{kind=link}
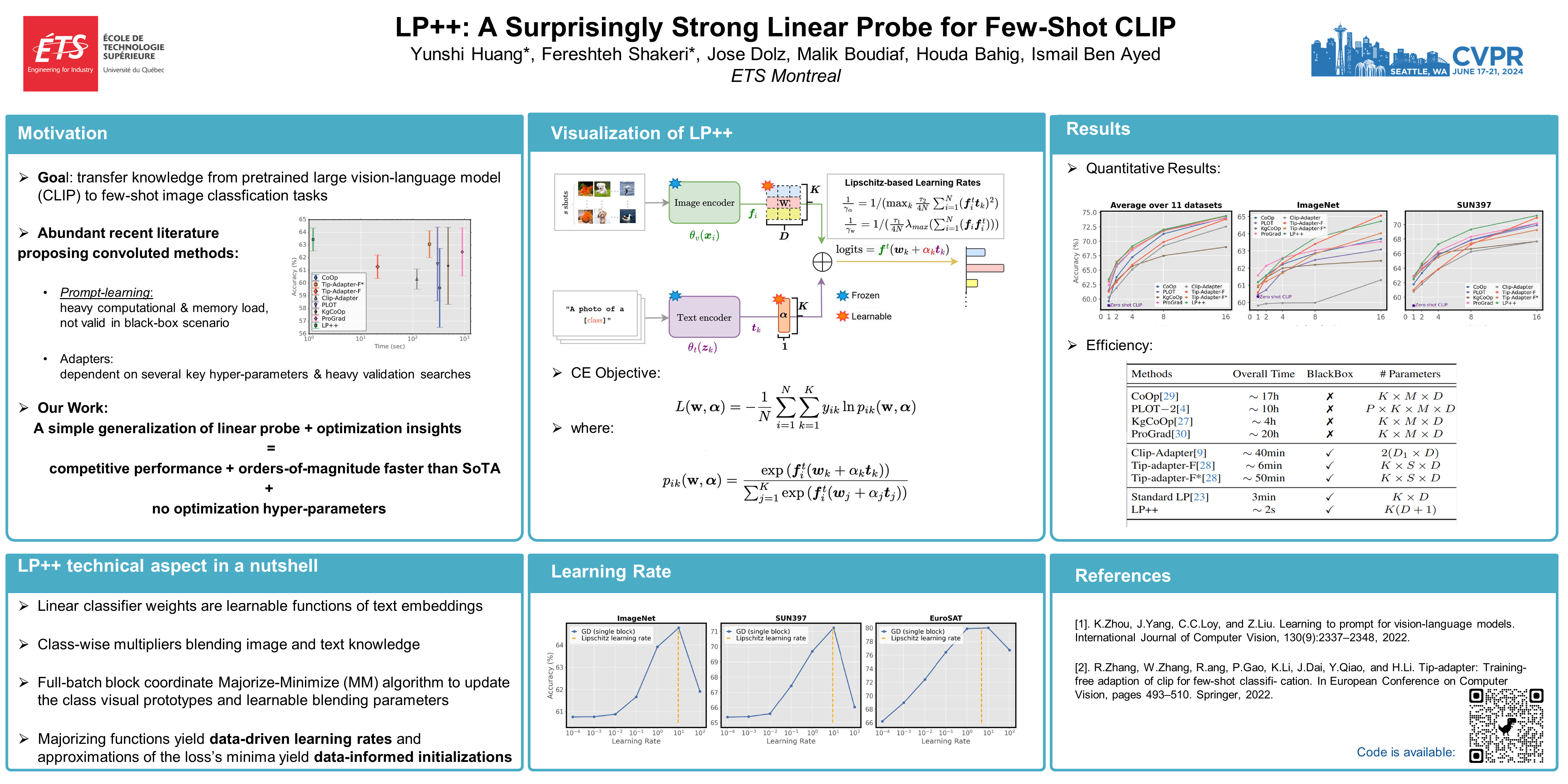
In a recent, strongly emergent literature on few-shot CLIP adaptation, Linear Probe (LP) has been often reported as a weak baseline. This has motivated intensive research building convoluted prompt learning or feature adaptation strategies. In this work, we propose and examine from convex-optimization perspectives a generalization of the standard LP baseline, in which the linear classifier weights are learnable functions of the text embedding, with class-wise multipliers blending image and text knowledge. As our objective function depends on two types of variables, i.e., the class visual prototypes and the learnable blending parameters, we propose a computationally efficient block coordinate Majorize-Minimize (MM) descent algorithm. In our full-batch MM optimizer, which we coin LP++, step sizes are implicit, unlike standard gradient descent practices where learning rates are intensively searched over validation sets. By examining the mathematical properties of our loss (e.g., Lipschitz gradient continuity), we build majorizing functions yielding data-driven learning rates and derive approximations of the loss's minima, which provide data-informed initialization of the variables. Our image-language objective function, along with these non-trivial optimization insights and ingredients, yields, surprisingly, highly competitive few-shot CLIP performances. Furthermore, LP++ operates in black-box, relaxes intensive validation searches for the optimization hyper-parameters, and runs orders-of-magnitudes faster than state-of-the-art few-shot CLIP adaptation methods. Our code is available at: \url{https://github.com/FereshteShakeri/FewShot-CLIP-Strong-Baseline.git}.