{kind=link}
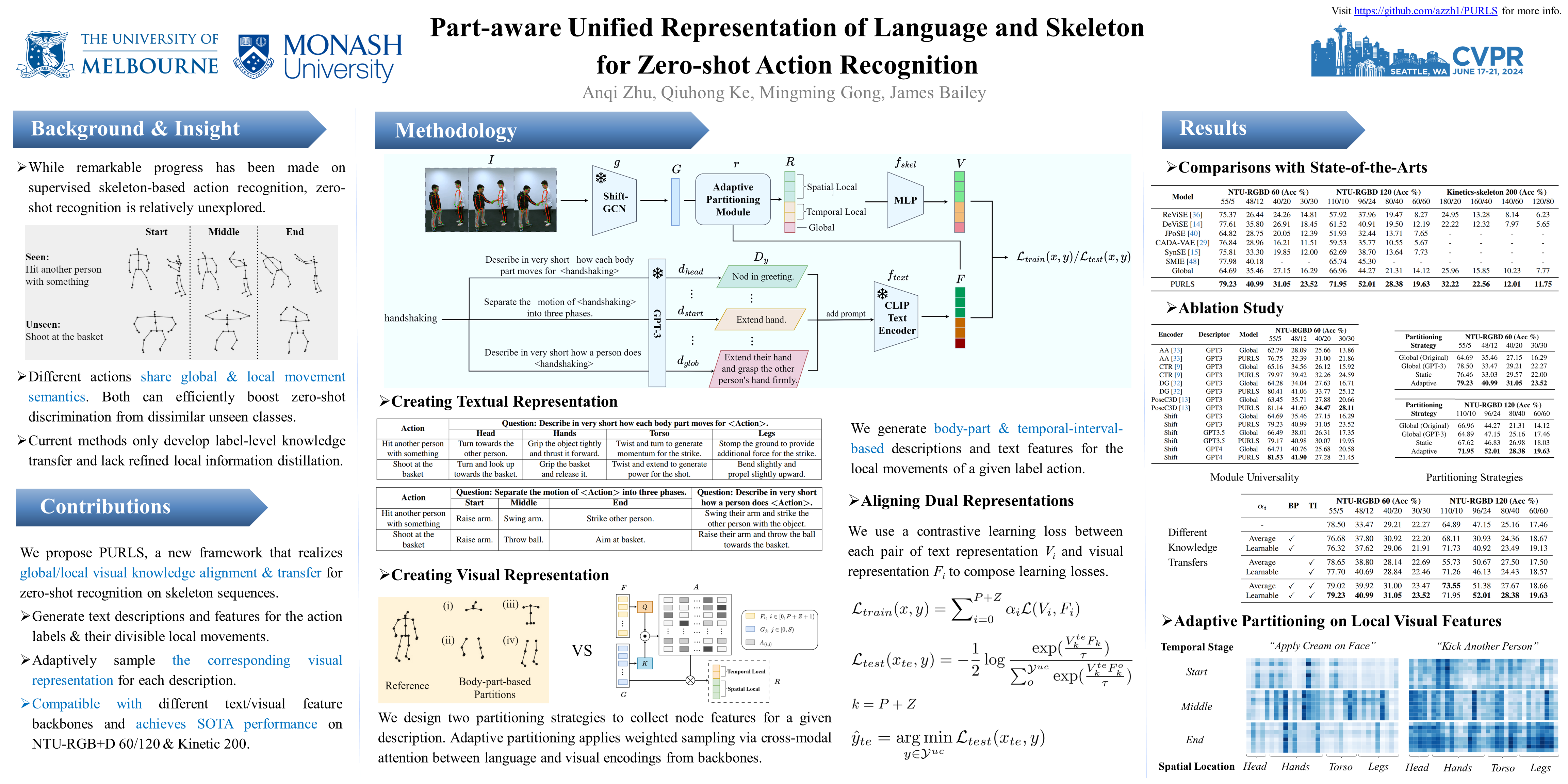
Skeleton-based action recognition is gaining popularity as a viable alternative to RGB-based classification due to its lower computational complexity and compact data structure. While remarkable progress has been made on supervised skeleton-based action recognition, the challenge of zero-shot action recognition remains relatively unexplored. In this paper, we argue that relying solely on aligning label-level semantics and global features from all skeleton joints is insufficient to effectively transfer locally consistent visual knowledge from seen to unseen classes. To address this limitation, we introduce Part-aware Unified Representation between Language and Skeleton (PURLS) to explore visual-semantic alignment at both local and global scales. PURLS incorporates a prompting module and a partitioning module to generate textual and visual representations for visual-text alignment. The prompting module leverages GPT-3 to generate refined global/local descriptions from original action labels and extracts their language embeddings using CLIP. The partitioning module employs an adaptive sampling strategy to group visual features of semantic-relevant body joints for a given description. During training, PURLS is trained to project aligned visual-textual encoding manifolds of global, body-part-based local, and temporal-interval-based local representations in a balanced manner. Our approach is evaluated on three large-scale datasets, i.e., NTU-RGB+D 60, NTU-RGB+D 120, and a newly curated dataset Kinetics-skeleton 200. The results showcase the superior performance of PURLS, surpassing prior skeleton-based solutions and standard baselines from other domains.