{kind=link}
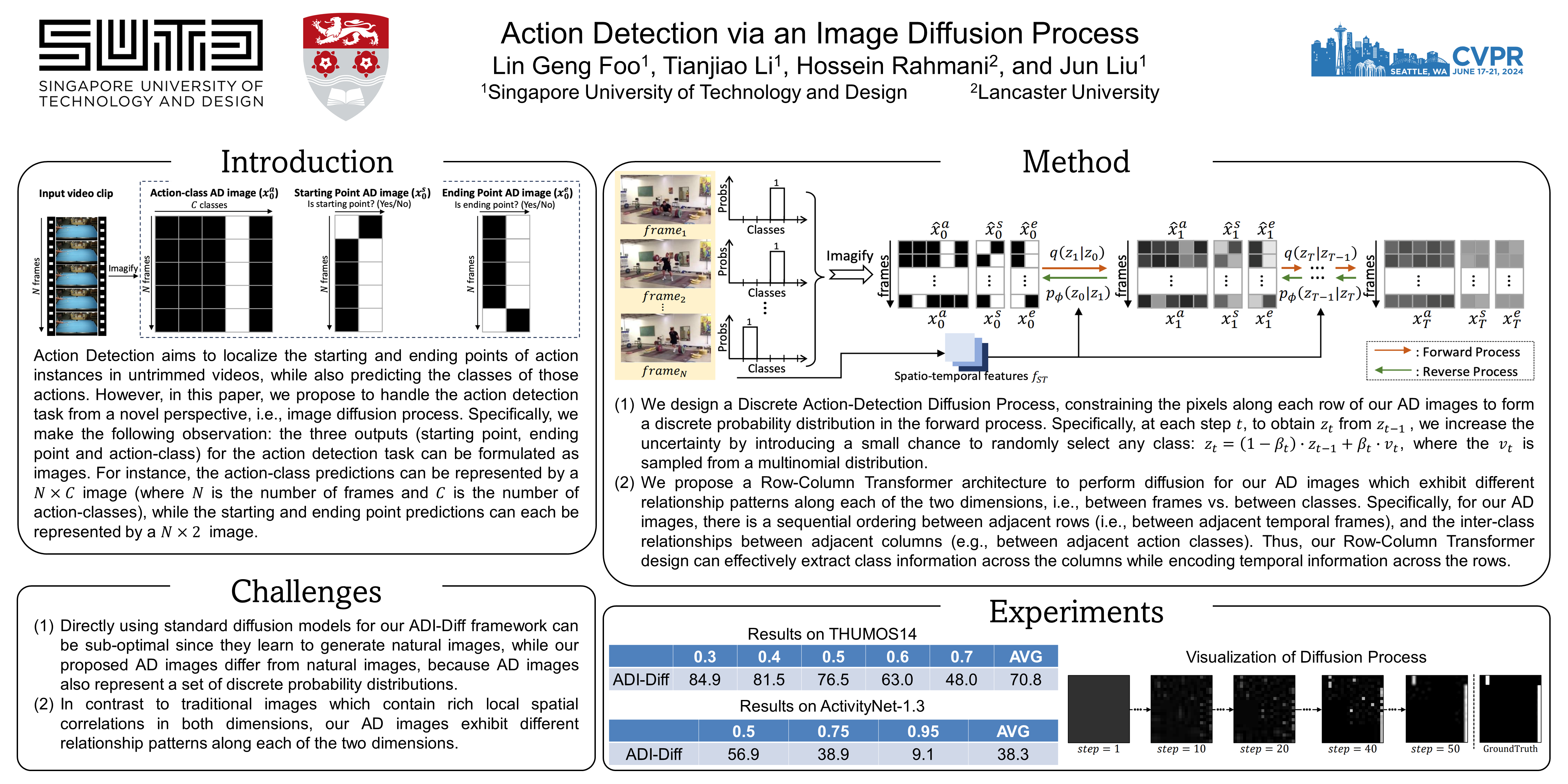
Action detection aims to localize the starting and ending points of action instances in untrimmed videos, and predict the classes of those instances. In this paper, we make the observation that the outputs of the action detection task can be formulated as images. Thus, from a novel perspective, we tackle action detection via a three-image generation process to generate starting point, ending point and action-class predictions as images via our proposed Action Detection Image Diffusion (ADI-Diff) framework. Furthermore, since our images differ from natural images and exhibit special properties, we further explore a Discrete Action-Detection Diffusion Process and a Row-Column Transformer design to better handle our images. Our ADI-Diff framework achieves state-of-the-art performance on two widely-used datasets.