{kind=link}
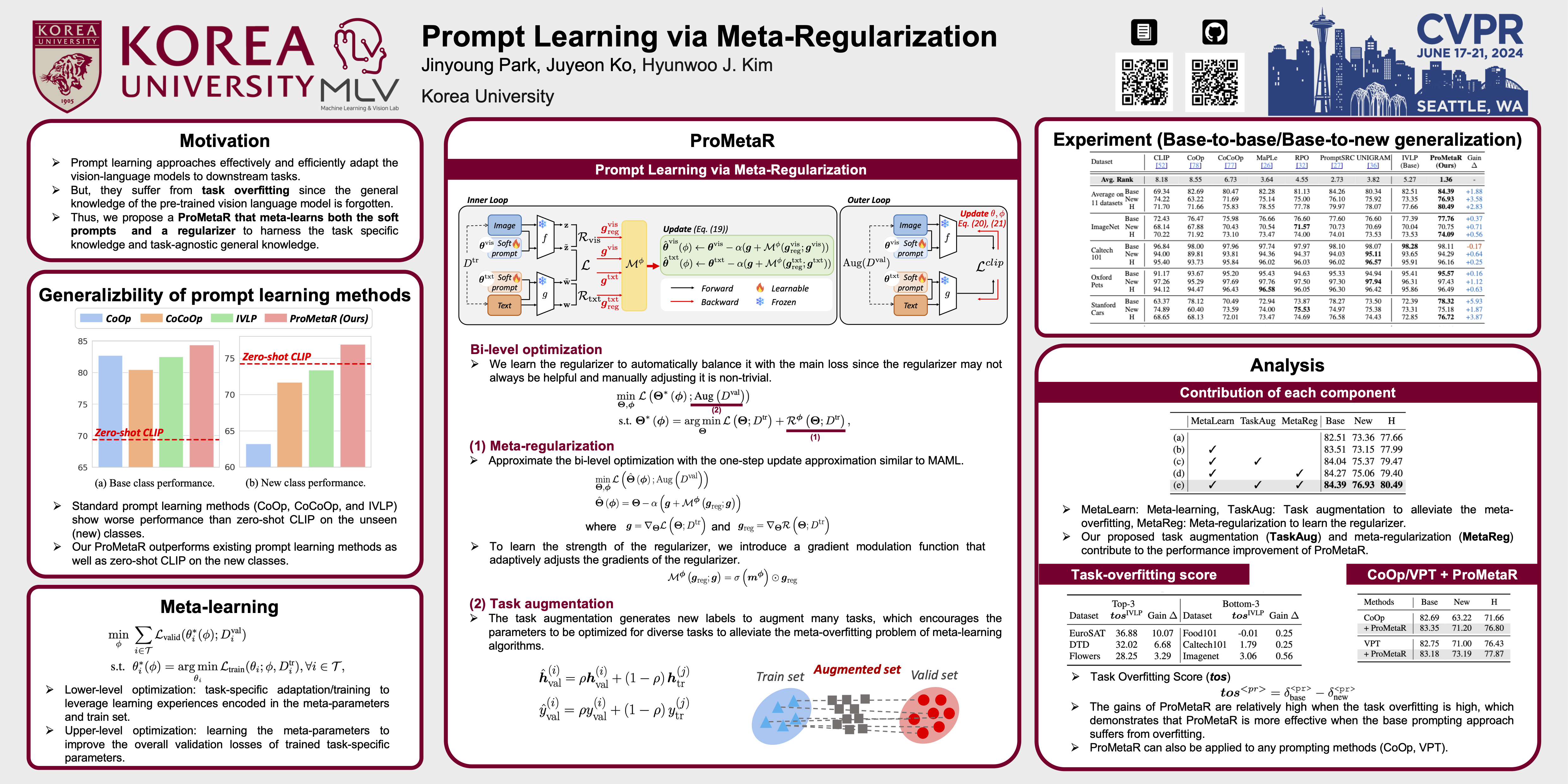
Pre-trained vision-language models have shown impressive success on various computer vision tasks with their zero-shot generalizability. Recently, prompt learning approaches have been explored to efficiently and effectively adapt the vision-language models to a variety of downstream tasks. However, most existing prompt learning methods suffer from \textit{task overfitting} since the general knowledge of the pre-trained vision language models is forgotten while the prompts are finetuned on a small data set from a specific target task. To address this issue, we propose a Prompt Meta-Regularization~(ProMetaR) to improve the generalizability of prompt learning for vision-language models. Specifically, ProMetaR meta-learns both the regularizer and the soft prompts to harness the task-specific knowledge from the downstream tasks and task-agnostic general knowledge from the vision-language models. Further, ProMetaR augments the task to generate multiple virtual tasks to alleviate the meta-overfitting. In addition, we provide the analysis to comprehend how ProMetaR improves the generalizability of prompt tuning in the perspective of the gradient alignment. Our extensive experiments demonstrate that our ProMetaR improves the generalizability of conventional prompt learning methods under base-to-base/base-to-new and domain generalization settings.