{kind=link}
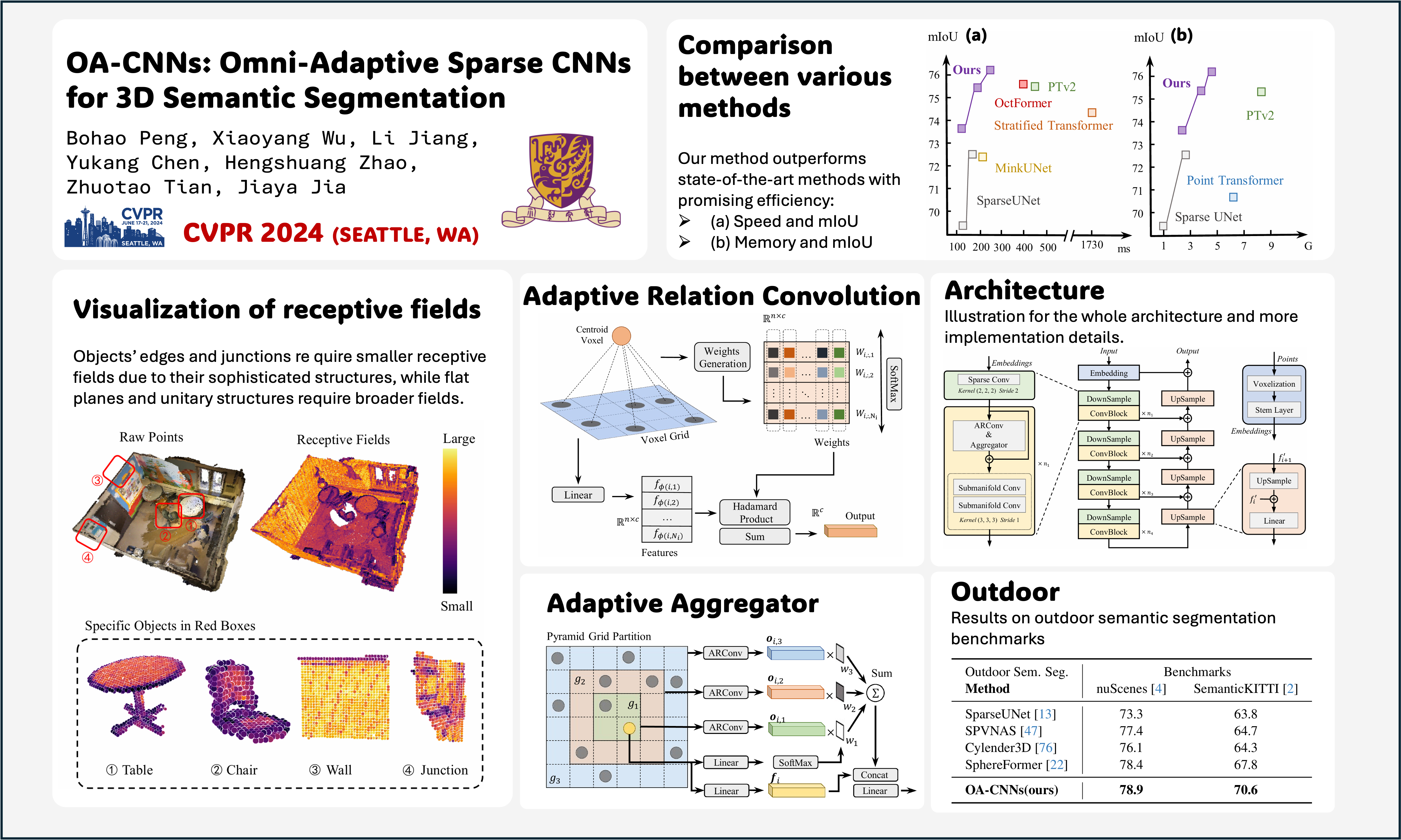
The booming of 3D recognition in the 2020s began with the introduction of point cloud transformers. They quickly overwhelmed sparse CNNs and became state-of-the-art models, especially in 3D semantic segmentation. However, sparse CNNs are still valuable networks, due to their efficiency treasure, and ease of application. In this work, we reexamine the design distinctions and test the limits of what a sparse CNN can achieve. We discover that the key credit to the performance difference is adaptivity. Specifically, we propose two key components, i.e., adaptive receptive fields (spatially) and adaptive relation, to bridge the gap. This exploration led to the creation of Omni-Adaptive 3D CNNs (OA-CNNs), a family of networks that integrates a lightweight module to greatly enhance the adaptivity of sparse CNNs at minimal computational cost. Without any self-attention modules, OA-CNNs favorably surpass point transformers in terms of accuracy in both indoor and outdoor scenes, with much less latency and memory cost. Notably, it achieves 76.1%, 78.9%, and 70.6% mIoU on ScanNet v2, nuScenes, and SemanticKITTI validation benchmarks respectively, while maintaining at most 5x better speed than transformer counterparts. This revelation highlights the potential of pure sparse CNNs to outperform transformer-related networks. Our code is built upon Pointcept, which is available at https://github.com/Pointcept/Pointcept.