Poster
Multi-Modal Proxy Learning Towards Personalized Visual Multiple Clustering
Jiawei Yao · Qi Qian · Juhua Hu
Arch 4A-E Poster #427
{kind=link}
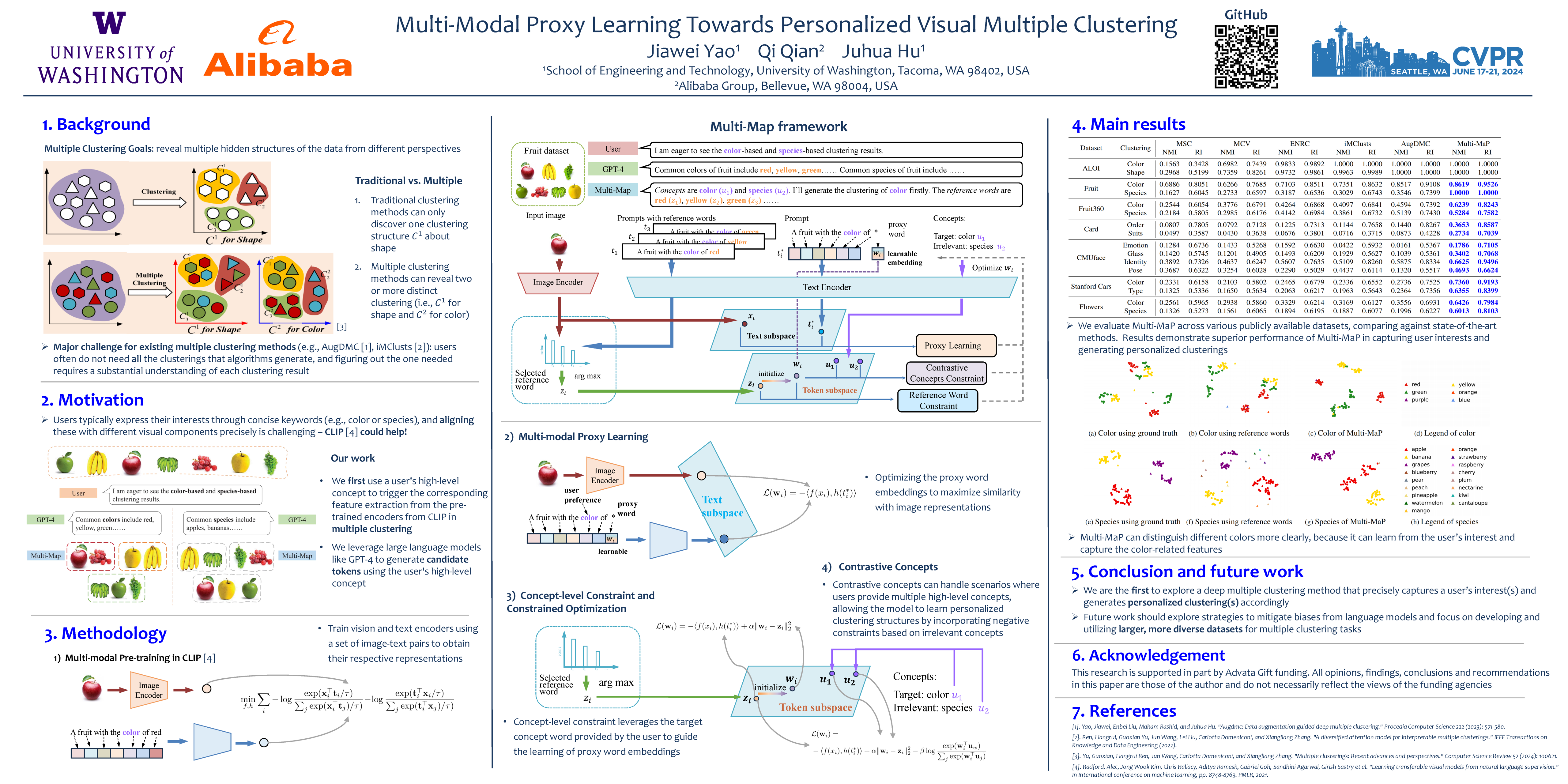
Multiple clustering has gained significant attention in recent years due to its potential to reveal multiple hidden structures of data from different perspectives. The advent of deep multiple clustering techniques has notably advanced the performance by uncovering complex patterns and relationships within large datasets. However, a major challenge arises as users often do not need all the clusterings that algorithms generate, and figuring out the one needed requires a substantial understanding of each clustering result. Traditionally, aligning a user's brief keyword of interest with the corresponding vision components was challenging, but the emergence of multi-modal and large language models (LLMs) has begun to bridge this gap. In response, given unlabeled target visual data, we propose Multi-Map, a novel method employing a multi-modal proxy learning process. It leverages CLIP encoders to extract coherent text and image embeddings, with GPT-4 integrating users' interests to formulate effective textual contexts. Moreover, reference word constraint and concept-level constraint are designed to learn the optimal text proxy according to the user’s interest. Multi-Map not only adeptly captures a user's interest via a keyword but also facilitates identifying relevant clusterings. Our extensive experiments show that Multi-Map consistently outperforms state-of-the-art methods in all benchmark multi-clustering vision tasks. Our code is available at https://github.com/Alexander-Yao/Multi-MaP.