
{kind=link}
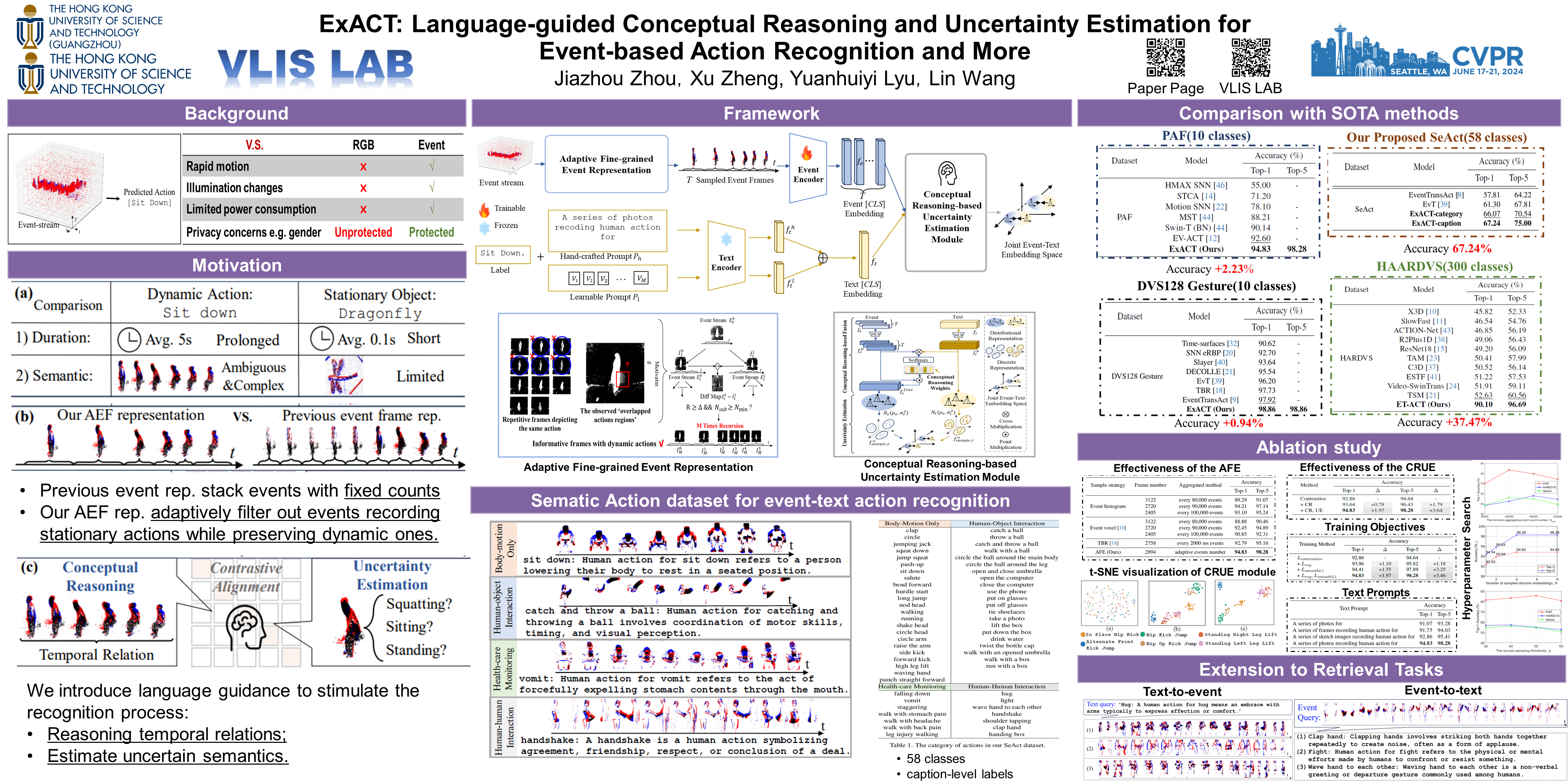
Event cameras have recently been shown beneficial for practical vision tasks, such as action recognition, thanks to their high temporal resolution, power efficiency, and reduced privacy concerns. However, current research is hindered by 1) the difficulty in processing events because of their prolonged duration and dynamic actions with complex and ambiguous semantics; and 2) the redundant action depiction of the event frame representation with fixed stacks. We find language naturally conveys abundant semantic information, rendering it stunningly superior in reducing semantic uncertainty. In light of this, we propose ExACT, a novel approach that, for the first time, tackles event-based action recognition from a cross-modal conceptualizing perspective. Our ExACT brings two technical contributions. Firstly, we propose an adaptive fine-grained event (AFE) representation to adaptively filter out the repeated events for the stationary objects while preserving dynamic ones. This subtly enhances the performance of ExACT without extra computational cost. Then, we propose a conceptual reasoning-based uncertainty estimation module, which simulates the recognition process to enrich the semantic representation. In particular, conceptual reasoning builds the temporal relation based on the action semantics, and uncertainty estimation tackles the semantic uncertainty of actions based on the distributional representation. Experiments show that our ExACT achieves superior recognition accuracy of 94.83%(+2.23%), 90.10%(+37.47%) and 67.24% on PAF, HARDVS and our SeAct datasets respectively.