
{kind=link}
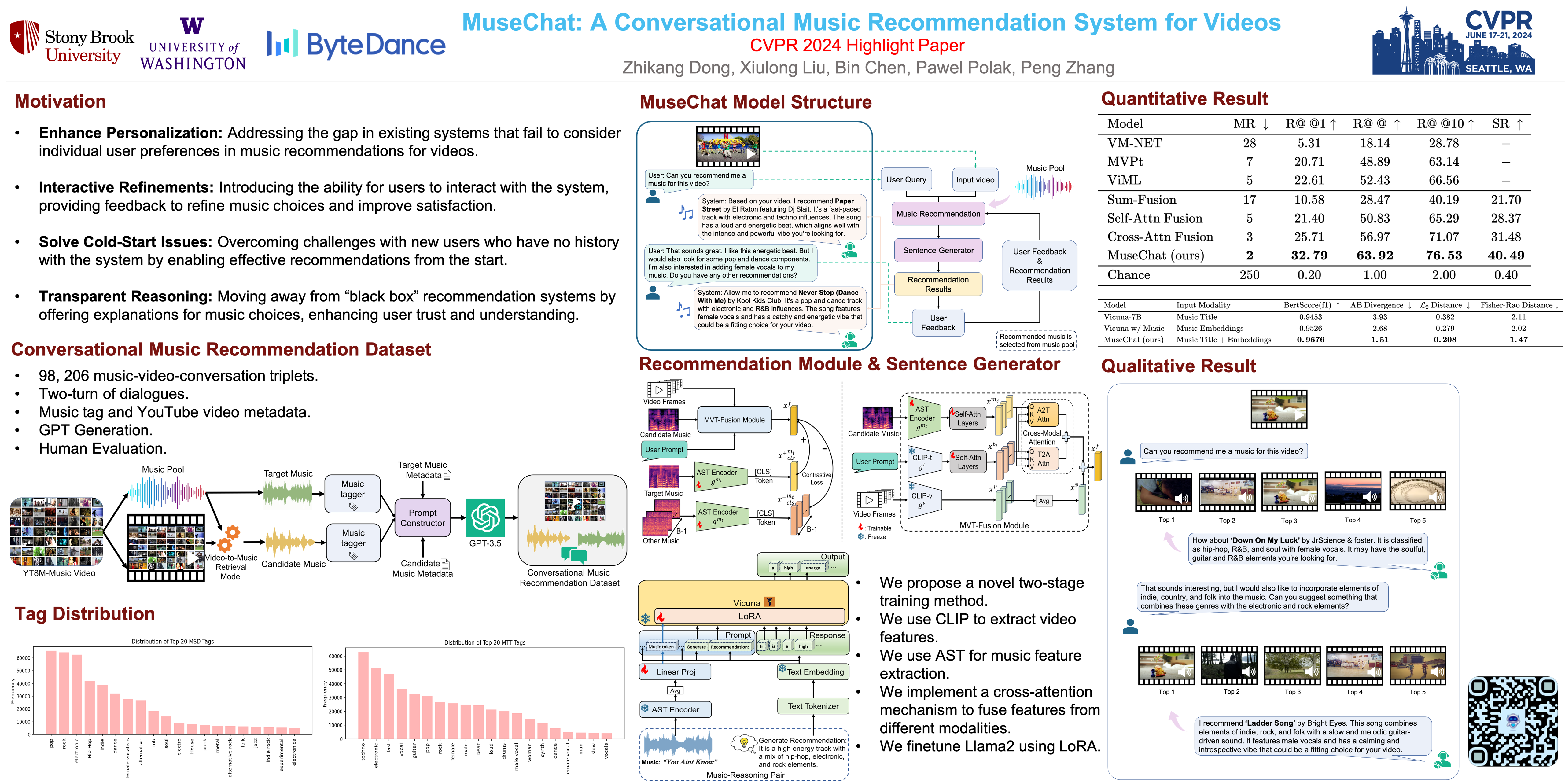
Music recommendation for videos attracts growing interest in multi-modal research. However, existing systems focus primarily on content compatibility, often ignoring the users' preferences. Their inability to interact with users for further refinements or to provide explanations leads to a less satisfying experience. We address these issues with MuseChat, a first-of-its-kind dialogue-based recommendation system that personalizes music suggestions for videos. Our system consists of two key functionalities with associated modules: recommendation and reasoning. The recommendation module takes a video along with optional information including previous suggested music and user's preference as inputs and retrieves an appropriate music matching the context. The reasoning module, equipped with the power of Large Language Model (Vicuna-7B) and extended to multi-modal inputs, is able to provide reasonable explanation for the recommended music. To evaluate the effectiveness of MuseChat, we build a large-scale dataset, conversational music recommendation for videos, that simulates a two-turn interaction between a user and a recommender based on accurate music track information. Experiment results show that MuseChat achieves significant improvements over existing video-based music retrieval methods as well as offers strong interpretability and interactability. The dataset of this work is available at https://dongzhikang.github.io/musechat.