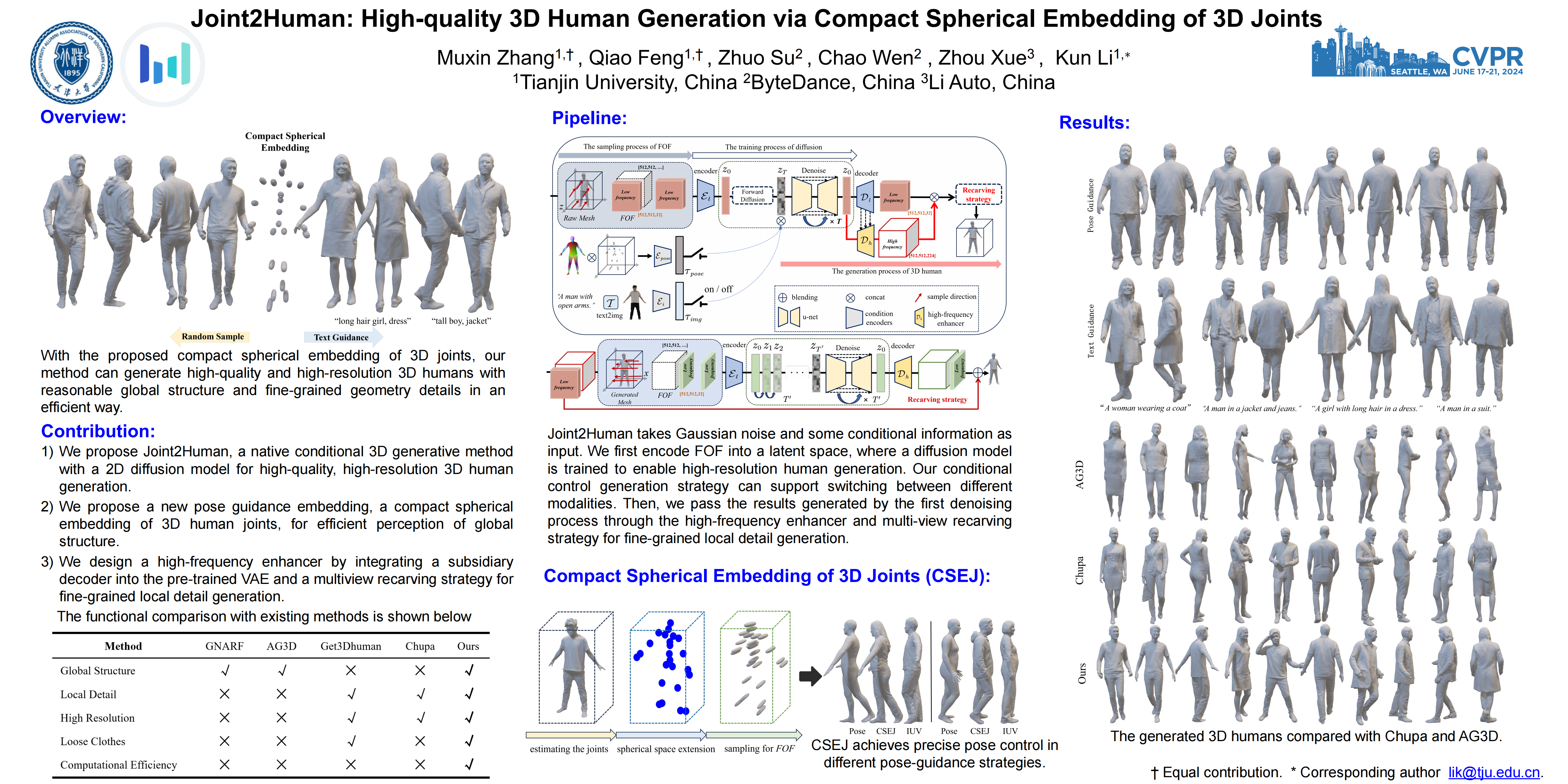
{kind=link}
3D human generation is increasingly significant in various applications. However, the direct use of 2D generative methods in 3D generation often results in losing local details, while methods that reconstruct geometry from generated images struggle with global view consistency. In this work, we introduce Joint2Human, a novel method that leverages 2D diffusion models to generate detailed 3D human geometry directly, ensuring both global structure and local details. To achieve this, we employ the Fourier occupancy field (FOF) representation, enabling the direct generation of 3D shapes as preliminary results with 2D generative models. With the proposed high-frequency enhancer and the multi-view recarving strategy, our method can seamlessly integrate the details from different views into a uniform global shape. To better utilize the 3D human prior and enhance control over the generated geometry, we introduce a compact spherical embedding of 3D joints. This allows for an effective guidance of pose during the generation process. Additionally, our method can generate 3D humans guided by textual inputs. Our experimental results demonstrate the capability of our method to ensure global structure, local details, high resolution, and low computational cost simultaneously. More results and the code can be found on our project page at http://cic.tju.edu.cn/faculty/likun/projects/Joint2Human.