{kind=link}
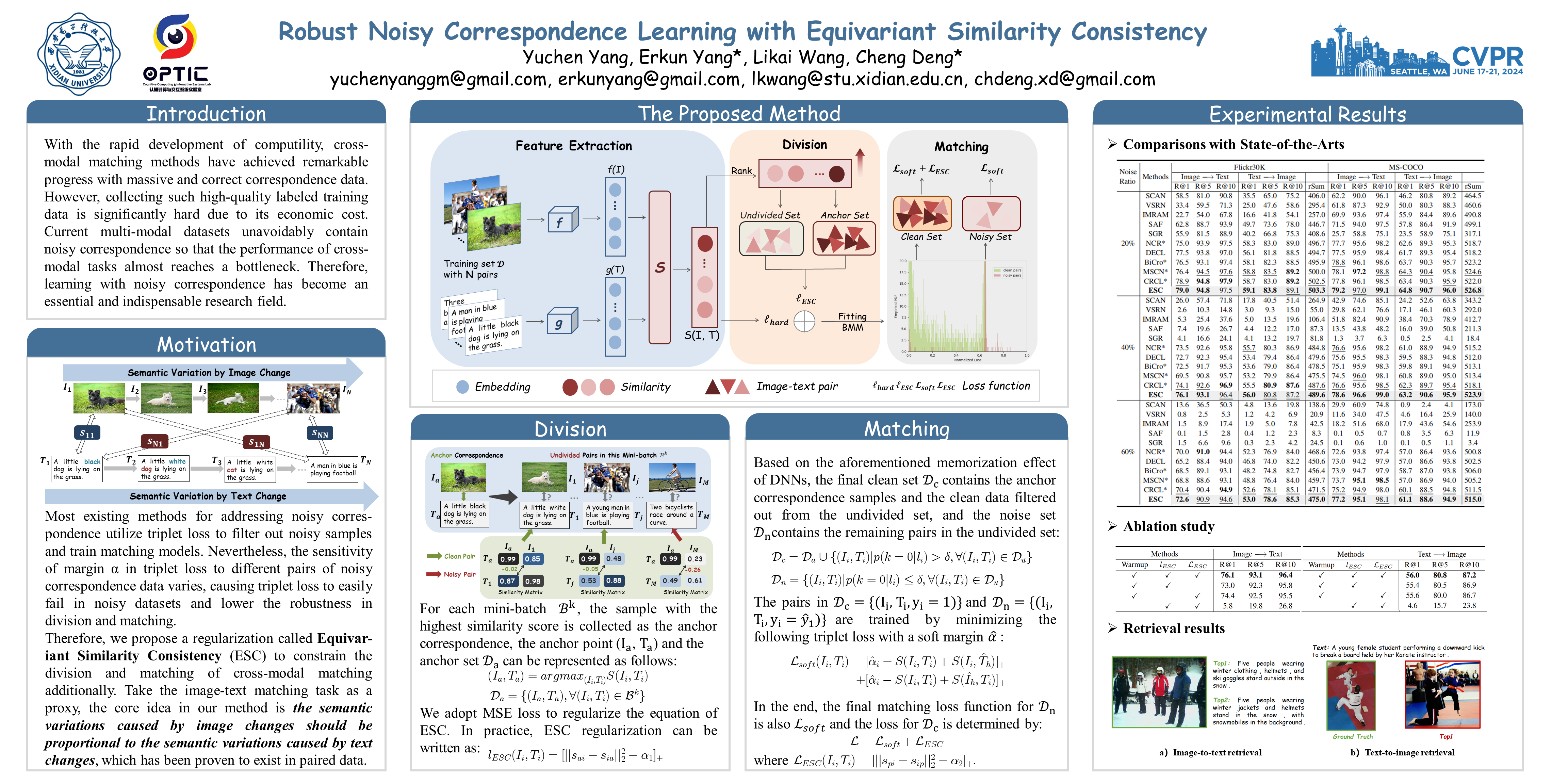
The surge in multi-modal data has propelled cross-modal matching to the forefront of research interest. However, the challenge lies in the laborious and expensive process of curating a large and accurately matched multi-modal dataset. Commonly sourced from the Internet, these datasets often suffer from a significant presence of mismatched data, impairing the performance of matching models. To address this problem, we introduce a novel regularization approach named Equivariant Similarity Consistency (ESC), which can facilitate robust clean and noisy data separation and improve the training for cross-modal matching. Intuitively, our method posits that the semantic variations caused by image changes should be proportional to those caused by text changes for any two matched samples. Accordingly, we first calculate the ESC by comparing image and text semantic variations between a set of elaborated anchor points and other undivided training data. Then, pairs with high ESC are filtered out as noisy correspondence pairs. We implement our method by combining the ESC with a traditional hinge-based triplet loss. Extensive experiments on three widely used datasets, including Flickr30K, MS-COCO, and Conceptual Captions, verify the effectiveness of our method.