{kind=link}
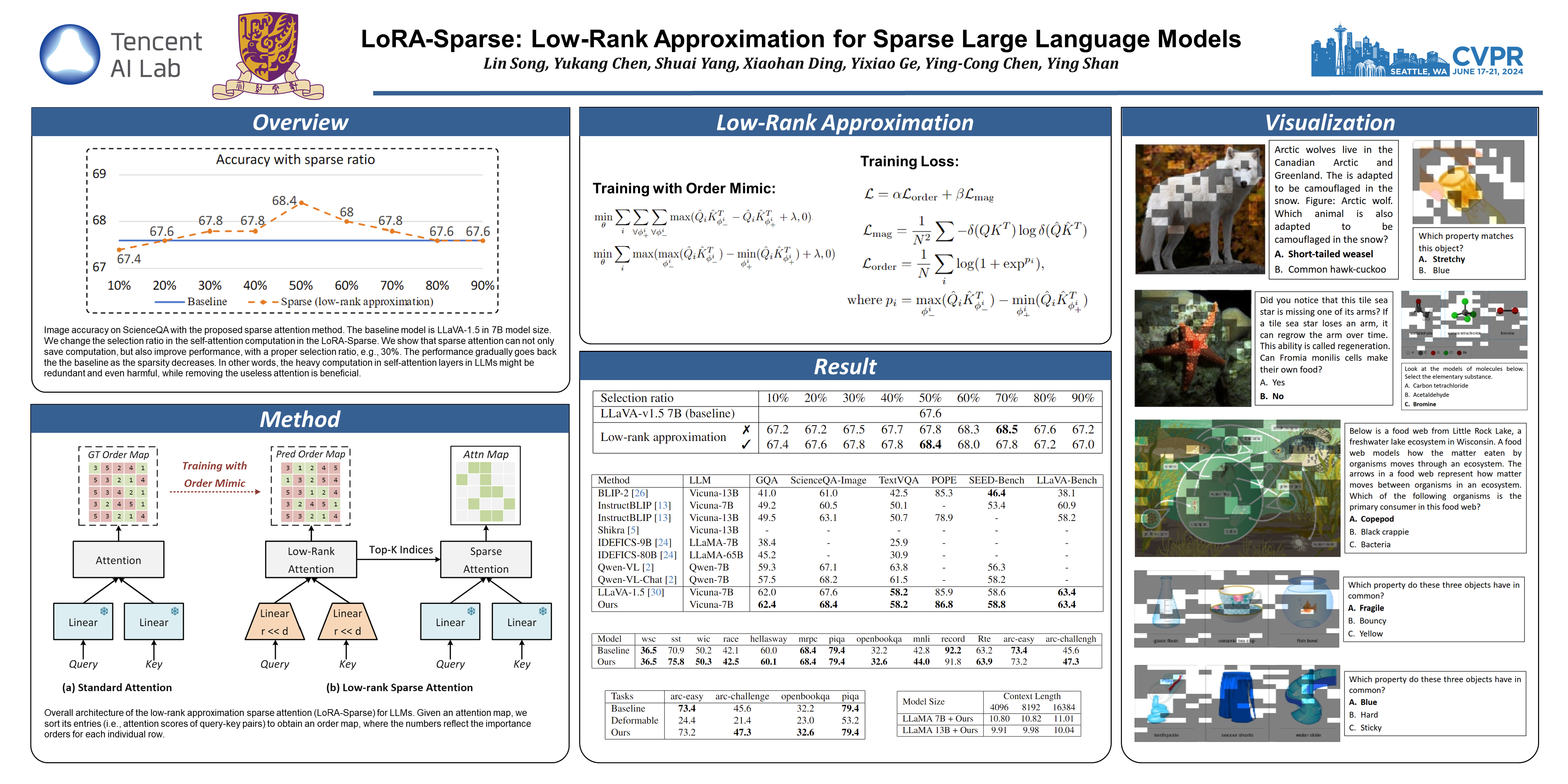
This paper focuses on the high computational complexity in Large Language Models (LLMs), a significant challenge in both natural language processing (NLP) and multi-modal tasks. We propose Low-Rank Approximation for Sparse Attention (LoRA-Sparse), an innovative approach that strategically reduces this complexity. LoRA-Sparse introduces low-rank linear projection layers for sparse attention approximation. It utilizes an order-mimic training methodology, which is crucial for efficiently approximating the self-attention mechanism in LLMs. We empirically show that sparse attention not only reduces computational demands, but also enhances model performance in both NLP and multi-modal tasks. This surprisingly shows that redundant attention in LLMs might be non-beneficial. We extensively validate LoRA-Sparse through rigorous empirical studies in both (NLP) and multi-modal tasks, demonstrating its effectiveness and general applicability. Based on LLaMA and LLaVA models, our methods can reduce more than half of the self-attention computation with even better performance than full-attention baselines. Code will be made available.