{kind=link}
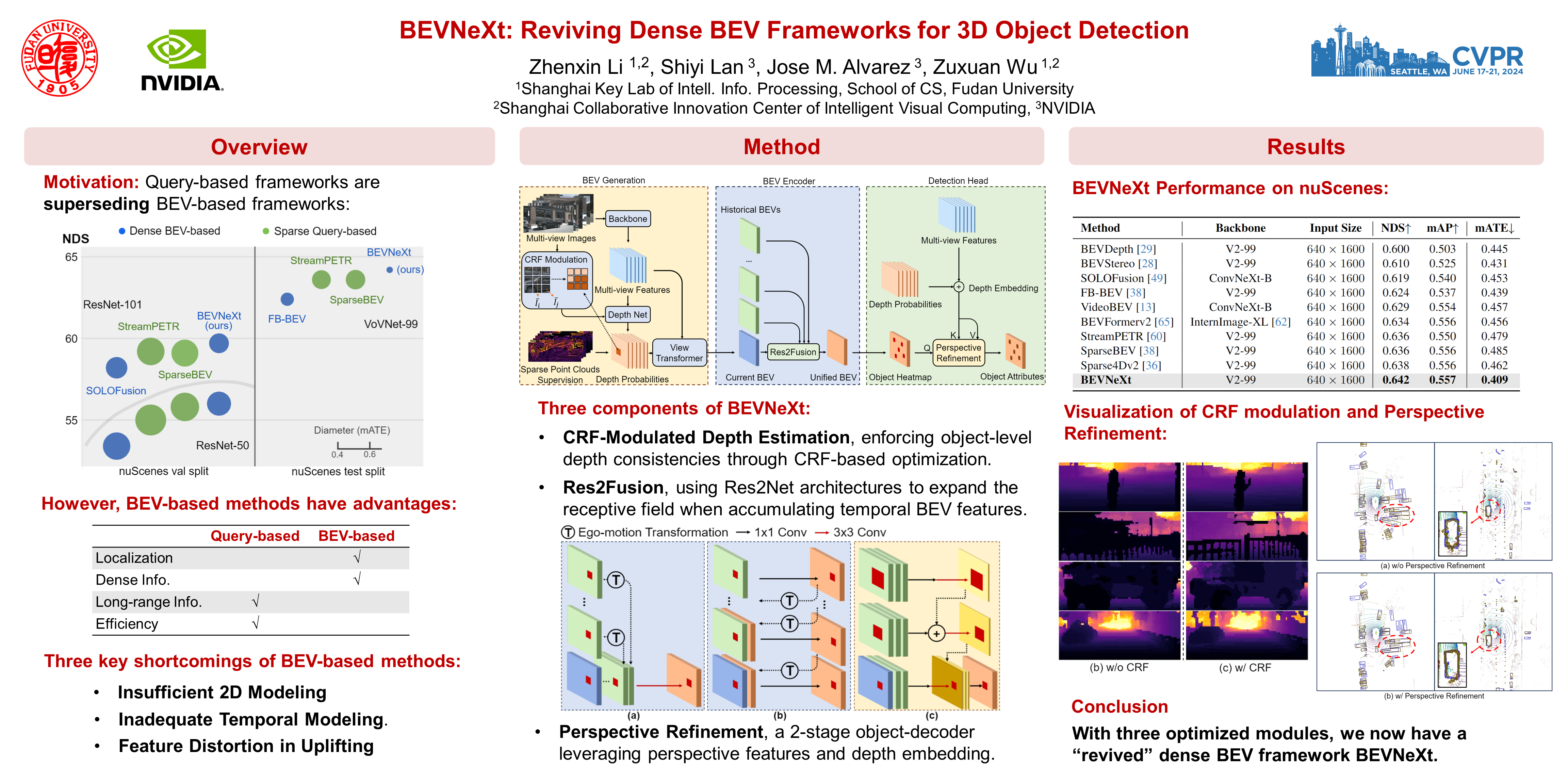
Recently, the rise of query-based Transformer decoders is reshaping camera-based 3D object detection. These query-based decoders are surpassing the traditional dense BEV (Bird's Eye View)-based methods. However, we argue that dense BEV frameworks remain important due to their outstanding abilities in depth estimation and object localization, depicting 3D scenes accurately and comprehensively. This paper aims to address the drawbacks of the existing dense BEV-based 3D object detectors by introducing our proposed enhanced components, including a CRF-modulated depth estimation module enforcing object-level consistencies, a long-term temporal aggregation module with extended receptive fields, and a two-stage object decoder combining perspective techniques with CRF-modulated depth embedding. These enhancements lead to a ``modernized'' dense BEV framework dubbed BEVNeXt. On the nuScenes benchmark, BEVNeXt outperforms both BEV-based and query-based frameworks under various settings, achieving a state-of-the-art result of 64.2 NDS on the nuScenes test set.