Poster
Learning Vision from Models Rivals Learning Vision from Data
Yonglong Tian · Lijie Fan · Kaifeng Chen · Dina Katabi · Dilip Krishnan · Phillip Isola
Arch 4A-E Poster #123
{kind=link}
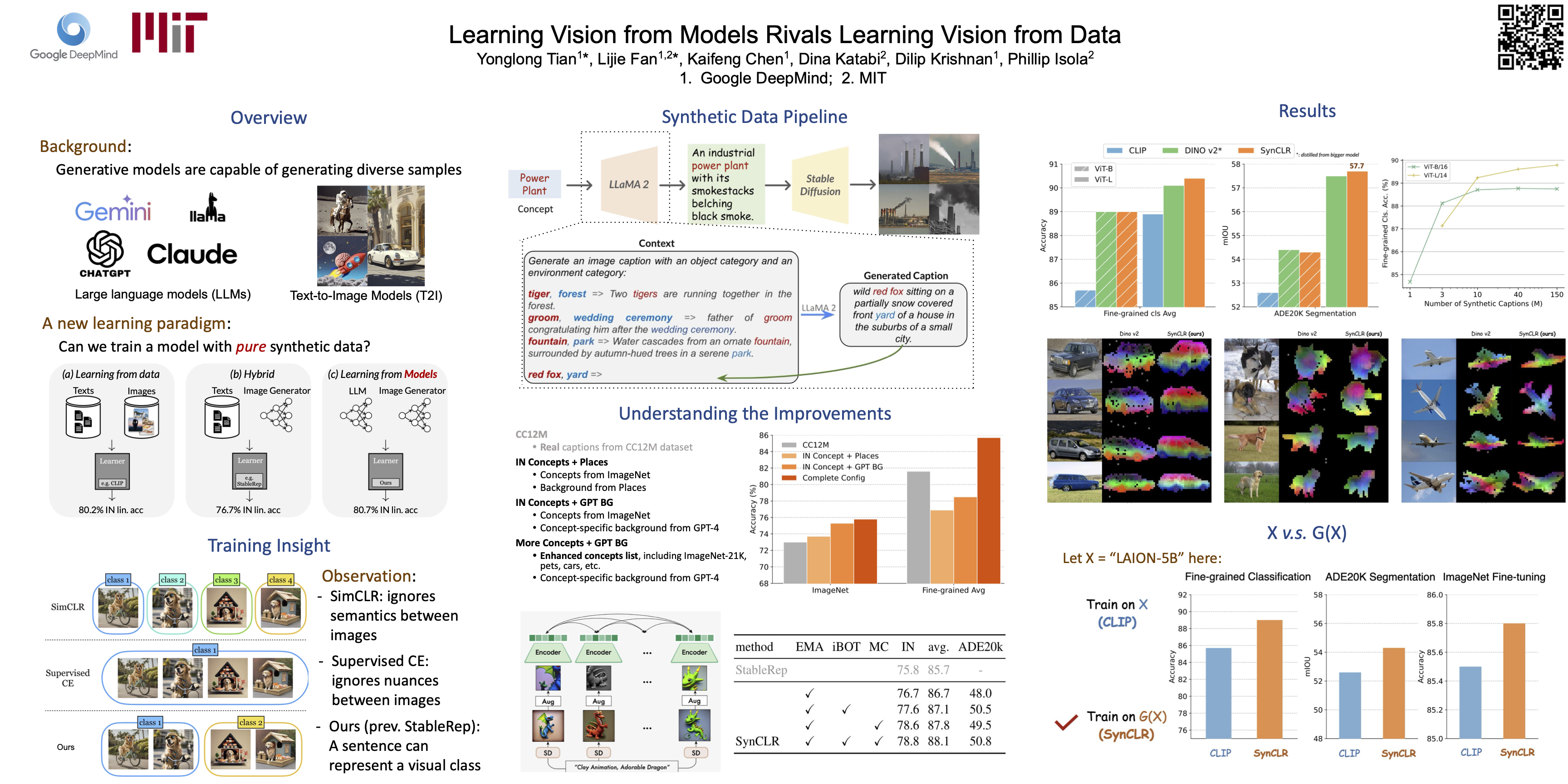
We introduce SynCLR, a novel approach for learning visual representations exclusively from synthetic images, without any real data. We synthesize a large dataset of image captions using LLMs, then use an off-the-shelf text-to-image model to generate multiple images corresponding to each synthetic caption. We perform visual representation learning on these synthetic images via contrastive learning, treating images sharing the same caption as positive pairs. The resulting representations demonstrate remarkable transferability, competing favorably with other general-purpose visual representation learners such as CLIP and DINO v2 in image classification tasks. Furthermore, in dense prediction tasks such as semantic segmentation, SynCLR outperforms previous self-supervised methods by a significant margin, e.g., improving over MAE and iBOT by 5.0 and 3.1 mIoU on ADE20k for ViT-B/16.