{kind=link}
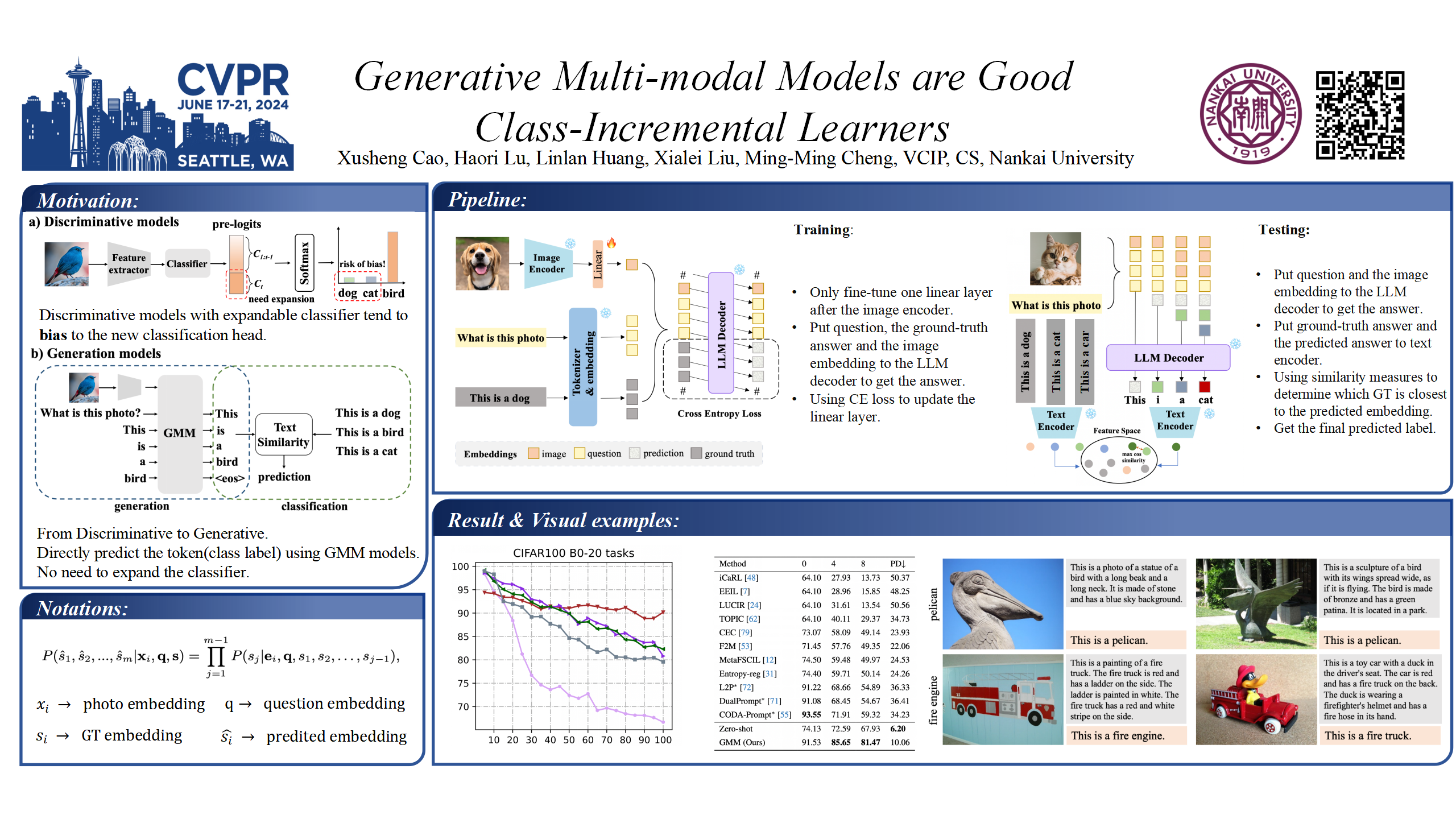
In class incremental learning (CIL) scenarios, the phenomenon of catastrophic forgetting caused by the classifier's bias towards the current task has long posed a significant challenge. It is mainly caused by the characteristic of discriminative models. With the growing popularity of the generative multi-modal models, we would explore replacing discriminative models with generative ones for CIL. However, transitioning from discriminative to generative models requires addressing two key challenges. The primary challenge lies in transferring the generated textual information into the classification of distinct categories. Additionally, it requires formulating the task of CIL within a generative framework. To this end, we propose a novel generative multi-modal model (GMM) framework for class incremental learning. Our approach directly generates labels for images using an adapted generative model. After obtaining the detailed text, we use a text encoder to extract text features and employ feature matching to determine the most similar label as the classification prediction. In the conventional CIL settings, we achieve significantly better results in long-sequence task scenarios. Under the Few-shot CIL setting, we have improved by at least 14% over the current state-of-the-art methods with significantly less forgetting.