{kind=link}
Abstract:
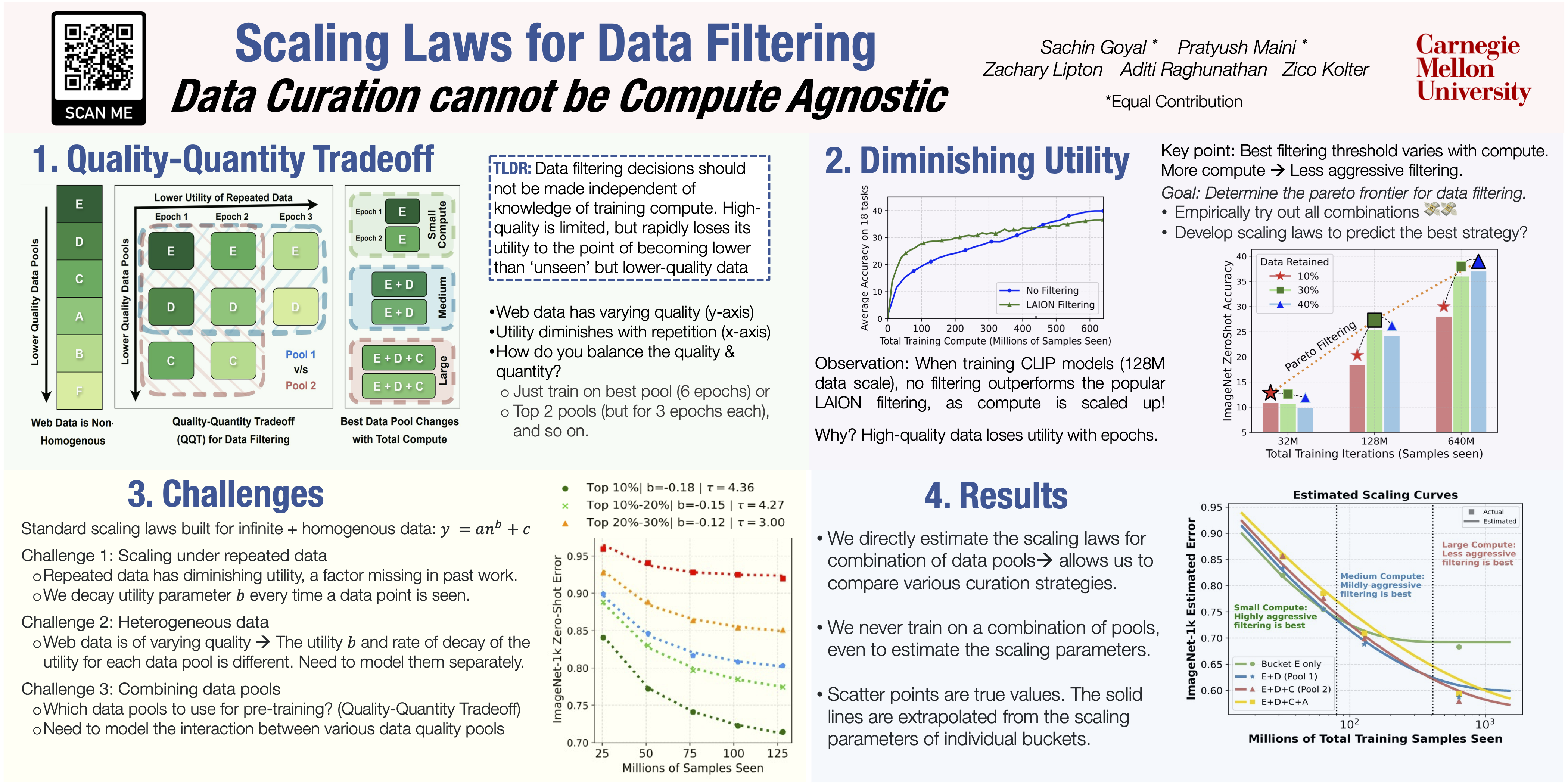
Vision-language models (VLMs) are trained for thousands of GPU hours on massive web scrapes, but they are not trained on all data indiscriminately. For instance, the LAION public dataset retained only about 10\% of the total crawled data. In recent times, data curation has gained prominence with several works developing strategies to retain "high-quality" subsets of "raw" scraped data. However, these strategies are typically developed agnostic to the available compute for training. In this paper, we demonstrate that making filtering decisions independent of training compute is often suboptimal---well-curated data rapidly loses its utilitywhen repeated, eventually decreasing below the utility of "unseen" but "lower-quality" data. In fact, we show that even a model trained on $\textit{unfiltered common crawl}$ obtains higher accuracy than that trained on the LAION dataset post 40 or more repetitions.While past research in neural scaling laws has considered web data to be homogenous, real data is not.Our work bridges this important gap in the literature by developing scaling trends that characterize the "utility" of various data subsets, accounting for the diminishing utility of a data point at its "nth" repetition.Our key message is that data curation $\textit{can not}$ be agnostic of the total compute a model will be trained for. Based on our analysis, we propose FADU (Filter by Assessing Diminishing Utility) that curates the best possible pool for achieving top performance on Datacomp at various compute budgets, carving out a pareto-frontier for data curation.
Chat is not available.