem of efficient point searching and sampling for volume neural rendering. Within this realm, two typical approaches are employed: rasterization and ray tracing. The rasterization-based methods enable real-time rendering at the cost of increased memory and lower fidelity. In contrast, the ray-tracing-based methods yield superior quality but demand longer rendering time. We solve this problem by our HashPoint method combining these two strategies, leveraging rasterization for efficient point searching and sampling, and ray marching for rendering. Our method optimizes point searching by rasterizing points within the camera's view, organizing them in a hash table, and facilitating rapid searches. Notably, we accelerate the rendering process by adaptive sampling on the primary surface encountered by the ray. Our approach yields substantial speed-up for a range of state-of-the-art ray-tracing-based methods, maintaining equivalent or superior accuracy across synthetic and real test datasets. The code will be available at https://jiahao-ma.github.io/hashpoint/. |
|
Highlight
|
Poster
[ Arch 4A-E ] 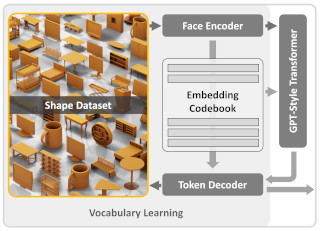
AbstractWe introduce MeshGPT, a new approach for generating triangle meshes that reflects the compactness typical of artist-created meshes, in contrast to dense triangle meshes extracted by iso-surfacing methods from neural fields. Inspired by recent advances in powerful large language models, we adopt a sequence-based approach to autoregressively generate triangle meshes as sequences of triangles. We first learn a vocabulary of latent quantized embeddings, using graph convolutions, which inform these embeddings of the local mesh geometry and topology. These embeddings are sequenced and decoded into triangles by a decoder, ensuring that they can effectively reconstruct the mesh. A transformer is then trained on this learned vocabulary to predict the index of the next embedding given previous embeddings. Once trained, our model can be autoregressively sampled to generate new triangle meshes, directly generating compact meshes with sharp edges, more closely imitating the efficient triangulation patterns of human-crafted meshes. MeshGPT demonstrates a notable improvement over state of the art mesh generation methods, with a 9% increase in shape coverage and a 30-point enhancement in FID scores across various categories. |
|
Highlight
|
Poster
[ Arch 4A-E ] 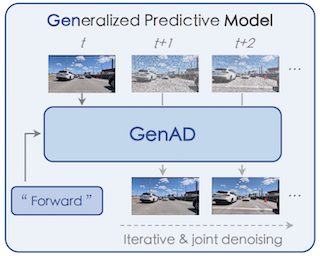
AbstractIn this paper, we introduce the first large-scale video prediction model in the autonomous driving discipline. To eliminate the restriction of high-cost data collection and empower the generalization ability of our model, we acquire massive data from the web and pair it with diverse and high-quality text descriptions. The resultant dataset accumulates over 2000 hours of driving videos, spanning areas all over the world with diverse weather conditions and traffic scenarios. Inheriting the merits from recent latent diffusion models, our model, dubbed GenAD, handles the challenging dynamics in driving scenes with novel temporal reasoning blocks. We showcase that it can generalize to various unseen driving datasets in a zero-shot manner, surpassing general or driving-specific video prediction counterparts. Furthermore, GenAD can be adapted into an action-conditioned prediction model or a motion planner, holding great potential for real-world driving applications. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe present the content deformation field (CoDeF) as a new type of video representation, which consists of a canonical content field aggregating the static contents in the entire video and a temporal deformation field recording the transformations from the canonical image (i.e., rendered from the canonical content field) to each individual frame along the time axis. Given a target video, these two fields are jointly optimized to reconstruct it through a carefully tailored rendering pipeline. We advisedly introduce some regularizations into the optimization process, urging the canonical content field to inherit semantics (e.g., the object shape) from the video. With such a design, CoDeF naturally supports lifting image algorithms for video processing, in the sense that one can apply an image algorithm to the canonical image and effortlessly propagate the outcomes to the entire video with the aid of the temporal deformation field. We experimentally show that CoDeF is able to lift image-to-image translation to video-to-video translation and lift keypoint detection to keypoint tracking without any training. More importantly, thanks to our lifting strategy that deploys the algorithms on only one image, we achieve superior cross-frame consistency in processed videos compared to existing video-to-video translation approaches, and even manage to … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractRealistic 3D human generation from text prompts is a desirable yet challenging task. Existing methods optimize 3D representations like mesh or neural fields via score distillation sampling (SDS), which suffers from inadequate fine details or excessive training time. In this paper, we propose an efficient yet effective framework, HumanGaussian, that generates high-quality 3D humans with fine-grained geometry and realistic appearance. Our key insight is that 3D Gaussian Splatting is an efficient renderer with periodic Gaussian shrinkage or growing, where such adaptive density control can be naturally guided by intrinsic human structures. Specifically, 1) we first propose a Structure-Aware SDS that simultaneously optimizes human appearance and geometry. The multi-modal score function from both RGB and depth space is leveraged to distill the Gaussian densification and pruning process. 2) Moreover, we devise an Annealed Negative Prompt Guidance by decomposing SDS into a noisier generative score and a cleaner classifier score, which well addresses the over-saturation issue. The floating artifacts are further eliminated based on Gaussian size in a prune-only phase to enhance generation smoothness. Extensive experiments demonstrate the superior efficiency and competitive quality of our framework, rendering vivid 3D humans under diverse scenarios. |
|
Highlight
|
Poster
[ Arch 4A-E ] 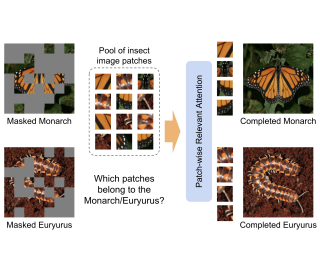
AbstractIn precision agriculture, the detection and recognition of insects play an essential role in the ability of crops to grow healthy and produce a high-quality yield. The current machine vision model requires a large volume of data to achieve high performance. However, there are approximately 5.5 million different insect species in the world. None of the existing insect datasets can cover even a fraction of them due to varying geographic locations and acquisition costs. In this paper, we introduce a novel ``Insect-1M'' dataset, a game-changing resource poised to revolutionize insect-related foundation model training. Covering a vast spectrum of insect species, our dataset, including 1 million images with dense identification labels of taxonomy hierarchy and insect descriptions, offers a panoramic view of entomology, enabling foundation models to comprehend visual and semantic information about insects like never before. Then, to efficiently establish an Insect Foundation Model, we develop a micro-feature self-supervised learning method with a Patch-wise Relevant Attention mechanism capable of discerning the subtle differences among insect images. In addition, we introduce Description Consistency loss to improve micro-feature modeling via insect descriptions. Through our experiments, we illustrate the effectiveness of our proposed approach in insect modeling and achieve State-of-the-Art performance on standard … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractUnsupervised object-centric learning aims to decompose scenes into interpretable object entities, termed slots. Slot-based auto-encoders stand out as a prominent method for this task. Within them, crucial aspects include guiding the encoder to generate object-specific slots and ensuring the decoder utilizes them during reconstruction. This work introduces two novel techniques, (i) an attention-based self-training approach, which distills superior slot-based attention masks from the decoder to the encoder, enhancing object segmentation, and (ii) an innovative patch-order permutation strategy for autoregressive transformers that strengthens the role of slot vectors in reconstruction. The effectiveness of these strategies is showcased experimentally. The combined approach significantly surpasses prior slot-based autoencoder methods in unsupervised object segmentation, especially with complex real-world images. We provide the implementation code at https://github.com/gkakogeorgiou/spot. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractSemantic segmentation has innately relied on extensive pixel-level annotated data, leading to the emergence of unsupervised methodologies. Among them, leveraging self-supervised Vision Transformers for unsupervised semantic segmentation (USS) has been making steady progress with expressive deep features. Yet, for semantically segmenting images with complex objects, a predominant challenge remains: the lack of explicit object-level semantic encoding in patch-level features. This technical limitation often leads to inadequate segmentation of complex objects with diverse structures. To address this gap, we present a novel approach, EAGLE, which emphasizes object-centric representation learning for unsupervised semantic segmentation. Specifically, we introduce EiCue, a spectral technique providing semantic and structural cues through an eigenbasis derived from the semantic similarity matrix of deep image features and color affinity from an image. Further, by incorporating our object-centric contrastive loss with EiCue, we guide our model to learn object-level representations with intra- and inter-image object-feature consistency, thereby enhancing semantic accuracy. Extensive experiments on COCO-Stuff, Cityscapes, and Potsdam-3 datasets demonstrate the state-of-the-art USS results of EAGLE with accurate and consistent semantic segmentation across complex scenes. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractMusic recommendation for videos attracts growing interest in multi-modal research. However, existing systems focus primarily on content compatibility, often ignoring the users' preferences. Their inability to interact with users for further refinements or to provide explanations leads to a less satisfying experience. We address these issues with MuseChat, a first-of-its-kind dialogue-based recommendation system that personalizes music suggestions for videos. Our system consists of two key functionalities with associated modules: recommendation and reasoning. The recommendation module takes a video along with optional information including previous suggested music and user's preference as inputs and retrieves an appropriate music matching the context. The reasoning module, equipped with the power of Large Language Model (Vicuna-7B) and extended to multi-modal inputs, is able to provide reasonable explanation for the recommended music. To evaluate the effectiveness of MuseChat, we build a large-scale dataset, conversational music recommendation for videos, that simulates a two-turn interaction between a user and a recommender based on accurate music track information. Experiment results show that MuseChat achieves significant improvements over existing video-based music retrieval methods as well as offers strong interpretability and interactability. The dataset of this work is available at https://dongzhikang.github.io/musechat. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
The Diffusion model, a prevalent framework for image generation, encounters significant challenges in terms of broad applicability due to its extended inference times and substantial memory requirements. Efficient Post-training Quantization (PTQ) is pivotal for addressing these issues in traditional models. Different from traditional models, diffusion models heavily depend on the time-step $t$ to achieve satisfactory multi-round denoising. Usually, $t$ from the finite set $\\{1, \ldots, T\\}$ is encoded to a temporal feature by a few modules totally irrespective of the sampling data. However, existing PTQ methods do not optimize these modules separately. They adopt inappropriate reconstruction targets and complex calibration methods, resulting in a severe disturbance of the temporal feature and denoising trajectory, as well as a low compression efficiency. To solve these, we propose a Temporal Feature Maintenance Quantization (TFMQ) framework building upon a Temporal Information Block which is just related to the time-step $t$ and unrelated to the sampling data. Powered by the pioneering block design, we devise temporal information aware reconstruction (TIAR) and finite set calibration (FSC) to align the full-precision temporal features in a limited time. Equipped with the framework, we can maintain the most temporal information and ensure the end-to-end generation quality. Extensive experiments on …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractIn pursuit of developing a robust ULD framework, we explore the potential of a recent paradigm of self-supervised learning algorithms, known as diffusion models. Some recent works have shown that these models implicitly contain important correspondence cues. Towards harnessing the potential of diffusion models for the ULD task, we make the following core contributions. First, we propose a ZeroShot ULD baseline based on simple clustering of random pixel locations with nearest neighbour matching. It delivers better results than existing ULD methods. Second, motivated by the ZeroShot performance, we develop a ULD algorithm based on diffusion features using self-training and clustering which also outperforms prior methods by notable margins. Third, we introduce a new proxy task based on generating latent pose codes and also propose a two-stage clustering to facilitate effective pseudo-labeling, resulting in a significant performance improvement. Overall, our approach consistently outperforms state-of-the-art methods on four challenging benchmarks AFLW, MAFL, CatHeads and LS3D by significant margins. |
|
Highlight
|
Poster
[ Arch 4A-E ] 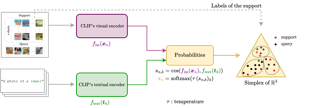
Abstract
Transductive inference has been widely investigated in few-shot image classification, but completely overlooked in the recent, fast growing literature on adapting vision-langage models like CLIP. This paper addresses the transductive zero-shot and few-shot CLIP classification challenge, in which inference is performed jointly across a mini-batch of unlabeled query samples, rather than treating each instance independently. We initially construct informative vision-text probability features, leading to a classification problem on the unit simplex set. Inspired by Expectation-Maximization (EM), our optimization-based classification objective models the data probability distribution for each class using a Dirichlet law. The minimization problem is then tackled with a novel block Majorization-Minimization algorithm, which simultaneously estimates the distribution parameters and class assignments. Extensive numerical experiments on 11 datasets underscore the benefits and efficacy of our batch inference approach.On zero-shot tasks with test batches of 75 samples, our approach yields near 20$\%$ improvement in ImageNet accuracy over CLIP's zero-shot performance. Additionally, we outperform state-of-the-art methods in the few-shot setting. The code is available at: \url{https://github.com/SegoleneMartin/transductive-CLIP}.
|
|
Highlight
|
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
Poster
[ Arch 4A-E ] AbstractLarge Vision-Language Models (LVLMs) have advanced considerably, intertwining visual recognition and language understanding to generate content that is not only coherent but also contextually attuned. Despite their success, LVLMs still suffer from the issue of object hallucinations, where models generate plausible yet incorrect outputs that include objects that do not exist in the images. To mitigate this issue, we introduce Visual Contrastive Decoding (VCD), a simple and training-free method that contrasts output distributions derived from original and distorted visual inputs. The proposed VCD effectively reduces the over-reliance on statistical bias and unimodal priors, two essential causes of object hallucinations. This adjustment ensures the generated content is closely grounded to visual inputs, resulting in contextually accurate outputs. Our experiments show that VCD, without either additional training or the usage of external tools, significantly mitigates the object hallucination issue across different LVLM families. Beyond mitigating object hallucinations, VCD also excels in general LVLM benchmarks, highlighting its wide-ranging applicability. Codes will be released. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Existing Knowledge Distillation (KD) methods typically focus on transferring knowledge from a large-capacity teacher to a low-capacity student model, achieving substantial success in unimodal knowledge transfer. However, existing methods can hardly be extended to Cross-Modal Knowledge Distillation (CMKD), where the knowledge is transferred from a teacher modality to a different student modality, with inference only on the distilled student modality. We empirically reveal that the modality gap, i.e., modality imbalance and soft label misalignment, incurs the ineffectiveness of traditional KD in CMKD. As a solution, we propose a novel \textbf{\underline{C}}ustomized \textbf{\underline{C}}rossmodal \textbf{\underline{K}}nowledge \textbf{\underline{D}}istillation (C$^2$KD). Specifically, to alleviate the modality gap, the pre-trained teacher performs bidirectional distillation with the student to provide customized knowledge. The On-the-Fly Selection Distillation(OFSD) strategy is applied to selectively filter out the samples with misaligned soft labels, where we distill cross-modal knowledge from non-target classes to avoid the modality imbalance issue. To further provide receptive cross-modal knowledge, proxy student and teacher, inheriting unimodal and cross-modal knowledge, is formulated to progressively transfer cross-modal knowledge through bidirectional distillation. Experimental results on audio-visual, image-text, and RGB-depth datasets demonstrate that our method can effectively transfer knowledge across modalities, achieving superior performance against traditional KD by a large margin.
|
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractMultimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient maintenance, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges.To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the \textbf{MMSum} dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning.(2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios.(3) Benchmark tests performed on the proposed dataset to assess various tasks and methods, including \textit{video summarization}, \textit{text summarization}, and \textit{multimodal summarization}. To champion accessibility and collaboration, we will release the \textbf{MMSum} dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments. |
|
Highlight
|
Poster
[ Arch 4A-E ] 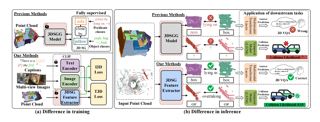
Abstract3D Scene Graph Generation (3DSGG) aims to classify objects and their predicates within 3D point cloud scenes. However, current 3DSGG methods struggle with two main challenges. 1) The dependency on labor-intensive ground-truth annotations. 2) Closed-set classes training hampers the recognition of novel objects and predicates. Addressing these issues, our idea is to extract cross-modality features by CLIP from text and image data naturally related to 3D point clouds. Cross-modality features are used to train a robust 3D scene graph (3DSG) feature extractor. Specifically, we propose a novel Cross-Modality Contrastive Learning 3DSGG (CCL-3DSGG) method. Firstly, to align the text with 3DSG, the text is parsed into word level that are consistent with the 3DSG annotation. To enhance robustness during the alignment, adjectives are exchanged for different objects as negative samples. Then, to align the image with 3DSG, the camera view is treated as a positive sample and other views as negatives. Lastly, the recognition of novel object and predicate classes is achieved by calculating the cosine similarity between prompts and 3DSG features. Our rigorous experiments confirm the superior open-vocabulary capability and applicability of CCL-3DSGG in real-world contexts, both indoors and outdoors. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractStrong adversarial examples are crucial for evaluating and enhancing the robustness of deep neural networks. However, the performance of popular attacks is usually sensitive, for instance, to minor image transformations, stemming from limited information — typically only one input example, a handful of white-box source models, and undefined defense strategies. Hence, the crafted adversarial examples are prone to overfit the source model, which hampers their transferability to unknown architectures. In this paper, we propose an approach named Multiple Asymptotically Normal Distribution Attacks (MultiANDA) which explicitly characterize adversarial perturbations from a learned distribution. Specifically, we approximate the posterior distribution over the perturbations by taking advantage of the asymptotic normality property of stochastic gradient ascent (SGA), then employ the deep ensemble strategy as an effective proxy for Bayesian marginalization in this process, aiming to estimate a mixture of Gaussians that facilitates a more thorough exploration of the potential optimization space. The approximated posterior essentially describes the stationary distribution of SGA iterations, which captures the geometric information around the local optimum. Thus, MultiANDA allows drawing an unlimited number of adversarial perturbations for each input and reliably maintains the transferability. Our proposed method outperforms ten state-of-the-art black-box attacks on deep learning models with or … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
We present an approach to pose object recognition as next token prediction.The idea is to apply a language decoder that auto-regressively predicts the text tokens from image embeddings to form labels.To ground this prediction process in auto-regression, we customize a non-causal attention mask for the decoder, incorporating two key features: modeling tokens from different labels to be independent, and treating image tokens as a prefix.This masking mechanism inspires an efficient method $-$ one-shot sampling $-$ to simultaneously sample tokens of multiple labels in parallel and rank generated labels by their probabilities during inference.To further enhance the efficiency, we propose a simple strategy to construct a compact decoder by simply discarding the intermediate blocks of a pretrained language model.This approach yields a decoder that matches the full model's performance while being notably more efficient.The code is available at [github.com/nxtp](https://github.com/kaiyuyue/nxtp).
|
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractThis paper addresses the challenge of learning a local visual pattern of an object from one image, and generating images depicting objects with that pattern.Learning a localized concept and placing it on an object in a target image is a nontrivial task, as the objects may have different orientations and shapes.Our approach builds upon recent advancements in visual concept learning. It involves acquiring a visual concept (e.g., an ornament) from a source image and subsequently applying it to an object (e.g., a chair) in a target image.Our key idea is to perform in-context concept learning, acquiring the local visual concept within the broader context of the objects they belong to. To localize the concept learning, we employ soft masks that contain both the concept within the mask and the surrounding image area. We demonstrate our approach through object generation within an image, showcasing plausible embedding of in-context learned concepts.We also introduce methods for directing acquired concepts to specific locations within target images, employing cross-attention mechanisms, and establishing correspondences between source and target objects. The effectiveness of our method is demonstrated through quantitative and qualitative experiments, along with comparisons against baseline techniques. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe developed a tool for visualizing and analyzing large pre-trained vision models by mapping them onto the brain, thus exposing their hidden inside. Our innovation arises from a surprising usage of brain encoding: predicting brain fMRI measurements in response to images. We report two findings. First, explicit mapping between the brain and deep-network features across dimensions of space, layers, scales, and channels is crucial. This mapping method, FactorTopy, is plug-and-play for any deep-network; with it, one can paint a picture of the network onto the brain (literally!). Second, our visualization shows how different training methods matter: they lead to remarkable differences in hierarchical organization and scaling behavior, growing with more data or network capacity. It also provides insight into finetuning: how pre-trained models change when adapting to small datasets. Our method is practical: only 3K images are enough to learn a network-to-brain mapping. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDilated convolution, which expands the receptive field by inserting gaps between its consecutive elements, is widely employed in computer vision. In this study, we propose three strategies to improve individual phases of dilated convolution from the view of spectrum analysis. Departing from the conventional practice of fixing a global dilation rate as a hyperparameter, we introduce Frequency-Adaptive Dilated Convolution (FADC) which dynamically adjusts dilation rates spatially based on local frequency components. Subsequently, we design two plug-in modules to directly enhance effective bandwidth and receptive field size.The Adaptive Kernel (AdaKern) module decomposes convolution weights into low-frequency and high-frequency components, dynamically adjusting the ratio between these components on a per-channel basis. By increasing the high-frequency part of convolution weights, AdaKern captures more high-frequency components, thereby improving effective bandwidth.The Frequency Selection (FreqSelect) module optimally balances high- and low-frequency components in feature representations through spatially variant reweighting. It suppresses high frequencies in the background to encourage FADC to learn a larger dilation, thereby increasing the receptive field for an expanded scope. Extensive experiments on segmentation and object detection consistently validate the efficacy of our approach. The code is made publicly available at https://github.com/Linwei-Chen/FADC. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDespite exciting progress in automatic 3D reconstruction from images, excessive and irregular triangular faces in the resulting meshes still constitute a significant challenge when it comes to adoption in practical artist workflows. Therefore, we propose a method to extract regular quad-dominant meshes from posed images. More specifically, we generate a high-quality 3D model through decomposition into an easily editable quad-dominant mesh with pixel-level details such as displacement, materials, and lighting. To enable end-to-end learning of shape and quad topology, we QUADify a neural implicit representation using our novel differentiable re-meshing objective. Distinct from previous work, our method exploits artifact-free Catmull-Clark subdivision combined with vertex displacement to extract pixel-level details linked to the base geometry. Finally, we apply differentiable rendering techniques for material and lighting decomposition to optimize for image reconstruction. Our experiments show the benefits of end-to-end re-meshing and that our method yields state-of-the-art geometric accuracy while providing lightweight meshes with displacements and textures that are directly compatible with professional renderers and game engines. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractInteractive Segmentation (IS) segments specific objects or parts in the image according to user input. Current IS pipelines fall into two categories: single-granularity output and multi-granularity output. The latter aims to alleviate the spatial ambiguity present in the former. However, the multi-granularity output pipeline suffers from limited interaction flexibility and produces redundant results. In this work, we introduce Granularity-Controllable Interactive Segmentation (GraCo), a novel approach that allows precise control of prediction granularity by introducing additional parameters to input. This enhances the customization of the interactive system and eliminates redundancy while resolving ambiguity. Nevertheless, the exorbitant cost of annotating multi-granularity masks and the lack of available datasets with granularity annotations make it difficult for models to acquire the necessary guidance to control output granularity. To address this problem, we design an any-granularity mask generator that exploits the semantic property of the pre-trained IS model to automatically generate abundant mask-granularity pairs without requiring additional manual annotation. Based on these pairs, we propose a granularity-controllable learning strategy that efficiently imparts the granularity controllability to the IS model. Extensive experiments on intricate scenarios at object and part levels demonstrate that our GraCo has significant advantages over previous methods. This highlights the potential of GraCo … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractThe capacity of existing human keypoint localization models is limited by keypoint priors provided by the training data. To alleviate this restriction and pursue more general model, this work studies keypoint localization from a different perspective by reasoning locations based on keypiont clues in text descriptions. We propose LocLLM, the first Large-Language Model (LLM) based keypoint localization model that takes images and text instructions as inputs and outputs the desired keypoint coordinates.LocLLM leverages the strong reasoning capability of LLM and clues of keypoint type, location, and relationship in textual descriptions for keypoint localization. To effectively tune LocLLM, we construct localization-based instruction conversations to connect keypoint description with corresponding coordinates in input image, and fine-tune the whole model in a parameter-efficient training pipeline. LocLLM shows remarkable performance on standard 2D/3D keypoint localization benchmarks. Moreover, incorporating language clues into the localization makes LocLLM show superior flexibility and generalizable capability in cross dataset keypoint localization, and even detecting novel type of keypoints unseen during training. We will release the model and code for further research and evaluation. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractDespite diffusion models' superior capabilities in modeling complex distributions, there are still non-trivial distributional discrepancies between generated and ground-truth images, which has resulted in several notable problems in image generation, including missing object errors in text-to-image generation and low image quality. Existing methods that attempt to address these problems mostly do not tend to address the fundamental cause behind these problems, which is the distributional discrepancies, and hence achieve sub-optimal results. In this paper, we propose a particle filtering framework that can effectively address both problems by explicitly reducing the distributional discrepancies. Specifically, our method relies on a set of external guidance, including a small set of real images and a pre-trained object detector, to gauge the distribution gap, and then design the resampling weight accordingly to correct the gap. Experiments show that our methods can effectively correct missing object errors and improve image quality in various image generation tasks. Notably, our method outperforms the existing strongest baseline by 5% in object occurrence and 1.0 in FID on MS-COCO. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
We study visually grounded VideoQA in response to the emerging trends of utilizing pretraining techniques for video-language understanding. Specifically, by forcing vision-language models (VLMs) to answer questions and simultaneously provide visual evidence, we seek to ascertain the extent to which the predictions of such techniques are genuinely anchored in relevant video content, versus spurious correlations from language or irrelevant visual context. Towards this, we construct NExT-GQA -- an extension of NExT-QA with 10.5$K$ temporal grounding (or location) labels tied to the original QA pairs. With NExT-GQA, we scrutinize a series of state-of-the-art VLMs. Through post-hoc attention analysis, we find that these models are extremely weak in substantiating the answers despite their strong QA performance. This exposes the limitation of current VLMs in making reliable predictions. As a remedy, we further explore and propose a grounded-QA method via Gaussian mask optimization and cross-modal learning. Experiments with different backbones demonstrate that this grounding mechanism improves both grounding and QA. Our dataset and code will be released. With these efforts, we aim to push towards trustworthy VLMs in VQA systems.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractIn video super-resolution, it is common to use a frame-wise alignment to support the propagation of information over time. The role of alignment is well-studied for low-level enhancement in video, but existing works overlook a critical step -- resampling. We show through extensive experiments that for alignment to be effective, the resampling should preserve the reference frequency spectrum while minimizing spatial distortions. However, most existing works simply use a default choice of bilinear interpolation for resampling even though bilinear interpolation has a smoothing effect and hinders super-resolution. From these observations, we propose an implicit resampling-based alignment. The sampling positions are encoded by a sinusoidal positional encoding, while the value is estimated with a coordinate network and a window-based cross-attention. We show that bilinear interpolation inherently attenuates high-frequency information while an MLP-based coordinate network can approximate more frequencies. Experiments on synthetic and real-world datasets show that alignment with our proposed implicit resampling enhances the performance of state-of-the-art frameworks with minimal impact on both compute and parameters. |
|
Highlight
|
Poster
[ Arch 4A-E ] 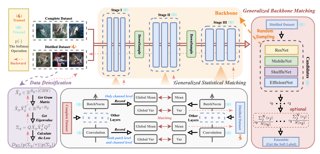
Abstract
The lightweight "local-match-global" matching introduced by SRe2L successfully creates a distilled dataset with comprehensive information on the full 224$\times$224 ImageNet-1k. However, this one-sided approach is limited to a particular backbone, layer, and statistics, which limits the improvement of the generalization of a distilled dataset. We suggest that sufficient and various "local-match-global" matching are more precise and effective than a single one and has the ability to create a distilled dataset with richer information and better generalization. We call this perspective "generalized matching" and propose Generalized Various Backbone and Statistical Matching (G-VBSM) in this work, which aims to create a synthetic dataset with densities, ensuring consistency with the complete dataset across various backbones, layers, and statistics. As experimentally demonstrated, G-VBSM is the first algorithm to obtain strong performance across both small-scale and large-scale datasets. Specifically, G-VBSM achieves a performance of 38.7% on CIFAR-100 with 128-width ConvNet, 47.6% on Tiny-ImageNet with ResNet18, and 31.4% on the full 224$\times$224 ImageNet-1k with ResNet18, under images per class (IPC) 10, 50, and 10, respectively. These results surpass all SOTA methods by margins of 3.9%, 6.5%, and 10.1%, respectively.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractSynthesizing realistic videos of talking faces under custom lighting conditions and viewing angles benefits various downstream applications like video conferencing. However, most existing relighting methods are either time-consuming or unable to adjust the viewpoints. In this paper, we present the first real-time 3D-aware method for relighting in-the-wild videos of talking faces based on Neural Radiance Fields (NeRF). Given an input portrait video, our method can synthesize talking faces under both novel views and novel lighting conditions with a photo-realistic and disentangled 3D representation. Specifically, we infer an albedo tri-plane, as well as a shading tri-plane based on a desired lighting condition for each video frame with fast dual-encoders. We also leverage a temporal consistency network to ensure smooth transitions and reduce flickering artifacts. Our method runs at 32.98 fps on consumer-level hardware and achieves state-of-the-art results in terms of reconstruction quality, lighting error, lighting instability, temporal consistency and inference speed. We demonstrate the effectiveness and interactivity of our method on various portrait videos with diverse lighting and viewing conditions. |
|
Highlight
|
Poster
[ Arch 4A-E ] 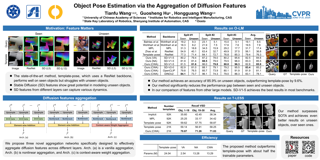
AbstractEstimating the pose of objects from images is a crucial task of 3D scene understanding, and recent approaches have shown promising results on very large benchmarks. However, these methods experience a significant performance drop when dealing with unseen objects. We believe that it results from the limited generalizability of image features. To address this problem, we have an in-depth analysis on the features of diffusion models, e.g. Stable Diffusion, which hold substantial potential for modeling unseen objects. Based on this analysis, we then innovatively introduce these diffusion features for object pose estimation. To achieve this, we propose three distinct architectures that can effectively capture and aggregate diffusion features of different granularity, greatly improving the generalizability of object pose estimation. Our approach outperforms the state-of-the-art methods by a considerable margin on three popular benchmark datasets, LM, O-LM, and T-LESS. In particular, our method achieves higher accuracy than the previous best arts on unseen objects: 98.2% vs. 93.5% on Unseen LM, 85.9% vs. 76.3% on Unseen O-LM, showing the strong generalizability of our method. |
|
Highlight
|
Poster
[ Arch 4A-E ] 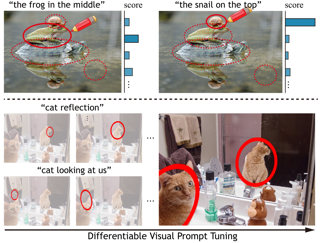
AbstractVisual prompting of large vision language models such as CLIP exhibit intriguing zero-shot capabilities. A manually drawn red circle, commonly used for highlighting, can guide CLIP's attention to the surrounding region, to identify specific objects within an image. Without precise object proposals, however, it is insufficient for localization. Our novel, simple yet effective approach enables CLIP to zero-shot localize: given an image and a text prompt describing an object, we first pick an initial ellipse from uniformly distributed anchor ellipses on the image grid via visual prompting, then use three loss functions to tune the ellipse coefficients to encapsulate the target region gradually. This yields promising experimental results for referring expression comprehension without precisely specified object proposals. In addition, we systematically present the limitations of visual prompting inherent in CLIP and discuss potential avenues for improvement. Code will be released. |
|
Highlight
|
Poster
[ Arch 4A-E ] 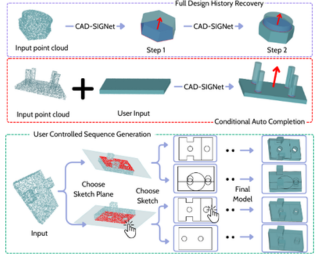
AbstractReverse engineering in the realm of Computer-Aided Design (CAD) has been a longstanding aspiration, though not yet entirely realized. Its primary aim is to uncover the CAD process behind a physical object given its 3D scan. We propose CAD-SIGNet, an end-to-end trainable and auto-regressive architecture to recover the design history of a CAD model represented as a sequence of sketch-and-extrusion from an input point cloud. Our model learns visual-language representations by layer-wise cross-attention between point cloud and CAD language embedding. In particular, a new Sketch instance Guided Attention (SGA) module is proposed in order to reconstruct the fine-grained details of the sketches. Thanks to its auto-regressive nature, CAD-SIGNet not only reconstructs a unique full design history of the corresponding CAD model given an input point cloud but also provides multiple plausible design choices. This allows for an interactive reverse engineering scenario by providing designers with multiple next step choices along with the design process. Extensive experiments on publicly available CAD datasets showcase the effectiveness of our approach against existing baseline models in two settings, namely, full design history recovery and conditional auto-completion from point clouds. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractRecently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] 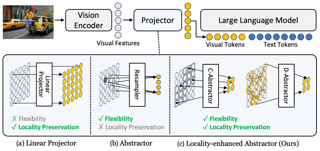
AbstractIn Multimodal Large Language Models (MLLMs), a visual projector plays a crucial role in bridging pre-trained vision encoders with LLMs, enabling profound visual understanding while harnessing the LLMs' robust capabilities. Despite the importance of the visual projector, it has been relatively less explored. In this study, we first identify two essential projector properties: (i) flexibility in managing the number of visual tokens, crucial for MLLMs' overall efficiency, and (ii) preservation of local context from visual features, vital for spatial understanding. Based on these findings, we propose a novel projector design that is both flexible and locality-enhanced, effectively satisfying the two desirable properties. Additionally, we present comprehensive strategies to effectively utilize multiple and multifaceted instruction datasets. Through extensive experiments, we examine the impact of individual design choices. Finally, our proposed MLLM, Honeybee, remarkably outperforms previous state-of-the-art methods across various benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench, achieving significantly higher efficiency. We will release the code and model publicly available. |
|
Highlight
|
Poster
[ Arch 4A-E ] 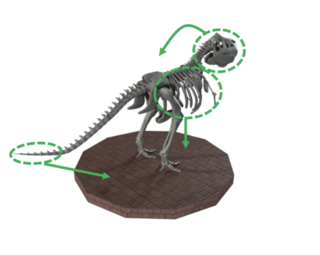
AbstractThis work proposes a novel representation of injective deformations of 3D space, which overcomes existing limitations of injective methods, namely inaccuracy, lack of robustness, and incompatibility with general learning and optimization frameworks. Our core idea is to reduce the problem to a ``deep'' composition of multiple 2D mesh-based piecewise-linear maps. Namely, we build differentiable layers that produce mesh deformations through Tutte's embedding (guaranteed to be injective in 2D), and compose these layers over different planes to create complex 3D injective deformations of the 3D volume. We show that our method provides the ability to efficiently and accurately optimize and learn complex deformations, outperforming other injective approaches. As a main application, we show our ability to produce complex and artifact-free NeRF deformations. |
|
Highlight
|
Poster
[ Arch 4A-E ] 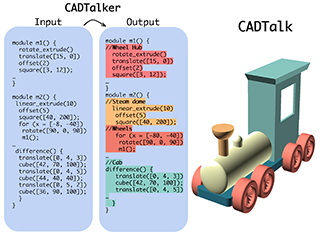
AbstractCAD programs are a popular way to compactly encode shapes as a sequence of operations that are easy to parametrically modify. However, without sufficient semantic comments and structure, such programs can be challenging to understand, let alone modify. We introduce the problem of semantic commenting CAD programs, wherein the goal is to segment the input program into code blocks corresponding to semantically meaningful shape parts and assign a semantic label to each block. We solve the problem by combining program parsing with visual-semantic analysis afforded by recent advances in foundational language and vision models. Specifically, by executing the input programs, we create shapes, which we use to generate conditional photorealistic images to make use of semantic annotators for such images. We then distill the information across the images and link back to the original programs to semantically comment on them. Additionally, we collected and annotated a benchmark dataset, CADTalk, consisting of 5,288 machine-made programs and 45 human-made programs with ground truth semantic comments. We extensively evaluated our approach, compared it to a GPT-based baseline, and an open-set shape segmentation baseline, and reported an 83.24% accuracy on the new CADTalk dataset. Code and data: https://enigma-li.github.io/CADTalk/. |
|
Highlight
|
Poster
[ Arch 4A-E ] 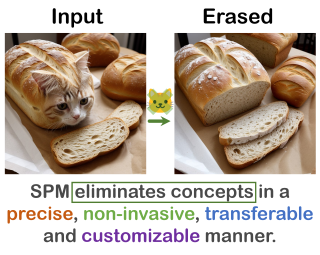
Abstract
The prevalent use of commercial and open-source diffusion models (DMs) for text-to-image generation prompts the risk mitigation to prevent undesired behaviors. Existing concept erasing methods in academia are all based on full parameter or specification-based fine-tuning, from which we observe following issues: 1) Generation alternation towards erosion: Parameter drift during target elimination causes alternations and potential deformations across all generations, even eroding other concepts at varying degrees, which is more evident with multi-concept erasing; 2) Transfer inability \& deployment inefficiency: Previous model-specific erasure impedes the flexible combination of concepts and the training-free transfer towards other models, resulting in linear cost growth as the deployment scenarios increase.To achieve non-invasive, precise, customizable and transferable elimination, we ground our erasing framework on one-dimensional adapters to erase multiple concepts from most of DMs at once across versatile erasing applications. The concept-SemiPermeable structure is injected as a Membrane (SPM) into any DM to learn targeted erasing, and meantime the alteration and erosion phenomenon is effectively minimized via a novel Latent Anchoring fine-tuning strategy. Once obtained, SPMs can be flexibly combined and plug-and-play for other DMs without specific re-tuning, enabling timely and efficient adaptation to diverse scenarios. During generation, our Facilitated Transport mechanism dynamically regulates the …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 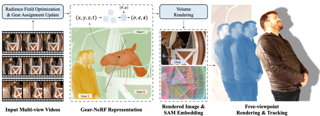
AbstractExtensions of Neural Radiance Fields (NeRFs) to model dynamic scenes have enabled their near photo-realistic, free-viewpoint rendering. Although these methods have shown some potential in creating immersive experiences, two drawbacks limit their ubiquity: (i) a significant reduction in reconstruction quality when the computing budget is limited, and (ii) a lack of semantic understanding of the underlying scenes. To address these issues, we introduce Gear-NeRF, which leverages semantic information from powerful image segmentation models. Our approach presents a principled way for learning a spatio-temporal (4D) semantic embedding, based on which we introduce the concept of gears to allow for stratified modeling of dynamic regions of the scene based on the extent of their motion. Such differentiation allows us to adjust the spatio-temporal sampling resolution for each region in proportion to its motion scale, achieving more photo-realistic dynamic novel view synthesis. At the same time, almost for free, our approach enables free-viewpoint tracking of objects of interest -- a functionality not yet achieved by existing NeRF-based methods. Empirical studies validate the effectiveness of our method, where we achieve state-of-the-art rendering and tracking performance on multiple challenging datasets. The project page is available at: https://merl.com/research/highlights/gear-nerf. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractRecent approaches to point tracking are able to recover the trajectory of any scene point through a large portion of a video despite the presence of occlusions.They are, however, too slow in practice to track every point observed in a single frame in a reasonable amount of time.This paper introduces DOT, a novel, simple and efficient method for solving this problem.It first extracts a small set of tracks from key regions at motion boundaries using an off-the-shelf point tracking algorithm.Given source and target frames, DOT then computes rough initial estimates of a dense flow field and visibility mask through nearest-neighbor interpolation, before refining them using a learnable optical flow estimator that explicitly handles occlusions and can be trained on synthetic data with ground-truth correspondences.We show that DOT is significantly more accurate than current optical flow techniques, outperforms sophisticated ``universal'' trackers like OmniMotion, and is on par with, or better than, the best point tracking algorithms like CoTracker while being at least two orders of magnitude faster.Quantitative and qualitative experiments with synthetic and real videos validate the promise of the proposed approach. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractLearning-based isosurface extraction methods have recently emerged as a robust and efficient alternative to axiomatic techniques. However, the vast majority of such approaches rely on supervised training with axiomatically computed ground truths, thus potentially inheriting biases and data artefacts of the corresponding axiomatic methods. Steering away from such dependencies, we propose a self-supervised training scheme to the Neural Dual Contouring meshing framework, resulting in our method: Self-Supervised Dual Contouring (SDC). Instead of optimizing predicted mesh vertices with supervised training we use two novel self-supervised loss functions which encourage the consistency between distances to the generated mesh and the given input SDF, and align corresponding face normals. Meshes reconstructed by SDC not only exhibit an improved consistency with the input SDFs but also surpass existing data-driven methods in capturing intricate details, while being more robust to possible irregularities in the input. Furthermore, we use the same self-supervised training objective linking inferred mesh and input SDF, to regualize the training process of Deep Implicit Networks (DINs). We demonstrate that the resulting DINs produce higher quality implicit functions, ultimately leading to more accurate and detail-preserving surfaces compared to prior baselines for different input modalities. Finally, we demonstrate that our self-supervised losses improve meshing … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractEvent cameras, with their high temporal and dynamic range and minimal memory usage, have found applications in various fields. However, their potential in static traffic monitoring remains largely unexplored. To facilitate this exploration, we present eTraM - a first-of-its-kind, fully event-based traffic monitoring dataset. eTraM offers 10 hr of data from different traffic scenarios in various lighting and weather conditions, providing a comprehensive overview of real-world situations. Providing 2M bounding box annotations, it covers eight distinct classes of traffic participants, ranging from vehicles to pedestrians and micro-mobility. eTraM's utility has been assessed using state-of-the-art methods for traffic participant detection, including RVT, RED, and YOLOv8. We quantitatively evaluate the ability of event-based models to generalize on nighttime and unseen scenes. Our findings substantiate the compelling potential of leveraging event cameras for traffic monitoring, opening new avenues for research and application. eTraM is available at https://eventbasedvision.github.io/eTraM. |
|
Highlight
|
Poster
[ Arch 4A-E ] 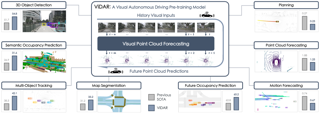
AbstractIn contrast to extensive studies on general vision, pre-training for scalable visual autonomous driving remains seldom explored. Visual autonomous driving applications require features encompassing semantics, 3D geometry, and temporal information simultaneously for joint perception, prediction, and planning, posing dramatic challenges for pre-training. To resolve this, we bring up a new pre-training task termed as visual point cloud forecasting - predicting future point clouds from historical visual input. The key merit of this task captures the synergic learning of semantics, 3D structures, and temporal dynamics. Hence it shows superiority in various downstream tasks. To cope with this new problem, we present ViDAR, a general model to pre-train downstream visual encoders. It first extracts historical embeddings by the encoder. These representations are then transformed to 3D geometric space via a novel Latent Rendering operator for future point cloud prediction. Experiments demonstrate significant improvements in downstream tasks, e.g., 3.1% NDS on 3D detection, ∼10% error reduction on motion forecasting, and ∼15% less collision rate on planning. Code and models would be public. |
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
We introduce in-context matting, a novel task setting of image matting. Given a reference image of a certain foreground and guided priors such as points, scribbles, and masks, in-context matting enables automatic alpha estimation on a batch of target images of the same foreground category, without additional auxiliary input. This setting marries good performance in auxiliary input-based matting and ease of use in automatic matting, which finds a good trade-off between customization and automation. To overcome the key challenge of accurate foreground matching, we introduce IconMatting, an in-context matting model built upon a pre-trained text-to-image diffusion model. Conditioned on inter- and intra-similarity matching, IconMatting can make full use of reference context to generate accurate target alpha mattes. To benchmark the task, we also introduce a novel testing dataset ICM-$57$, covering $57$ groups of real-world images. Quantitative and qualitative results on the ICM-$57$ testing set show that IconMatting rivals the accuracy of trimap-based matting while retaining the automation level akin to automatic matting. Code is available at https://github.com/tiny-smart/in-context-matting.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe propose the problem of point-level 3D scene interpolation, which aims to reconstruct a 3D scene in two different states from multiple views, synthesize a plausible smooth point-level interpolation between the 3D scenes in the two states, and render the 3D scene at any point in time from a novel view, all without any supervision in-between the states. The primary challenge lies in producing a smooth transition between the two states which can exhibit substantial changes in geometry. To tackle it, we leverage recent advances in point renderers, which are naturally suited to representing Lagrangian motion. Our approach works by initially learning a point-based representation of the scene in its starting state, followed by finetuning this model towards the end state. Critical to achieving smooth interpolation of both the scene's geometry and appearance is the choice of the point rendering technique. Different techniques excel along different performance dimensions, and we propose leveraging the recent Proximity Attention Point Rendering (PAPR) technique, which is designed to learn point clouds from scratch and support novel view synthesis of scenes after they undergo non-rigid geometric deformations. Our method, which we dub ``PAPR in Motion'', builds on PAPR's strengths and addresses its weaknesses by developing … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
We introduce Gaussian-Flow, a novel point-based approach for fast dynamic scene reconstruction and real-time rendering from both multi-view and monocular videos. In contrast to the prevalent NeRF-based approaches hampered by slow training and rendering speeds, our approach harnesses recent advancements in point-based 3D Gaussian Splatting (3DGS). Specifically, a novel Dual-Domain Deformation Model (DDDM) is proposed to explicitly model attribute deformations of each Gaussian point, where the time-dependent residual of each attribute is captured by a polynomial fitting in the time domain, and a Fourier series fitting in the frequency domain. The proposed DDDM is capable of modeling complex scene deformations across long video footage, eliminating the need for training separate 3DGS for each frame or introducing an additional implicit neural field to model 3D dynamics. Moreover, the explicit deformation modeling for discretized Gaussian points ensures ultra-fast training and rendering of a 4D scene, which is comparable to the original 3DGS designed for static 3D reconstruction. Our proposed approach showcases a substantial efficiency improvement, achieving a $5\times$ faster training speed compared to the per-frame 3DGS modeling. In addition, quantitative results demonstrate that the proposed Gaussian-Flow significantly outperforms previous leading methods in novel view rendering quality.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 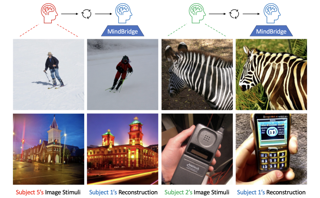
AbstractBrain decoding, a pivotal field in neuroscience, aims to reconstruct stimuli from acquired brain signals, primarily utilizing functional magnetic resonance imaging (fMRI). Currently, brain decoding is confined to a per-subject-per-model paradigm, limiting its applicability to the same individual for whom the decoding model is trained. This constraint stems from three key challenges: 1) the inherent variability in input dimensions across subjects due to differences in brain size; 2) the unique intrinsic neural patterns, influencing how different individuals perceive and process sensory information; 3) limited data availability for new subjects in real-world scenarios hampers the performance of decoding models.In this paper, we present a novel approach, MindBridge, that achieves cross-subject brain decoding by employing only one model. Our proposed framework establishes a generic paradigm capable of addressing these challenges by introducing biological-inspired aggregation function and novel cyclic fMRI reconstruction mechanism for subject-invariant representation learning. Notably, by cycle reconstruction of fMRI, MindBridge can enable novel fMRI synthesis, which also can serve as pseudo data augmentation. Within the framework, we also devise a novel reset-tuning method for adapting a pretrained model to a new subject. Experimental results demonstrate MindBridge's ability to reconstruct images for multiple subjects, which is competitive with dedicated subject-specific … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDiffusion models have achieved remarkable success in generating high-quality, diverse, and creative images. However, in text-based image generation, they often struggle to accurately capture the intended meaning of the text. For instance, a specified object might not be generated, or an adjective might incorrectly alter unintended objects. Moreover, we found that relationships indicating possession between objects are frequently overlooked. Despite the diversity of users' intentions in text, existing methods often focus on only some aspects of these intentions. In this paper, we propose Predicated Diffusion, a unified framework designed to more effectively express users' intentions. It represents the intended meaning as propositions using predicate logic and treats the pixels in attention maps as fuzzy predicates. This approach provides a differentiable loss function that offers guidance for the image generation process to better fulfill the propositions. Comparative evaluations with existing methods demonstrated that Predicated Diffusion excels in generating images faithful to various text prompts, while maintaining high image quality, as validated by human evaluators and pretrained image-text models. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present an approach for analyzing grouping information contained within a neural network's activations, permitting extraction of spatial layout and semantic segmentation from the behavior of large pre-trained vision models. Unlike prior work, our method conducts a wholistic analysis of a network's activation state, leveraging features from all layers and obviating the need to guess which part of the model contains relevant information. Motivated by classic spectral clustering, we formulate this analysis in terms of an optimization objective involving a set of affinity matrices, each formed by comparing features within a different layer. Solving this optimization problem using gradient descent allows our technique to scale from single images to dataset-level analysis, including, in the latter, both intra- and inter-image relationships. Analyzing a pre-trained generative transformer provides insight into the computational strategy learned by such models. Equating affinity with key-query similarity across attention layers yields eigenvectors encoding scene spatial layout, whereas defining affinity by value vector similarity yields eigenvectors encoding object identity. This result suggests that key and query vectors coordinate attentional information flow according to spatial proximity (a 'where' pathway), while value vectors refine a semantic category representation (a 'what' pathway). |
|
Highlight
|
Poster
[ Arch 4A-E ] 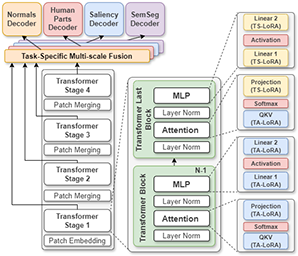
AbstractAdapting models pre-trained on large-scale datasets to a variety of downstream tasks is a common strategy in deep learning. Consequently, parameter-efficient fine-tuning methods have emerged as a promising way to adapt pre-trained models to different tasks while training only a minimal number of parameters. While most of these methods are designed for single-task adaptation, parameter-efficient training in Multi-Task Learning (MTL) architectures is still unexplored. In this paper, we introduce MTLoRA, a novel framework for parameter-efficient training for MTL models. MTLoRA employs Task-Agnostic and Task-Specific Low-Rank Adaptation modules, which effectively disentangle the parameter space in MTL fine-tuning, thereby enabling the model to adeptly handle both task specialization and interaction within MTL contexts. We applied MTLoRA to hierarchical-transformer-based MTL architectures, adapting them to multiple downstream dense prediction tasks. Our extensive experiments on the PASCAL dataset show that MTLoRA achieves higher accuracy in downstream tasks compared to fully fine-tuning the entire MTL model while training significantly fewer parameters. Furthermore, MTLoRA establishes a Pareto-optimal trade-off between the number of trainable parameters and the accuracy of the downstream tasks, outperforming current state-of-the-art parameter-efficient training methods in both accuracy and efficiency. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Look-Up Table (LUT) has recently gained increasing attention for restoring High-Quality (HQ) images from Low-Quality (LQ) observations, thanks to its high computational efficiency achieved through a ``space for time'' strategy of caching learned LQ-HQ pairs. However, incorporating multiple LUTs for improved performance comes at the cost of a rapidly growing storage size, which is ultimately restricted by the allocatable on-device cache size. In this work, we propose a novel LUT compression framework to achieve a better trade-off between storage size and performance for LUT-based image restoration models. Based on the observation that most cached LQ image patches are distributed along the diagonal of a LUT, we devise a Diagonal-First Compression (DFC) framework, where diagonal LQ-HQ pairs are preserved and carefully re-indexed to maintain the representation capacity, while non-diagonal pairs are aggressively subsampled to save storage. Extensive experiments on representative image restoration tasks demonstrate that our DFC framework significantly reduces the storage size of LUT-based models (including our new design) while maintaining their performance. For instance, DFC saves up to 90\% of storage at a negligible performance drop for $\times 4$ super-resolution.
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractLarge language models have demonstrated impressive universal capabilities across a wide range of open-ended tasks and have extended their utility to encompass multimodal conversations. However, existing methods encounter challenges in effectively handling both image and video understanding, particularly with limited visual tokens. In this work, we introduce Chat-UniVi, a Unified Vision-language model capable of comprehending and engaging in conversations involving images and videos through a unified visual representation. Specifically, we employ a set of dynamic visual tokens to uniformly represent images and videos. This representation framework empowers the model to efficiently utilize a limited number of visual tokens to simultaneously capture the spatial details necessary for images and the comprehensive temporal relationship required for videos. Moreover, we leverage a multi-scale representation, enabling the model to perceive both high-level semantic concepts and low-level visual details. Notably, Chat-UniVi is trained on a mixed dataset containing both images and videos, allowing direct application to tasks involving both mediums without requiring any modifications. Extensive experimental results demonstrate that Chat-UniVi consistently outperforms even existing methods exclusively designed for either images or videos. Code is available at https://github.com/PKU-YuanGroup/Chat-UniVi. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractThe 3D Human Pose Estimation (3D HPE) task uses 2D images or videos to predict human joint coordinates in 3D space. Despite recent advancements in deep learning-based methods, they mostly ignore the capability of coupling accessible texts and naturally feasible knowledge of humans, missing out on valuable implicit supervision to guide the 3D HPE task. Moreover, previous efforts often study this task from the perspective of the whole human body, neglecting fine-grained guidance hidden in different body parts. To this end, we present a new Fine-Grained Prompt-Driven Denoiser based on a diffusion model for 3D HPE, named FinePOSE.It consists of three core blocks enhancing the reverse process of the diffusion model: (1) Fine-grained Part-aware Prompt learning (FPP) block constructs fine-grained part-aware prompts via coupling accessible texts and naturally feasible knowledge of body parts with learnable prompts to model implicit guidance. (2) Fine-grained Prompt-pose Communication (FPC) block establishes fine-grained communications between learned part-aware prompts and poses to improve the denoising quality. (3) Prompt-driven Timestamp Stylization (PTS) block integrates learned prompt embedding and temporal information related to the noise level to enable adaptive adjustment at each denoising step. Extensive experiments on public single-human pose estimation datasets show that FinePOSE outperforms state-of-the-art methods. … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDiffusion generative modeling has become a promising approach for learning robotic manipulation tasks from stochastic human demonstrations. In this paper, we present Diffusion-EDFs, a novel SE(3)-equivariant diffusion-based approach for visual robotic manipulation tasks. We show that our proposed method achieves remarkable data efficiency, requiring only 5 to 10 human demonstrations for effective end-to-end training in less than an hour. Furthermore, our benchmark experiments demonstrate that our approach has superior generalizability and robustness compared to state-of-the-art methods. Lastly, we validate our methods with real hardware experiments. The codes will be released upon acceptance. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractLarge multi-modal models (LMMs) exhibit remarkable performance across numerous tasks. However, generalist LMMs often suffer from performance degradation when tuned over a large collection of tasks. Recent research suggests that Mixture of Experts (MoE) architectures are useful for instruction tuning, but for LMMs of parameter size around O(50-100B), the prohibitive cost of replicating and storing the expert models severely limits the number of experts we can use.We propose Omni-SMoLA, an architecture that uses the Soft MoE approach to (softly) mix many multimodal low rank experts, and avoids introducing a significant number of new parameters compared to conventional MoE models. The core intuition here is that the large model provides a foundational backbone, while different lightweight experts residually learn specialized knowledge, either per-modality or multimodally. Extensive experiments demonstrate that the SMoLA approach helps improve the generalist performance across a broad range of generative vision-and-language tasks, achieving new SoTA generalist performance that often matches or outperforms single specialized LMM baselines, as well as new SoTA specialist performance. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractAs foundation models become more popular, there is a growing need to efficiently finetune them for downstream tasks. Although numerous adaptation methods have been proposed, they are designed to be efficient only in terms of how many parameters are trained. They, however, typically still require backpropagating gradients throughout the model, meaning that their training-time and -memory cost does not reduce as significantly.We propose an adaptation method which does not backpropagate gradients through the backbone. We achieve this by designing a lightweight network in parallel that operates on features from the frozen, pretrained backbone. As a result, our method is efficient not only in terms of parameters, but also in training-time and memory usage. Our approach achieves state-of-the-art accuracy-parameter trade-offs on the popular VTAB benchmark, and we further show how we outperform prior works with respect to training-time and -memory usage too. We further demonstrate the training efficiency and scalability of our method by adapting a vision transformer backbone of 4 billion parameters for the computationally demanding task of video classification, without any intricate model parallelism. Here, we outperform a prior adaptor-based method which could only scale to a 1 billion parameter backbone, or fully-finetuning a smaller backbone, with the same … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractFeaturizing microscopy images for use in biological research remains a significant challenge, especially for large-scale experiments spanning millions of images. This work explores the scaling properties of weakly supervised classifiers and self-supervised masked autoencoders (MAEs) when training with increasingly larger model backbones and microscopy datasets. Our results show that ViT-based MAEs outperform weakly supervised classifiers on a variety of tasks, achieving as much as a 11.5% relative improvement when recalling known biological relationships curated from public databases. Additionally, we develop a new channel-agnostic MAE architecture (CA-MAE) that allows for inputting images of different numbers and orders of channels at inference time. We demonstrate that CA-MAEs effectively generalize by inferring and evaluating on a microscopy image dataset (JUMP-CP) generated under different experimental conditions with a different channel structure than our pretraining data (RPI-93M). Our findings motivate continued research into scaling self-supervised learning on microscopy data in order to create powerful foundation models of cellular biology that have the potential to catalyze advancements in drug discovery and beyond. |
|
Highlight
|
Poster
[ Arch 4A-E ] 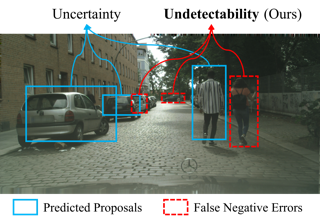
AbstractDomain adaptation adapts models to various scenes with different appearances. In this field, active domain adaptation is crucial in effectively sampling a limited number of data in the target domain. We propose an active domain adaptation method for object detection, focusing on quantifying the undetectability of objects. Existing methods for active sampling encounter challenges in considering undetected objects while estimating the uncertainty of model predictions. Our proposed active sampling strategy addresses this issue using an active learning approach that simultaneously accounts for uncertainty and undetectability. Our newly proposed False Negative Prediction Module evaluates the undetectability of images containing undetected objects, enabling more informed active sampling. This approach considers previously overlooked undetected objects, thereby reducing false negative errors. Moreover, using unlabeled data, our proposed method utilizes uncertainty-guided pseudo-labeling to enhance domain adaptation further. Extensive experiments demonstrate that the performance of our proposed method closely rivals that of fully supervised learning while requiring only a fraction of the labeling efforts needed for the latter. |
|
Highlight
|
Poster
[ Arch 4A-E ] 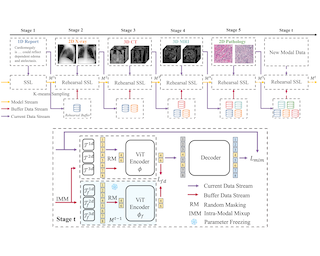
AbstractSelf-supervised learning (SSL) is an efficient pre-training method for medical image analysis. However, current research is mostly confined to certain modalities, consuming considerable time and resources without achieving universality across different modalities. A straightforward solution is combining all modality data for joint SSL, which poses practical challenges. Firstly, our experiments reveal conflicts in representation learning as the number of modalities increases. Secondly, multi-modal data collected in advance cannot cover all real-world scenarios. In this paper, we reconsider versatile SSL from the perspective of continual learning and propose MedCoSS, a continuous SSL approach for multi-modal medical data. Different from joint representation learning, MedCoSS assigns varying data modalities to separate training stages, creating a multi-stage pre-training process. We propose a rehearsal-based continual learning approach to manage modal conflicts and prevent catastrophic forgetting. Specifically, we use the k-means sampling to retain and rehearse previous modality data during new modality learning. Moreover, we apply feature distillation and intra-modal mixup on buffer data for knowledge retention, bypassing pretext tasks. We conduct experiments on a large-scale multi-modal unlabeled dataset, including clinical reports, X-rays, CT, MRI, and pathological images. Experimental results demonstrate MedCoSS’s exceptional generalization ability across 9 downstream datasets and its significant scalability in integrating new … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractIn this work, we introduce Wonder3D, a novel method for generating high-fidelity textured meshes from single-view images with remarkable efficiency. Recent methods based on the Score Distillation Sampling (SDS) loss methods have shown the potential to recover 3D geometry from 2D diffusion priors, but they typically suffer from time-consuming per-shape optimization and inconsistent geometry. In contrast, certain works directly produce 3D information via fast network inferences, but their results are often of low quality and lack geometric details. To holistically improve the quality, consistency, and efficiency of image-to-3D tasks, we propose a cross-domain diffusion model that generates multi-view normal maps and the corresponding color images. To ensure consistency, we employ a multi-view cross-domain attention mechanism that facilitates information exchange across views and modalities. Lastly, we introduce a geometry-aware normal fusion algorithm that extracts high-quality surfaces from the multi-view 2D representations in only 2~3 minutes. Our extensive evaluations demonstrate that our method achieves high-quality reconstruction results, robust generalization, and remarkable efficiency compared to prior works. |
|
Highlight
|
Poster
[ Arch 4A-E ] 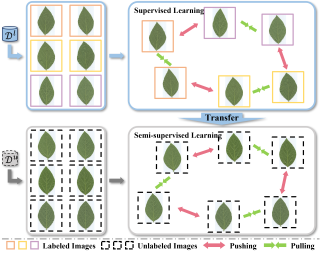
AbstractUltra-fine-grained visual categorization (Ultra-FGVC) aims at distinguishing highly similar sub-categories within fine-grained objects, such as different soybean cultivars. Compared to traditional fine-grained visual categorization, Ultra-FGVC encounters more hurdles due to the small inter-class and large intra-class variation. Given these challenges, relying on human annotation for Ultra-FGVC is impractical. To this end, our work introduces a novel task termed Ultra-Fine-Grained Novel Class Discovery (UFG-NCD), which leverages partially annotated data to identify new categories of unlabeled images for Ultra-FGVC. To tackle this problem, we devise a Region-Aligned Proxy Learning (RAPL) framework, which comprises a Channel-wise Region Alignment (CRA) module and a Semi-Supervised Proxy Learning (SemiPL) strategy. The CRA module is designed to extract and utilize discriminative features from local regions, facilitating knowledge transfer from labeled to unlabeled classes. Furthermore, SemiPL strengthens representation learning and knowledge transfer with proxy-guided supervised learning and proxy-guided contrastive learning. Such techniques leverage class distribution information in the embedding space, improving the mining of subtle differences between labeled and unlabeled ultra-fine-grained classes. Extensive experiments demonstrate that RAPL significantly outperforms baselines across various datasets, indicating its effectiveness in handling the challenges of UFG-NCD. Code is available at https://github.com/SSDUT-Caiyq/UFG-NCD. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractPose refinement is an interesting and practically relevant research direction. Pose refinement can be used to (1) obtain a more accurate pose estimate from an initial prior (e.g., from retrieval), (2) as pre-processing, i.e., to provide a better starting point to a more expensive pose estimator, (3) as post-processing of a more accurate localizer. Existing approaches focus on learning features / scene representations for the pose refinement task. This involves training an implicit scene representation or learning features while optimizing a camera pose-based loss. A natural question is whether training specific features / representations is truly necessary or whether similar results can be already achieved with more generic features. In this work, we present a simple approach that combines pre-trained features with a particle filter and a renderable representation of the scene. Despite its simplicity, it achieves state-of-the-art results, demonstrating that one can easily build a pose refiner without the need for specific training. The code will be released upon acceptance. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractDiffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractTransformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a plug-and-play pruning-and-recovering framework, called Hourglass Tokenizer (HoT), for efficient transformer-based 3D human pose estimation from videos. Our HoT begins with pruning pose tokens of redundant frames and ends with recovering full-length tokens, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. To effectively achieve this, we propose a token pruning cluster (TPC) that dynamically selects a few representative tokens with high semantic diversity while eliminating the redundancy of video frames. In addition, we develop a token recovering attention (TRA) to restore the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Extensive experiments on two benchmark datasets (i.e., Human3.6M and MPI-INF-3DHP) demonstrate that our method can achieve both high efficiency and estimation accuracy compared to the original VPT models. For instance, applying to MotionBERT and MixSTE on Human3.6M, our HoT can save nearly 50\% FLOPs without sacrificing accuracy and nearly 40% FLOPs … |
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
As an important pillar of underwater intelligence, Marine Animal Segmentation (MAS) involves segmenting animals within marine environments. Previous methods don’t excel in extracting long-range contextual features and overlook the connectivity between discrete pixels. Recently, Segment Anything Model (SAM) offers a universal framework for general segmentation tasks. Unfortunately, trained with natural images, SAM does not obtain the prior knowledge from marine images. In addition, the single-position prompt of SAM is very insufficient for prior guidance. To address these issues, we propose a novel feature learning framework, named Dual-SAM for high-performance MAS. To this end, we first introduce a dual structure with SAM’s paradigm to enhance feature learning of marine images. Then, we propose a Multi-level Coupled Prompt (MCP) strategy to instruct comprehensive underwater prior information, and enhance the multi-level features of SAM’s encoder with adapters. Subsequently, we design a Dilated Fusion Attention Module (DFAM) to progressively integrate multi-level features from SAM’s encoder. Finally, instead of directly predicting the masks of marine animals, we propose a Criss-Cross Connectivity Prediction ($C^3$P) paradigm to capture the inter-connectivity between discrete pixels. With dual decoders, it generates pseudo-labels and achieves mutual supervision for complementary feature representations, resulting in considerable improvements over previous techniques. Extensive experiments verify …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractLarge language models (LLMs) have shown remarkable text understanding capabilities, which have been extended as Video LLMs to handle video data for comprehending visual details. However, existing Video LLMs can only provide a coarse description of the entire video, failing to capture the precise start and end time boundary of specific events. In this paper, we solve this issue via proposing VTimeLLM, a novel Video LLM designed for fine-grained video moment understanding and reasoning with respect to time boundary. Specifically, our VTimeLLM adopts a boundary-aware three-stage training strategy, which respectively utilizes image-text pairs for feature alignment, multiple-event videos to increase temporal-boundary awareness, and high-quality video-instruction tuning to further improve temporal understanding ability as well as align with human intents. Extensive experiments demonstrate that in fine-grained time-related comprehension tasks for videos such as Temporal Video Grounding and Dense Video Captioning, VTimeLLM significantly outperforms existing Video LLMs. Besides, benefits from the fine-grained temporal understanding of the videos further enable VTimeLLM to beat existing Video LLMs in video dialogue benchmark, showing its superior cross-modal understanding and reasoning abilities. |
|
Highlight
|
Poster
[ Arch 4A-E ] 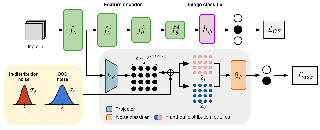
AbstractDespite their exceptional performance in vision tasks, deep learning models often struggle when faced with domain shifts during testing. Test-Time Training (TTT) methods have recently gained popularity by their ability to enhance the robustness of models through the addition of an auxiliary objective that is jointly optimized with the main task. Being strictly unsupervised, this auxiliary objective is used at test time to adapt the model without any access to labels. In this work, we propose Noise-Contrastive Test-Time Training (NC-TTT), a novel unsupervised TTT technique based on the discrimination of noisy feature maps. By learning to classify noisy views of projected feature maps, and then adapting the model accordingly on new domains, classification performance can be recovered by an important margin. Experiments on several popular test-time adaptation baselines demonstrate the advantages of our method compared to recent approaches for this task. The code can be found at: https://github.com/GustavoVargasHakim/NCTTT.git |
|
Highlight
|
Poster
[ Arch 4A-E ] 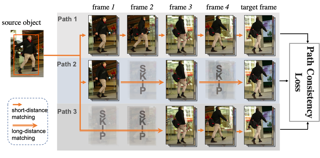
AbstractIn this paper, we propose a novel concept of path consistency to learn robust object association without using the manual object identity supervision. Our key idea is that, to track a object through frames, we can obtain multiple different association results from a model by varying the frames it can observe, i.e., skipping frames in observation. As the difference in observations does not alter the identities of objects, the obtained association results should be consistent. Based on this rationale, we generate multiple paths by skipping observations in intermediate frames and formulate the Path Consistency Loss that enforces the association results are consistent with those different observation paths. We train an object matching model with the proposed loss, and with extensive experiments on three tracking datasets (MOT17, PersonPath22, KITTI), we demonstrate that our method outperforms existing unsupervised methods with consistent margins on various evaluation metrics, and even achieves performance close to supervised methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractScaled relative pose estimation, i.e., estimating relative rotation and scaled relative translation between two images, has always been a major challenge in global Structure-from-Motion (SfM). This difficulty arises because the two-view relative translation computed by traditional geometric vision methods, e.g. the five-point algorithm, is scaleless. Many researchers have proposed diverse translation averaging methods to solve this problem. Instead of solving the problem in the motion averaging phase, we focus on estimating scaled relative pose with the help of panoramic cameras and deep neural networks. In this paper, a novel network, namely PanoPose, is proposed to estimate the relative motion in a fully self-supervised manner and a global SfM pipeline is built for panorama images. The proposed PanoPose comprises a depth-net and a pose-net, with self-supervision achieved by reconstructing the reference image from its neighboring images based on the estimated depth and relative pose. To maintain precise pose estimation under large viewing angle differences, we randomly rotate the panoramic images and pre-train the pose-net with images before and after the rotation. To enhance scale accuracy, a fusion block is introduced to incorporate depth information into pose estimation. Extensive experiments on panoramic SfM datasets demonstrate the effectiveness of PanoPose compared with state-of-the-arts. |
|
Highlight
|
Poster
[ Arch 4A-E ] Abstract
Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video. Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables our model for video synthesis by editing the first frame with any prevalent I2I models, and then propagating edits to successive frames. Our V2V model, FlowVid, demonstrates remarkable properties: (1) Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits. (2) Efficiency: Generation of a 4-second video with 30 FPS and 512$\times$512 resolution takes only 1.5 minutes, which is 3.1$\times$, 7.2$\times$, and 10.5$\times$ faster than CoDeF, Rerender, and TokenFlow, respectively. (3) High-quality: In user studies, our FlowVid is preferred 45.7\% of the time, outperforming CoDeF (3.5\%), Rerender (10.2\%), and TokenFlow …
|
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
This work aims to improve the efficiency of text-to-image diffusion models. While diffusion models use computationally expensive UNet-based denoising operations in every generation step, we identify that not all operations are equally relevant for the final output quality. In particular, we observe that UNet layers operating on high-res feature maps are relatively sensitive to small perturbations. In contrast, low-res feature maps influence the semantic layout of the final image and can often be perturbed with no noticeable change in the output. Based on this observation, we propose \emph{Clockwork Diffusion}, a method that periodically reuses computation from preceding denoising steps to approximate low-res feature maps at one or more subsequent steps. For multiple baselines, and for both text-to-image generation and image editing, we demonstrate that Clockwork leads to comparable or improved perceptual scores with drastically reduced computational complexity. As an example, for Stable Diffusion v1.5 with 8 DPM++ steps we save $32\%$ of FLOPs with negligible FID and CLIP change. We release code at https://github.com/Qualcomm-AI-research/clockwork-diffusion
|
|
Highlight
|
Poster
[ Arch 4A-E ] 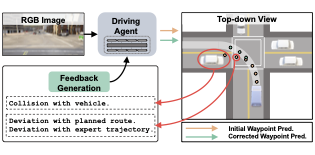
AbstractWhile behavior cloning has recently emerged as a highly successful paradigm for autonomous driving, humans rarely learn to perform complex tasks, such as driving, via imitation or behavior cloning alone. In contrast, learning in humans often involves additional detailed guidance throughout the interactive learning process, i.e., where feedback, often via language, provides detailed information as to which part of their trial was performed incorrectly or suboptimally and why. Motivated by this observation, we introduce an efficient feedback-based framework for improving behavior-cloning-based training of sensorimotor driving agents. Our key insight is to leverage recent advances in Large Language Models (LLMs) to provide corrective fine-grained feedback regarding the underlying reason behind driving prediction failures. Moreover, our introduced network architecture is efficient, enabling the first sensorimotor end-to-end training and evaluation of LLM-based driving models. The resulting agent achieves state-of-the-art performance in open-loop evaluation on nuScenes, outperforming prior state-of-the-art by over 5.4% and 14.3% in accuracy and collision rate, respectively. In CARLA, our camera-based agent improves by 16.6% in driving score over prior LIDAR-based approaches. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractUnsupervised learning of keypoints and landmarks has seen significant progress with the help of modern neural network architectures, but performance is yet to match the supervised counterpart, making their practicability questionable. We leverage the emergent knowledge within text-to-image diffusion models, towards more robust unsupervised keypoints. Our core idea is to find text embeddings that would cause the generative model to consistently attend to compact regions in images (i.e. keypoints). To do so, we simply optimize the text embedding such that the cross-attention maps within the denoising network are localized as Gaussians with small standard deviations. We validate our performance on multiple dataset: the CelebA, CUB-200-2011, Tai-Chi-HD, DeepFashion, and Human3.6m datasets. We achieve significantly improved accuracy, sometimes even outperforming supervised ones, particularly for data that is non-aligned and less curated. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractImage datasets are essential not only in validating existing methods in computer vision but also in developing new methods. Most existing image datasets focus on trichromatic intensity images to mimic human vision.However, polarization and spectrum, the wave properties of light that animals in harsh environments and with limited brain capacity often rely on, remain underrepresented in existing datasets. Although spectro-polarimetric datasets exist, these datasets have insufficient object diversity, limited illumination conditions, linear-only polarization data, and inadequate image count. Here, we introduce two spectro-polarimetric datasets: trichromatic Stokes images and hyperspectral Stokes images. This novel dataset encompass both linear and circular polarization; they introduce multiple spectral channels; and they feature a broad selection of real-world scenes. With our dataset in hand, we analyze the spectro-polarimetric image statistics, develop efficient representations of such high-dimensional data, and evaluate spectral dependency of shape-from-polarization methods. As such, the proposed dataset promises a foundation for data-driven spectro-polarimetric imaging and vision research. Dataset and code will be publicly available. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe aim to generate fine-grained 3D geometry from large-scale sparse LiDAR scans, abundantly captured by autonomous vehicles (AV). Contrary to prior work on AV scene completion, we aim to extrapolate fine geometry from unlabeled and beyond spatial limits of LiDAR scans, taking a step towards generating realistic, high-resolution simulation-ready 3D street environments. We propose hierarchical Generative Cellular Automata (hGCA), a spatially scalable conditional 3D generative model, which grows geometry recursively with local kernels following GCAs, in a coarse-to-fine manner, equipped with a light-weight planner to induce global consistency. Experiments on synthetic scenes show that hGCA generates plausible scene geometry with higher fidelity and completeness compared to state-of-the-art baselines. Our model generalizes strongly from sim-to-real, qualitatively outperforming baselines on the Waymo-open dataset. We also show anecdotal evidence of the ability to create novel objects from real-world geometric cues even when trained on limited synthetic content. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractPassive depth estimation based on stereo, defocus, or shading relies on the presence of the texture on an object to resolve its depth. Hence, recovering the depth of a textureless object---for example, a large white wall---is not just hard but perhaps even impossible.Or is it? We show that spatial coherence, a property of natural light sources, can be used to resolve the depth of a scene point even when it is textureless. Our approach relies on the idea that light scattered off a scene point is fully coherent with itself, while incoherent with others; we use this insight to design an optical setup that uses self-interference as a criterion for estimating depth. Our lab prototype is capable of resolving depths of textureless objects in sunlight as well as indoor lights. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWeakly supervised semantic segmentation has witnessed great achievements with image-level labels. Several recent approaches use the CLIP model to generate pseudo labels for training an individual segmentation model, while there is no attempt to apply the CLIP model as the backbone to directly segment objects with image-level labels. In this paper, we propose WeCLIP, a CLIP-based single-stage pipeline, for weakly supervised semantic segmentation. Specifically, the frozen CLIP model is applied as the backbone for semantic feature extraction, and a new decoder is designed to interpret extracted semantic features for final prediction. Meanwhile, we utilize the above frozen backbone to generate pseudo labels for training the decoder. Such labels cannot be optimized during training. We then propose a refinement module (RFM) to rectify them dynamically. Our architecture enforces the proposed decoder and RFM to benefit from each other to boost the final performance. Extensive experiments show that our approach significantly outperforms other approaches with less training cost. Additionally, our WeCLIP also obtains promising results for fully supervised settings. The code is available at https://github.com/zbf1991/WeCLIP. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractKeypoints used for image matching often include an estimate of the feature scale and orientation. While recent work has demonstrated the advantages of using feature scales and orientations for relative pose estimation, relatively little work has considered their use for absolute pose estimation. We introduce minimal solutions for absolute pose from two oriented feature correspondences in the general case, or one scaled and oriented correspondence given a known vertical direction. Nowadays, assuming a known direction is not particularly restrictive as modern consumer devices, such as smartphones or drones, are equipped with Inertial Measurement Units (IMU) that provide the gravity direction by default. Compared to traditional absolute pose methods requiring three point correspondences, our solvers need a smaller minimal sample, reducing the cost and complexity of robust estimation. Evaluations on large-scale and public real datasets demonstrate the advantage of our methods for fast and accurate localization in challenging conditions. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractGated cameras flood-illuminate a scene and capture the time-gated impulse response of a scene. By employing nanosecond-scale gates, existing sensors are capable of capturing mega-pixel gated images, delivering dense depth improving on today's LiDAR sensors in spatial resolution and depth precision. Although gated depth estimation methods deliver a million of depth estimates per frame, their resolution is still an order below existing RGB imaging methods. In this work, we combine high-resolution stereo HDR RCCB cameras with gated imaging, allowing us to exploit depth cues from active gating, multi-view RGB and multi-view NIR sensing -- multi-view and gated cues across the entire spectrum. The resulting capture system consists only of low-cost CMOS sensors and flood-illumination. We propose a novel stereo-depth estimation method that is capable of exploiting these multi-modal multi-view depth cues, including the active illumination that is measured by the RCCB camera when removing the IR-cut filter. The proposed method achieves accurate depth at long ranges up to 220 m, outperforming the next best existing method by 16\% in MAE on accumulated LiDAR ground-truth. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractWe introduce the new setting of open-vocabulary object 6D pose estimation, in which a textual prompt is used to specify the object of interest.In contrast to existing approaches, in our setting(i) the object of interest is specified solely through the textual prompt,(ii) no object model (e.g. CAD or video sequence) is required at inference,(iii) the object is imaged from two different viewpoints of two different scenes, and(iv) the object was not observed during the training phase.To operate in this setting, we introduce a novel approach that leverages a Vision-Language Model to segment the object of interest from two distinct scenes and to estimate its relative 6D pose.The key of our approach is a carefully devised strategy to fuse object-level information provided by the prompt with local image features, resulting in a feature space that can generalize to novel concepts.We validate our approach on a new benchmark based on two popular datasets, REAL275 and Toyota-Light, which collectively encompass 39 object instances appearing in four thousand image pairs. The results demonstrate that our approach outperforms both a well-established hand-crafted method and a recent deep learning-based baseline in estimating the relative 6D pose of objects in different scenes. |
|
Highlight
|
Poster
[ Arch 4A-E ] 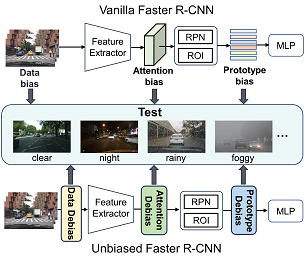
AbstractSingle-source domain generalization (SDG) for object detection is a challenging yet essential task as the distribution bias of the unseen domain degrades the algorithm performance significantly. However, existing methods attempt to extract domain-invariant features, neglecting that the biased data leads the network to learn biased features that are non-causal and poorly generalizable. To this end, we propose an Unbiased Faster R-CNN (UFR) for generalizable feature learning. Specifically, we formulate SDG in object detection from a causal perspective and construct a Structural Causal Model (SCM) to analyze the data bias and feature bias in the task, which are caused by scene confounders and object attribute confounders. Based on the SCM, we design a Global-Local Transformation module for data augmentation, which effectively simulates domain diversity and mitigates the data bias. Additionally, we introduce a Causal Attention Learning module that incorporates a designed attention invariance loss to learn image-level features that are robust to scene confounders. Moreover, we develop a Causal Prototype Learning module with an explicit instance constraint and an implicit prototype constraint, which further alleviates the negative impact of object attribute confounders. Experimental results on five scenes demonstrate the prominent generalization ability of our method, with an improvement of 3.9\% mAP … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractZero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map VLM representations from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred VLM representations. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks.We will release the source code publicly. |
|
Highlight
|
Poster
[ Arch 4A-E ] 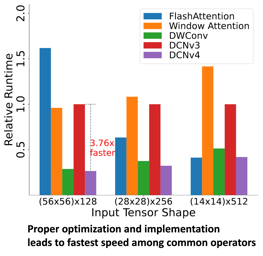
AbstractWe introduce Deformable ConvNets v4 (DCNv4), a highly efficient and effective operator for a broad spectrum of vision applications featuring an advanced sparse attention mechanism. DCNv4 addresses the limitations of its predecessor, DCNv3, with two key enhancements: 1. removing softmax normalization in spatial aggregation to enhance its dynamic property and expressive power and 2. optimizing memory access to minimize redundant operations for speedup. These improvements result in a significantly faster convergence compared to DCNv3 and a substantial increase in processing speed, with DCNv4 achieving more than three times the forward speed.Our evaluation demonstrates DCNv4's superior performance in various tasks, including image classification, instance and semantic segmentation, and notably in image generation. When integrated into generative models like U-Net in the latent diffusion model, DCNv4 outperforms baselines, underscoring its potential to enhance generative models. In practical applications, replacing DCNv3 with DCNv4 in the InternImage model to create FlashInternImage results in up to an 80\% speed increase without necessitating further modifications.DCNv4's advancements in speed and efficiency, combined with its robust performance across diverse vision tasks, position it as a foundational building block for future efficient and effective vision models. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractMultimodal Large Language Model (MLLMs) leverages Large Language Models as a cognitive framework for diverse visual-language tasks. Recent efforts have been made to equip MLLMs with visual perceiving and grounding capabilities.However, there still remains a gap in providing fine-grained pixel-level perceptions and extending interactions beyond text-specific inputs. In this work, we propose AnyRef, a general MLLM model that can generate pixel-wise object perceptions and natural language descriptions from multi-modality references, such as texts, boxes, images, or audios. This innovation empowers users with greater flexibility to engage with the model beyond textual and regional prompts, without modality-specific designs. Through our proposed refocusing mechanism, the generated grounding output is guided to focus more on the referenced object, implicitly incorporating additional pixel-level supervision. This simple modification utilizes attention scores generated during the inference of LLM, eliminating the need for extra computations while exhibiting performance enhancements in both grounding masks and referring expressions. With only publicly available training data, our model achieves state-of-the-art results across multiple benchmarks, including diverse modality referring segmentation and region-level referring expression generation. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractVision-language models (VLMs) have recently shown promising results in traditional downstream tasks.Evaluation studies have emerged to assess their abilities, with the majority focusing on the third-person perspective, and only a few addressing specific tasks from the first-person perspective.However, the capability of VLMs to "think" from a first-person perspective, a crucial attribute for advancing autonomous agents and robotics, remains largely unexplored. To bridge this research gap, we introduce EgoThink, a novel visual question-answering benchmark that encompasses six core capabilities with twelve detailed dimensions.The benchmark is constructed using selected clips from egocentric videos, with manually annotated question-answer pairs containing first-person information. To comprehensively assess VLMs, we evaluate twenty-one popular VLMs on EgoThink. Moreover, given the open-ended format of the answers, we use GPT-4 as the automatic judge to compute single-answer grading.Experimental results indicate that although GPT-4V leads in numerous dimensions, all evaluated VLMs still possess considerable potential for improvement in first-person perspective tasks.Meanwhile, enlarging the number of trainable parameters has the most significant impact on model performance on EgoThink.In conclusion, EgoThink serves as a valuable addition to existing evaluation benchmarks for VLMs, providing an indispensable resource for future research in the realm of embodied artificial intelligence and robotics. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractLong video question answering is a challenging task that involves recognizing short-term activities and reasoning about their fine-grained relationships. State-of-the-art video Large Language Models (vLLMs) hold promise as a viable solution due to their demonstrated emergent capabilities on new tasks. However, despite being trained on millions of short seconds-long videos, vLLMs are unable to understand minutes-long videos and accurately answer questions about them. To address this limitation, we propose a lightweight and self-supervised approach, Key frame-conditioned long video-LLM (Koala), that introduces learnable spatiotemporal queries to adapt pretrained vLLMs for generalizing to longer videos. Our approach introduces two new tokenizers that condition on visual tokens computed from sparse video key frames for understanding short and long video moments. We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks, where it outperforms state-of-the-art large models by 3 - 6% in absolute accuracy across all tasks. Surprisingly, we also empirically show that our approach not only helps a pretrained vLLM to understand long videos but also improves its accuracy on short-term action recognition. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractThis paper proposes a novel direct Audio-Visual Speech to Audio-Visual Speech Translation (AV2AV) framework, where the input and output of the system are multimodal (i.e., audio and visual speech). With the proposed AV2AV, two key advantages can be brought: 1) We can perform real-like conversations with individuals worldwide in a virtual meeting by utilizing our own primary languages. In contrast to Speech-to-Speech Translation (A2A), which solely translates between audio modalities, the proposed AV2AV directly translates between audio-visual speech. This capability enhances the dialogue experience by presenting synchronized lip movements along with the translated speech. 2) We can improve the robustness of the spoken language translation system. By employing the complementary information of audio-visual speech, the system can effectively translate spoken language even in the presence of acoustic noise, showcasing robust performance. To mitigate the problem of the absence of a parallel AV2AV translation dataset, we propose to train our spoken language translation system with the audio-only dataset of A2A. This is done by learning unified audio-visual speech representations through self-supervised learning in advance to train the translation system. Moreover, we propose an AV-Renderer that can generate raw audio and video in parallel. It is designed with zero-shot speaker modeling, thus … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractFace Anti-Spoofing (FAS) is crucial for securing face recognition systems against presentation attacks. With advancements in sensor manufacture and multi-modal learning techniques, many multi-modal FAS approaches have emerged. However, they face challenges in generalizing to unseen attacks and deployment conditions. These challenges arise from (1) modality unreliability, where some modality sensors like depth and infrared undergo significant domain shifts in varying environments, leading to the spread of unreliable information during cross-modal feature fusion, and (2) modality imbalance, where training overly relies on a dominant modality hinders the convergence of others, reducing effectiveness against attack types that are indistinguishable by sorely using the dominant modality.To address modality unreliability, we propose the Uncertainty-Guided Cross-Adapter (U-Adapter) to recognize unreliably detected regions within each modality and suppress the impact of unreliable regions on other modalities. For modality imbalance, we propose a Rebalanced Modality Gradient Modulation (ReGrad) strategy to rebalance the convergence speed of all modalities by adaptively adjusting their gradients.Besides, we provide the first large-scale benchmark for evaluating multi-modal FAS performance under domain generalization scenarios. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. Source codes and protocols are released on https://github.com/OMGGGGG/mmdg. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractBird's eye view (BEV) representation has emerged as a dominant solution for describing 3D space in autonomous driving scenarios. However, objects in the BEV representation typically exhibit small sizes, and the associated point cloud context is inherently sparse, which leads to great challenges for reliable 3D perception. In this paper, we propose IS-Fusion, an innovative multimodal Fusion framework that jointly captures the Instance- and Scene-level contextual information. IS-Fusion essentially differs from existing approaches that only focus on the BEV scene-level fusion by explicitly incorporating instance-level multimodal information, thus facilitating the instance-centric tasks like 3D object detection. It comprises a Hierarchical Scene Fusion (HSF) module and an Instance-Guided Fusion (IGF) module. HSF applies Point-to-Grid and Grid-to-Region transformers to capture the multimodal scene context at different granularities. This leads to enriched scene-level features that are later used to generate high-quality instance features. Next, IGF explores the relationships between these instances, and aggregates the local multimodal context for each instance. These instances then serve as guidance to enhance the scene feature and yield an instance-aware BEV representation. On the challenging nuScenes benchmark, IS-Fusion outperforms all the published multimodal works to date. Notably, it achieves 72.8% mAP on the nuScenes validation set, outperforming prior … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractOpen-vocabulary semantic segmentation presents the challenge of labeling each pixels within an image based on wide range of text descriptions. In this work, we introduce a novel cost-based approach to adapt vision-language foundation models, notably CLIP, for the intricate task of semantic segmentation. Through aggregating the cosine similarity score, i.e. the cost volume between image and text embeddings, our method potently adapts CLIP for segmenting seen and unseen classes by fine-tuning its encoders, addressing the challenges faced by existing methods in handling unseen classes. Building upon this, we explore methods to effectively aggregate the cost volume considering its multi-modal nature of being established between image and text embeddings. Furthermore, we examine various methods for efficiently fine-tuning CLIP. Our framework, dubbed CAT-Seg, shows state-of-the-art performance on standard benchmarks with significant margins, and further exerts strengths in more challenging scenarios from various domains. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractAs a problem often encountered in real-world scenarios, multi-view multi-label learning has attracted considerable research attention. However, due to oversights in data collection and uncertainties in manual annotation, real-world data often suffer from incompleteness. Regrettably, most existing multi-view multi-label learning methods sidestep missing views and labels. Furthermore, they often neglect the potential of harnessing complementary information between views and labels, thus constraining their classification capabilities. To address these challenges, we propose a view-category interactive sharing transformer tailored for incomplete multi-view multi-label learning. Within this network, we incorporate a two-layer transformer module to characterize the interplay between views and labels. Additionally, to address view incompleteness, a KNN-style missing view generation module is employed. Finally, we introduce a view-category consistency guided embedding enhancement module to align different views and improve the discriminating power of the embeddings. Collectively, these modules synergistically integrate to classify the incomplete multi-view multi-label data effectively. Extensive experiments substantiate that our approach outperforms the existing state-of-the-art methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
We present $DiffPortrait3D$, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging …
|
|
Highlight
|
Learning Adaptive Spatial Coherent Correlations for Speech-Preserving Facial Expression Manipulation
Poster
[ Arch 4A-E ] 
AbstractSpeech-preserving facial expression manipulation (SPFEM) aims to modify facial emotions while meticulously maintaining the mouth animation associated with spoken content. Current works depend on inaccessible paired training samples for the person, where two aligned frames exhibit the same speech content yet differ in emotional expression, limiting the SPFEM applications in real-world scenarios. In this work, we discover that speakers who convey the same content with different emotions exhibit highly correlated local facial animations, providing valuable supervision for SPFEM. To capitalize on this insight, we propose a novel adaptive spatial coherent correlation learning (ASCCL) algorithm, which models the aforementioned correlation as an explicit metric and integrates the metric to supervise manipulating facial expression and meanwhile better preserving the facial animation of spoken contents. To this end, it first learns a spatial coherent correlation metric, ensuring the visual disparities of adjacent local regions of the image belonging to one emotion are similar to those of the corresponding counterpart of the image belonging to another emotion. Recognizing that visual disparities are not uniform across all regions, we have also crafted a disparity-aware adaptive strategy that prioritizes regions that present greater challenges. During SPFEM model training, we construct the adaptive spatial coherent correlation metric … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
Abstract
Research into dynamic 3D scene understanding has primarily focused on short-term change tracking from dense observations, while little attention has been paid to long-term changes with sparse observations. We address this gap with $MoRE^2$, a novel approach designed for multi-object relocalization and reconstruction in evolving environments. We view these environments as ``living scenes" and consider the problem of transforming scans taken at different points in time into a 3D reconstruction of the object instances, whose accuracy and completeness increase over time.At the core of our method lies a SE(3)-equivariant representation in a single encoder-decoder network, trained on synthetic data. This representation enables us to seamlessly tackle instance matching, registration, and reconstruction. We also introduce a joint optimization algorithm that facilitates the accumulation of point clouds originating from the same instance across multiple scans taken at different points in time. We validate our method on synthetic and real-world data and demonstrate state-of-the-art performance in both end-to-end performance and individual subtasks.
|
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractThe increasing prevalence of video clips has sparked growing interest in text-video retrieval. Recent advances focus on establishing a joint embedding space for text and video, relying on consistent embedding representations to compute similarity. However, the text content in existing datasets is generally short and concise, making it hard to fully describe the redundant semantics of a video. Correspondingly, a single text embedding may be less expressive to capture the video embedding and empower the retrieval. In this study, we propose a new stochastic text modeling method T-MASS, i.e., text is modeled as a stochastic embedding, to enrich text embedding with a flexible and resilient semantic range, yielding a text mass. To be specific, we introduce a similarity-aware radius module to adapt the scale of the text mass upon the given text-video pairs. Plus, we design and develop a support text regularization to further control the text mass during the training. The inference pipeline is also tailored to fully exploit the text mass for accurate retrieval. Empirical evidence suggests that T-MASS not only effectively attracts relevant text-video pairs while distancing irrelevant ones, but also enables the determination of precise text embeddings for relevant pairs. Our experimental results show a substantial … |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractScene reconstruction from multi-view images is a fundamental problem in computer vision and graphics. Recent neural implicit surface reconstruction methods have achieved high-quality results; however, editing and manipulating the 3D geometry of reconstructed scenes remains challenging due to the absence of naturally decomposed object entities and complex object/background compositions. In this paper, we present Total-Decom, a novel method for decomposed 3D reconstruction with minimal human interaction. Our approach seamlessly integrates the Segment Anything Model (SAM) with hybrid implicit-explicit neural surface representations and a mesh-based region-growing technique for accurate 3D object decomposition. Total-Decom requires minimal human annotations while providing users with real-time control over the granularity and quality of decomposition. We extensively evaluate our method on benchmark datasets and demonstrate its potential for downstream applications, such as animation and scene editing. Codes will be made publicly available. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractThe recent advancements in text-to-3D generation mark a significant milestone in generative models, unlocking new possibilities for creating imaginative 3D assets across various real-world scenarios. While recent advancements in text-to-3D generation have shown promise, they often fall short in rendering detailed and high-quality 3D models. This problem is especially prevalent as many methods base themselves on Score Distillation Sampling (SDS). This paper identifies a notable deficiency in SDS, that it brings inconsistent and low-quality updating direction for the 3D model, causing the over-smoothing effect. To address this, we propose a novel approach called Interval Score Matching (ISM). ISM employs deterministic diffusing trajectories and utilizes interval-based score matching to counteract over-smoothing. Furthermore, we incorporate 3D Gaussian Splatting into our text-to-3D generation pipeline. Extensive experiments show that our model largely outperforms the state-of-the-art in quality and training efficiency. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractRecovering dense and long-range pixel motion in videos is a challenging problem. Part of the difficulty arises from the 3D-to-2D projection process, leading to occlusions and discontinuities in the 2D motion domain. While 2D motion can be intricate, we posit that the underlying 3D motion can often be simple and low-dimensional. In this work, we propose to estimate point trajectories in 3D space to mitigate the issues caused by image projection. Our method, named SpatialTracker, lifts 2D pixels to 3D using monocular depth estimators, represents the 3D content of each frame efficiently using a triplane representation, and performs iterative updates using a transformer to estimate 3D trajectories. Tracking in 3D allows us to leverage as-rigid-as possible(ARAP) constraints while simultaneously learning a rigidity embedding that clusters pixels into different rigid parts. Extensive evaluation shows that our approach achieves state-of-the-art tracking performance both qualitatively and quantitatively, particularly in chal- lenging scenarios such as out-of-plane rotation. And our project page is available at https://henry123-boy.github.io/SpaTracker/. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present VecFusion, a new neural architecture that can generate vector fonts with varying topological structures and precise control point positions. Our approach is a cascaded diffusion model which consists of a raster diffusion model followed by a vector diffusion model. The raster model generates low-resolution, rasterized fonts with auxiliary control point information, capturing the global style and shape of the font, while the vector model synthesizes vector fonts conditioned on the low-resolution raster fonts from the first stage. To synthesize long and complex curves, our vector diffusion model uses a transformer architecture and a novel vector representation that enables the modeling of diverse vector geometry and the precise prediction of control points. Our experiments show that, in contrast to previous generative models for vector graphics, our new cascaded vector diffusion model generates higher quality vector fonts, with complex structures and diverse styles. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractSegment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractNeural radiance fields provide state-of-the-art view synthesis quality but tend to be slow to render. One reason is that they make use of volume rendering, thus requiring many samples (and model queries) per ray at render time. Although this representation is flexible and easy to optimize, most real-world objects can be modeled more efficiently with surfaces instead of volumes, requiring far fewer samples per ray. This observation has spurred considerable progress in surface representations such as signed distance functions, but these may struggle to model semi-opaque and thin structures. We propose a method, HybridNeRF, that leverages the strengths of both representations by rendering most objects as surfaces while modeling the (typically) small fraction of challenging regions volumetrically.We evaluate HybridNeRF against the challenging Eyeful Tower dataset along with other commonly used view synthesis datasets. When comparing to state-of-the-art baselines, including recent rasterization-based approaches, we improve error rates by 15-30% while achieving real-time framerates (at least 36 FPS) for virtual-reality resolutions (2K x 2K). |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractIn this paper, we explore the potential of Snapshot Com- pressive Imaging (SCI) technique for recovering the under- lying 3D scene representation from a single temporal com- pressed image. SCI is a cost-effective method that enables the recording of high-dimensional data, such as hyperspec- tral or temporal information, into a single image using low- cost 2D imaging sensors. To achieve this, a series of spe- cially designed 2D masks are usually employed, which not only reduces storage requirements but also offers potential privacy protection. Inspired by this, to take one step further, our approach builds upon the powerful 3D scene represen- tation capabilities of neural radiance fields (NeRF). Specif- ically, we formulate the physical imaging process of SCI as part of the training of NeRF, allowing us to exploit its impressive performance in capturing complex scene struc- tures. To assess the effectiveness of our method, we con- duct extensive evaluations using both synthetic data and real data captured by our SCI system. Extensive experi- mental results demonstrate that our proposed approach sur- passes the state-of-the-art methods in terms of image re- construction and novel view image synthesis. Moreover, our method also exhibits the ability to restore high frame- rate multi-view … |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractStructure-from-motion (SfM) is a long-standing problem in the computer vision community, which aims to reconstruct the camera poses and 3D structure of a scene from a set of unconstrained 2D images. Classical frameworks solve this problem in an incremental manner by detecting and matching keypoints, registering images, triangulating 3D points, and conducting bundle adjustment. Recent research efforts have predominantly revolved around harnessing the power of deep learning techniques to enhance specific elements (e.g., keypoint matching), but are still based on the original, non-differentiable pipeline. Instead, we propose a new deep SfM pipeline, where each component is fully differentiable and thus can be trained in an end-to-end manner. To this end, we introduce new mechanisms and simplifications. First, we build on recent advances in deep 2D point tracking to extract reliable pixel-accurate tracks, which eliminates the need for chaining pairwise matches. Furthermore, we recover all cameras simultaneously based on the image and track features instead of gradually registering cameras. Finally, we optimise the cameras and triangulate 3D points via a differentiable bundle adjustment layer. We attain state-of-the-art performance on three popular datasets, CO3D, IMC Phototourism, and ETH3D. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractAction understanding matters for intelligent agents and has attracted long-term attention. It can be formed as the mapping from the action physical space to the semantic space. Typically, researchers built action datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Thus, datasets are incompatible with each other like "Isolated Islands" due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that a more principled semantic space is an urgent need to concentrate the community efforts and enable us to use all datasets together to pursue generalizable action learning. To this end, we design a structured action semantic space in view of verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging ``isolated islands'' into a "Pangea". Accordingly, we propose a novel model mapping from the physical space to semantic space to fully use Pangea. In extensive experiments, our new system shows significant superiority, especially in transfer learning. Our code and data will be made public at https://mvig-rhos.com/pangea. |
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractLocal Interpretable Model-agnostic Explanations (LIME) - a widely used post-ad-hoc model agnostic explainable AI (XAI) technique. It works by training a simple transparent (surrogate) model using random samples drawn around the neighborhood of the instance (image) to be explained (IE). Explanations are then extracted for a black-box model and a given IE, using the surrogate model. However, the explanations of LIME suffer from inconsistency across different runs for the same model and the same IE. We identify two main types of inconsistencies: variance in the sign and importance ranks of the segments (superpixels). These factors hinder LIME from obtaining consistent explanations. We analyze these inconsistencies and propose a new method, Stabilized LIME for Consistent Explanations (SLICE). The proposed method handles the stabilization problem in two aspects: using a novel feature selection technique to eliminate spurious superpixels and an adaptive perturbation technique to generate perturbed images in the neighborhood of IE. Our results demonstrate that the explanations from SLICE exhibit significantly better consistency and fidelity than LIME (and its variant BayLime). |
|
Highlight
|
Poster
[ Arch 4A-E ] 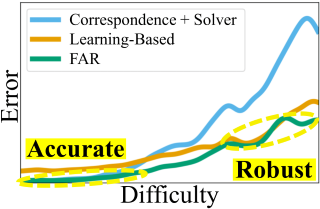
AbstractEstimating relative camera poses between images has been a central problem in computer vision. Methods that find correspondences and solve for the fundamental matrix offer high precision in most cases. Conversely, methods predicting pose directly using neural networks are more robust to limited overlap and can infer absolute translation scale, but at the expense of reduced precision. We show how to combine the best of both methods; our approach yields results that are both precise and robust, while also accurately inferring translation scales. At the heart of our model lies a Transformer that (1) learns to balance between solved and learned pose estimations, and (2) provides a prior to guide a solver. A comprehensive analysis supports our design choices and demonstrates that our method adapts flexibly to various feature extractors and correspondence estimators, showing state-of-the-art performance in 6DoF pose estimation on Matterport3D, InteriorNet, StreetLearn, and Map-Free Relocalization. |
|
Highlight
|
Poster
[ Arch 4A-E ] 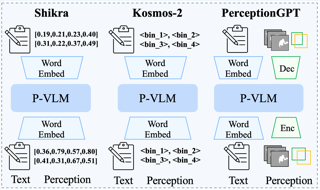
AbstractThe integration of visual inputs with large language models (LLMs) has led to remarkable advancements in multi-modal capabilities, giving rise to vision large language models (VLLMs). However, effectively harnessing LLMs for intricate visual perception tasks, such as detection and segmentation, remains a challenge. Conventional approaches achieve this by transforming perception signals (e.g., bounding boxes, segmentation masks) into sequences of discrete tokens, which struggle with the precision errors and introduces further complexities for training. In this paper, we present a novel end-to-end framework named PerceptionGPT, which represent the perception signals using LLM's dynamic token embedding. Specifically, we leverage lightweight encoders and decoders to handle the perception signals in LLM's embedding space, which takes advantage of the representation power of the high-dimensional token embeddings. Our approach significantly eases the training difficulties associated with the discrete representations in prior methods. Furthermore, owing to our compact representation, the inference speed is also greatly boosted. Consequently, PerceptionGPT enables accurate, flexible and efficient handling of complex perception signals. We validate the effectiveness of our approach through extensive experiments. The results demonstrate significant improvements over previous methods with only 4% trainable parameters and less than 25% training time. |
|
Highlight
|
Diffusion Reflectance Map: Single-Image Stochastic Inverse Rendering of Illumination and Reflectance
Poster
[ Arch 4A-E ] 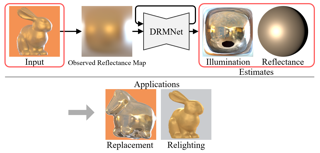
AbstractReflectance bounds the frequency spectrum of illumination in the object appearance. In this paper, we introduce the first stochastic inverse rendering method, which recovers the attenuated frequency spectrum of an illumination jointly with the reflectance of an object of known geometry from a single image. Our key idea is to solve this blind inverse problem in the reflectance map, an appearance representation invariant to the underlying geometry, by learning to reverse the image formation with a novel diffusion model which we refer to as the Diffusion Reflectance Map Network (DRMNet). Given an observed reflectance map converted and completed from the single input image, DRMNet generates a reflectance map corresponding to a perfect mirror sphere while jointly estimating the reflectance. The forward process can be understood as gradually filtering a natural illumination with lower and lower frequency reflectance and additive Gaussian noise. DRMNet learns to invert this process with two subnetworks, IllNet and RefNet, which work in concert towards this joint estimation. The network is trained on an extensive synthetic dataset and is demonstrated to generalize to real images, showing state-of-the-art accuracy on established datasets. |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe present Cutie, a video object segmentation (VOS) network with object-level memory reading, which puts the object representation from memory back into the video object segmentation result. Recent works on VOS employ bottom-up pixel-level memory reading which struggles due to matching noise, especially in the presence of distractors, resulting in lower performance in more challenging data. In contrast, Cutie performs top-down object-level memory reading by adapting a small set of object queries. Via those, it interacts with the bottom-up pixel features iteratively with a query-based object transformer (qt, hence Cutie). The object queries act as a high-level summary of the target object, while high-resolution feature maps are retained for accurate segmentation. Together with foreground-background masked attention, Cutie cleanly separates the semantics of the foreground object from the background. On the challenging MOSE dataset, Cutie improves by 8.7 J&F over XMem with a similar running time and improves by 4.2 J&F over DeAOT while being three times faster. Code will be released. |
|
Highlight
|
Poster
[ Arch 4A-E ] 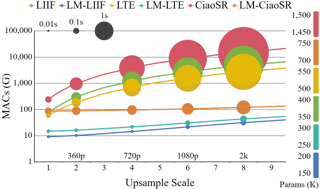
Abstract
The recent work Local Implicit Image Function (LIIF) and subsequent Implicit Neural Representation (INR) based works have achieved remarkable success in Arbitrary-Scale Super-Resolution (ASSR) by using MLP to decode Low-Resolution (LR) features. However, these continuous image representations typically implement decoding in High-Resolution (HR) High-Dimensional (HD) space, leading to a quadratic increase in computational cost and seriously hindering the practical applications of ASSR. To tackle this problem, we propose a novel Latent Modulated Function (LMF), which decouples the HR-HD decoding process into shared latent decoding in LR-HD space and independent rendering in HR Low-Dimensional (LD) space, thereby realizing the first computational optimal paradigm of continuous image representation. Specifically, LMF utilizes an HD MLP in latent space to generate latent modulations of each LR feature vector. This enables a modulated LD MLP in render space to quickly adapt to any input feature vector and perform rendering at arbitrary resolution.Furthermore, we leverage the positive correlation between modulation intensity and input image complexity to design a Controllable Multi-Scale Rendering (CMSR) algorithm, offering the flexibility to adjust the decoding efficiency based on the rendering precision. Extensive experiments demonstrate that converting existing INR-based ASSR methods to LMF can reduce the computational cost by up to 99.9%, …
|
|
Highlight
|
Poster
[ Arch 4A-E ] AbstractRegression-based keypoint localization shows advantages of high efficiency and better robustness to quantization errors than heatmap-based methods. However, existing regression-based methods discard the spatial location prior in input image with a global pooling, leading to inferior accuracy and are limited to single instance localization tasks. We study the regression-based keypoint localization from a new perspective by leveraging the spatial location prior. Instead of regressing on the pooled feature, the proposed Spatial-Aware Regression (SAR) maintains the spatial location map and outputs spatial coordinates and confidence score for each grid, which are optimized with a unified objective. Benefited by the location prior, these spatial-aware outputs can be efficiently optimized, resulting in better localization performance. Moreover, incorporating spatial prior makes SAR more general and can be applied into various keypoint localization tasks. We test the proposed method in 4 keypoint localization tasks including single/multi-person 2D/3D pose estimation, and the whole-body pose estimation. Extensive experiments demonstrate its promising performance, e.g., consistently outperforming recent regressions-based methods. |
|
Highlight
|
Poster
[ Arch 4A-E ] 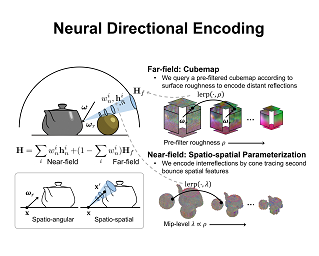
AbstractNovel-view synthesis of specular objects like shiny metals or glossy paints remains a significant challenge.Not only the glossy appearance but also global illumination effects, including reflections of other objects in the environment, are critical components to faithfully reproduce a scene.In this paper, we present Neural Directional Encoding (NDE), a view-dependent appearance encoding of neural radiance fields (NeRF) for rendering specular objects.NDE transfers the concept of feature-grid-based spatial encoding to the angular domain, significantly improving the ability to model high-frequency angular signals.In contrast to previous methods that use encoding functions with only angular input, we additionally cone-trace spatial features to obtain a spatially varying directional encoding, which addresses the challenging interreflection effects.Extensive experiments on both synthetic and real datasets show that a NeRF model with NDE (1) outperforms the state of the art on view synthesis of specular objects, and (2) works with small networks to allow fast (real-time) inference.The source code is available at: https://github.com/lwwu2/nde |
|
Highlight
|
Poster
[ Arch 4A-E ] 
AbstractWe describe a method for recovering the irradiance underlying a collection of images corrupted by atmospheric turbulence. Since supervised data is often technically impossible to obtain, assumptions and biases have to be imposed, and we choose to model them explicitly. Rather than initializing a latent irradiance (``template'') by heuristics to estimate deformation, we select one of the images as a reference, and model the deformation in this image by the aggregation of the optical flow from it to other images, exploiting a prior imposed by Central Limit Theorem. Then with a novel flow inversion module, the model registers each image TO the template but WITHOUT the template, avoiding artifacts related to poor template initialization. To illustrate the simplicity and robustness of the method, we simply select the first frame as the reference and use the simplest optical flow to estimate the warpings, yet the improvement in registration is decisive in the final reconstruction, as we achieve state-of-the-art performance despite its simplicity. The method establishes a strong baseline that can be improved by integrating it with more sophisticated pipelines, or with domain-specific methods if so desired. |