Poster
AM-RADIO: Agglomerative Vision Foundation Model Reduce All Domains Into One
Mike Ranzinger · Greg Heinrich · Jan Kautz · Pavlo Molchanov
Arch 4A-E Poster #277
{kind=link}
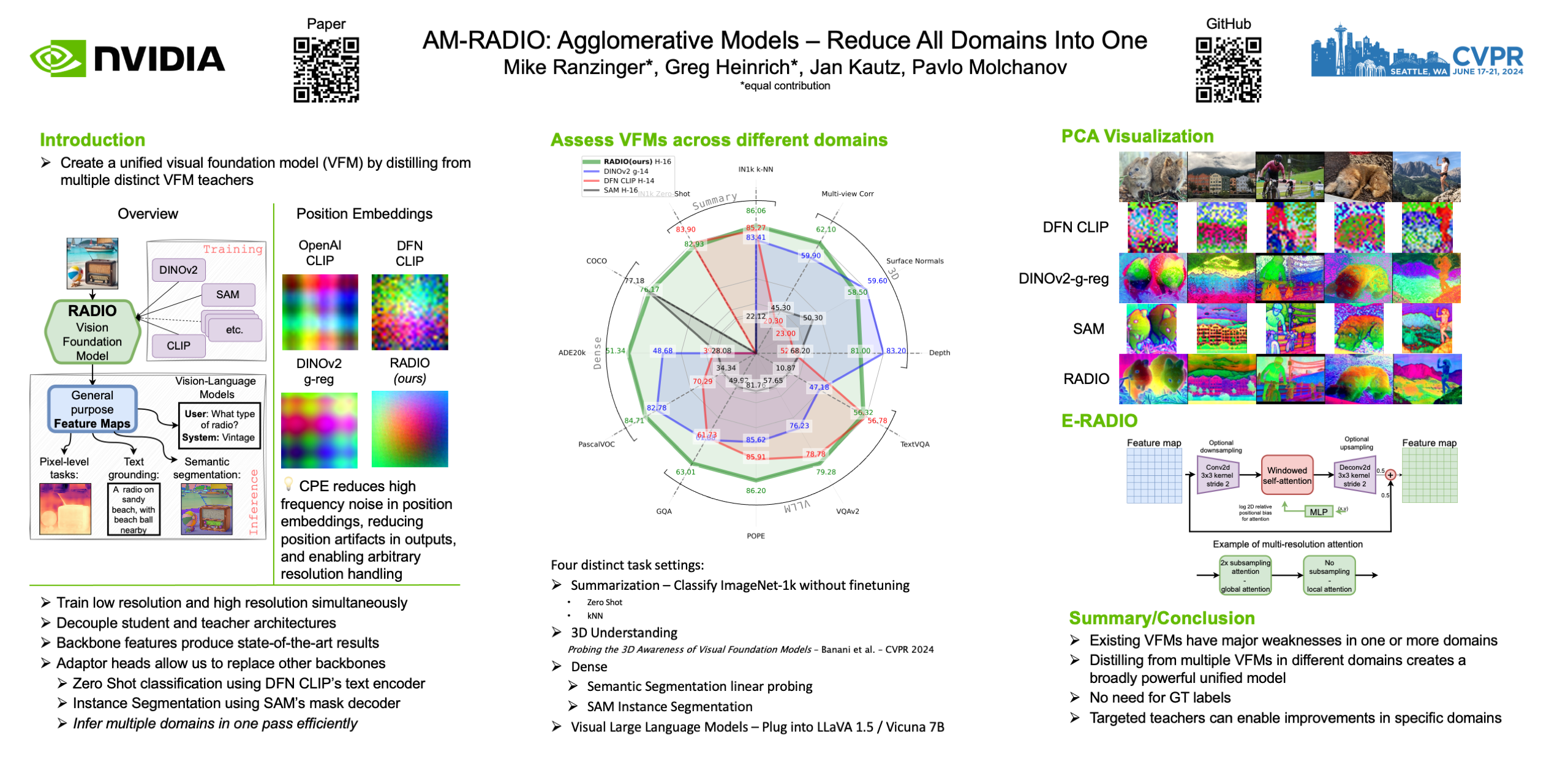
A handful of visual foundation models (VFMs) have recently emerged as the backbones for numerous downstream tasks. VFMs like CLIP, DINOv2, SAM are trained with distinct objectives, exhibiting unique characteristics for various downstream tasks. We find that despite their conceptual differences, these models can be effectively merged into a unified model through multi-teacher distillation. We name this approach AM-RADIO (Agglomerative Model -- Reduce All Domains Into One). This integrative approach not only surpasses the performance of individual teacher models but also amalgamates their distinctive features, such as zero-shot vision-language comprehension, detailed pixel-level understanding, and open vocabulary segmentation capabilities. In pursuit of the most hardware-efficient backbone, we evaluated numerous architectures in our multi-teacher distillation pipeline using the same training recipe. This led to the development of a novel architecture (E-RADIO) that exceeds the performance of its predecessors and is at least 7x faster than the teacher models. Our comprehensive benchmarking process covers downstream tasks including ImageNet classification, ADE20k semantic segmentation, COCO object detection and LLaVa-1.5 framework.