Poster
Carve3D: Improving Multi-view Reconstruction Consistency for Diffusion Models with RL Finetuning
Desai Xie · Jiahao Li · Hao Tan · Xin Sun · Zhixin Shu · Yi Zhou · Sai Bi · Soren Pirk · ARIE KAUFMAN
Arch 4A-E Poster #152
{kind=link}
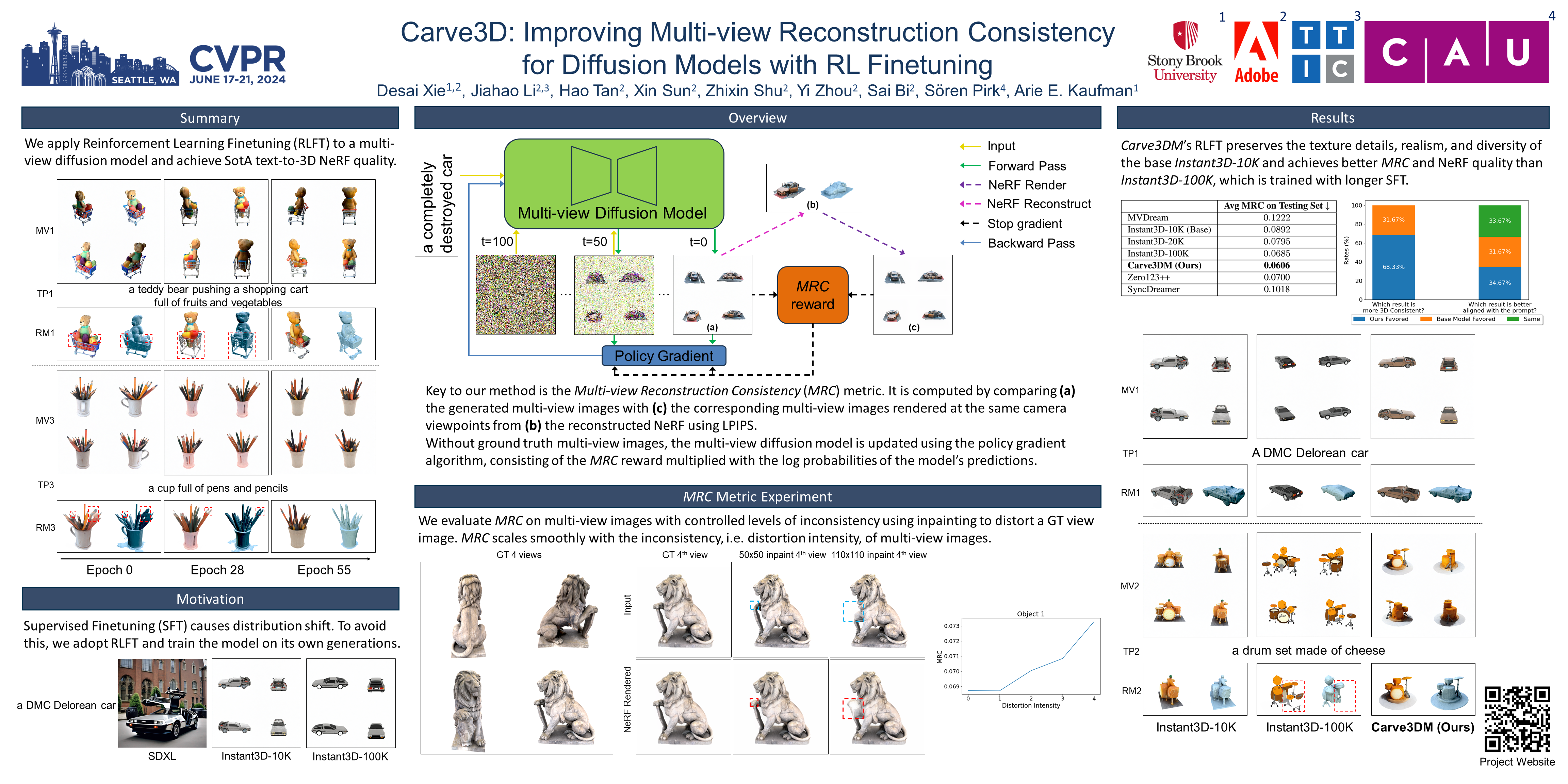
Multi-view diffusion models, obtained by applying Supervised Finetuning (SFT) to text-to-image diffusion models, have driven recent breakthroughs in text-to-3D research. However, due to the limited size and quality of existing 3D datasets, they still suffer from multi-view inconsistencies and Neural Radiance Field (NeRF) reconstruction artifacts. We argue that multi-view diffusion models can benefit from further Reinforcement Learning Finetuning (RLFT), which allows models to learn from the data generated by themselves and improve beyond their dataset limitations during SFT. To this end, we introduce Carve3D, an improved RLFT algorithm coupled with a novel Multi-view Reconstruction Consistency (MRC) metric, to enhance the consistency of multi-view diffusion models. To measure the MRC metric on a set of multi-view images, we compare them with their corresponding NeRF renderings at the same camera viewpoints. The resulting model, which we denote as Carve3DM, demonstrates superior multi-view consistency and NeRF reconstruction quality than existing models. Our results suggest that pairing SFT with Carve3D's RLFT is essential for developing multi-view-consistent diffusion models, mirroring the standard Large Language Model (LLM) alignment pipeline. Our code, training and testing data, and video results are available at: https://desaixie.github.io/carve-3d.