{kind=link}
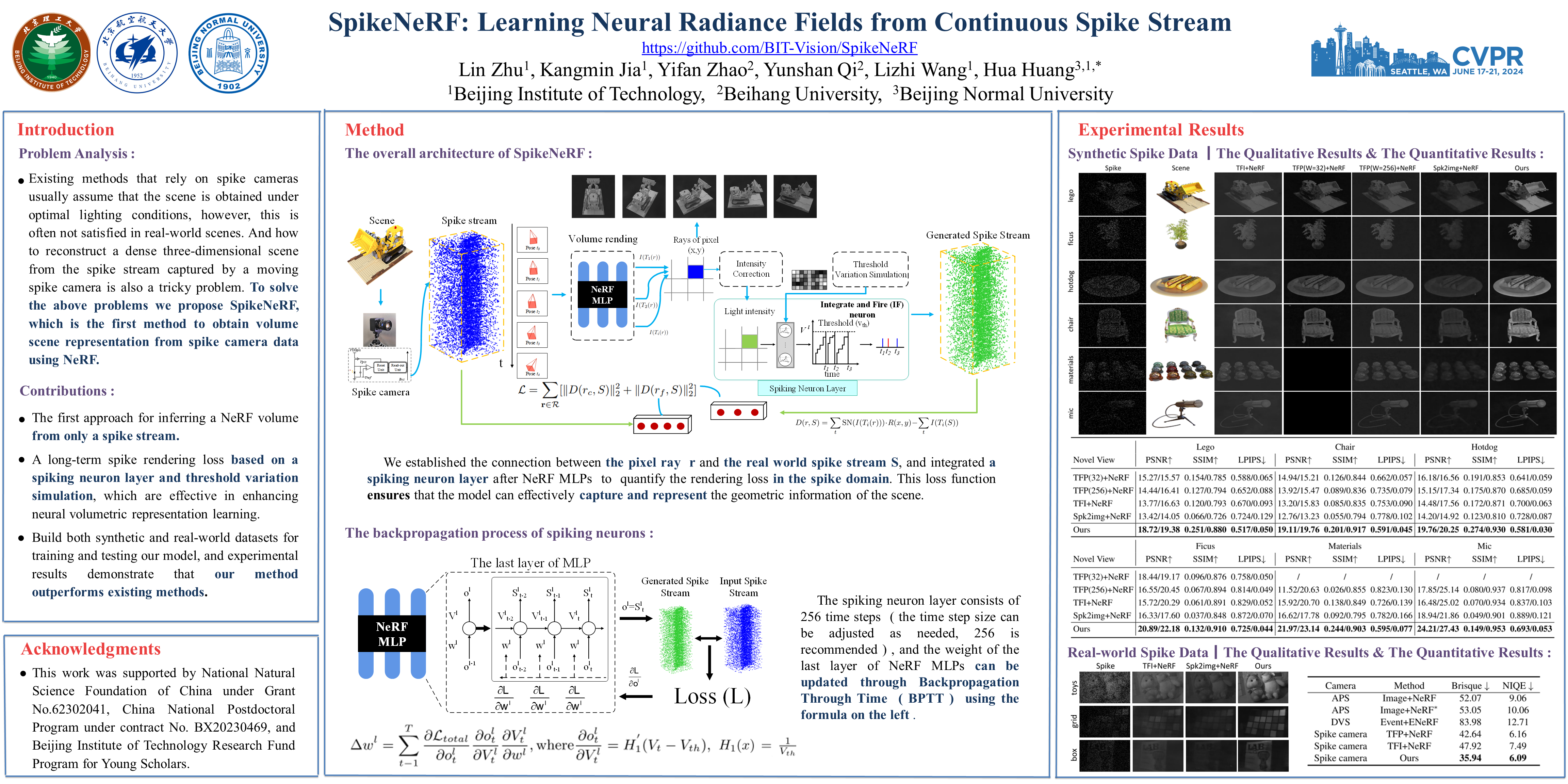
Spike cameras, leveraging spike-based integration sampling and high temporal resolution, offer distinct advantages over standard cameras. However, existing approaches reliant on spike cameras often assume optimal illumination, a condition frequently unmet in real-world scenarios. To address this, we introduce SpikeNeRF, the first work that derives a NeRF-based volumetric scene representation from spike camera data. Our approach leverages NeRF's multi-view consistency to establish robust self-supervision, effectively eliminating erroneous measurements and uncovering coherent structures within exceedingly noisy input amidst diverse real-world illumination scenarios. The framework comprises two core elements: a spike generation model incorporating an integrate-and-fire neuron layer and parameters accounting for non-idealities, such as threshold variation, and a spike rendering loss capable of generalizing across varying illumination conditions. We describe how to effectively optimize neural radiance fields to render photorealistic novel views from the novel continuous spike stream, demonstrating advantages over other vision sensors in certain scenes. Empirical evaluations conducted on both real and novel realistically simulated sequences affirm the efficacy of our methodology. The dataset and source code are released at https://github.com/BIT-Vision/SpikeNeRF.