Poster
Pre-trained Model Guided Fine-Tuning for Zero-Shot Adversarial Robustness
Sibo Wang · Jie Zhang · Zheng Yuan · Shiguang Shan
Arch 4A-E Poster #27
{kind=link}
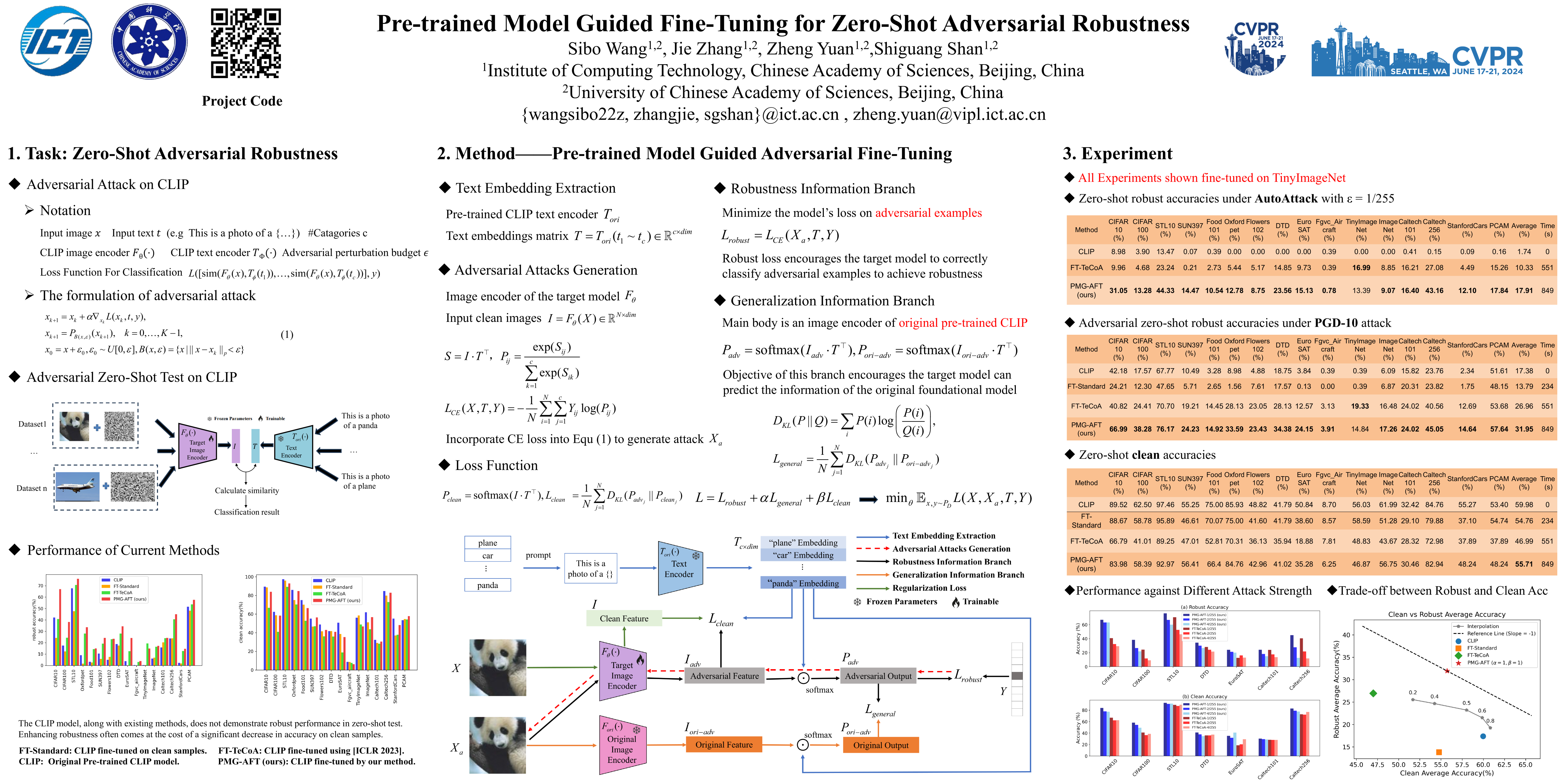
Large-scale pre-trained vision-language models like CLIP have demonstrated impressive performance across various tasks, and exhibit remarkable zero-shot generalization capability, while they are also vulnerable to imperceptible adversarial examples. Existing works typically employ adversarial training (fine-tuning) as a defense method against adversarial examples. However, direct application to the CLIP model may result in overfitting, compromising the model's capacity for generalization.In this paper, we propose Pre-trained Model Guided Adversarial Fine-Tuning (PMG-AFT) method, which leverages supervision from the original pre-trained model by carefully designing an auxiliary branch, to enhance the model's zero-shot adversarial robustness.Specifically, PMG-AFT minimizes the distance between the features of adversarial examples in the target model and those in the pre-trained model, aiming to preserve the generalization features already captured by the pre-trained model.Extensive Experiments on 15 zero-shot datasets demonstrate that PMG-AFT significantly outperforms the state-of-the-art method, improving the top-1 robust accuracy by an average of 4.99\%.Furthermore, our approach consistently improves clean accuracy by an average of 8.72\%.Our code is available at \href{https://github.com/serendipity1122/Pre-trained-Model-Guided-Fine-Tuning-for-Zero-Shot-Adversarial-Robustness}{here}.\footnote{https://github.com/serendipity1122/Pre-trained-Model-Guided-Fine-Tuning-for-Zero-Shot-Adversarial-Robustness}