{kind=link}
Abstract:
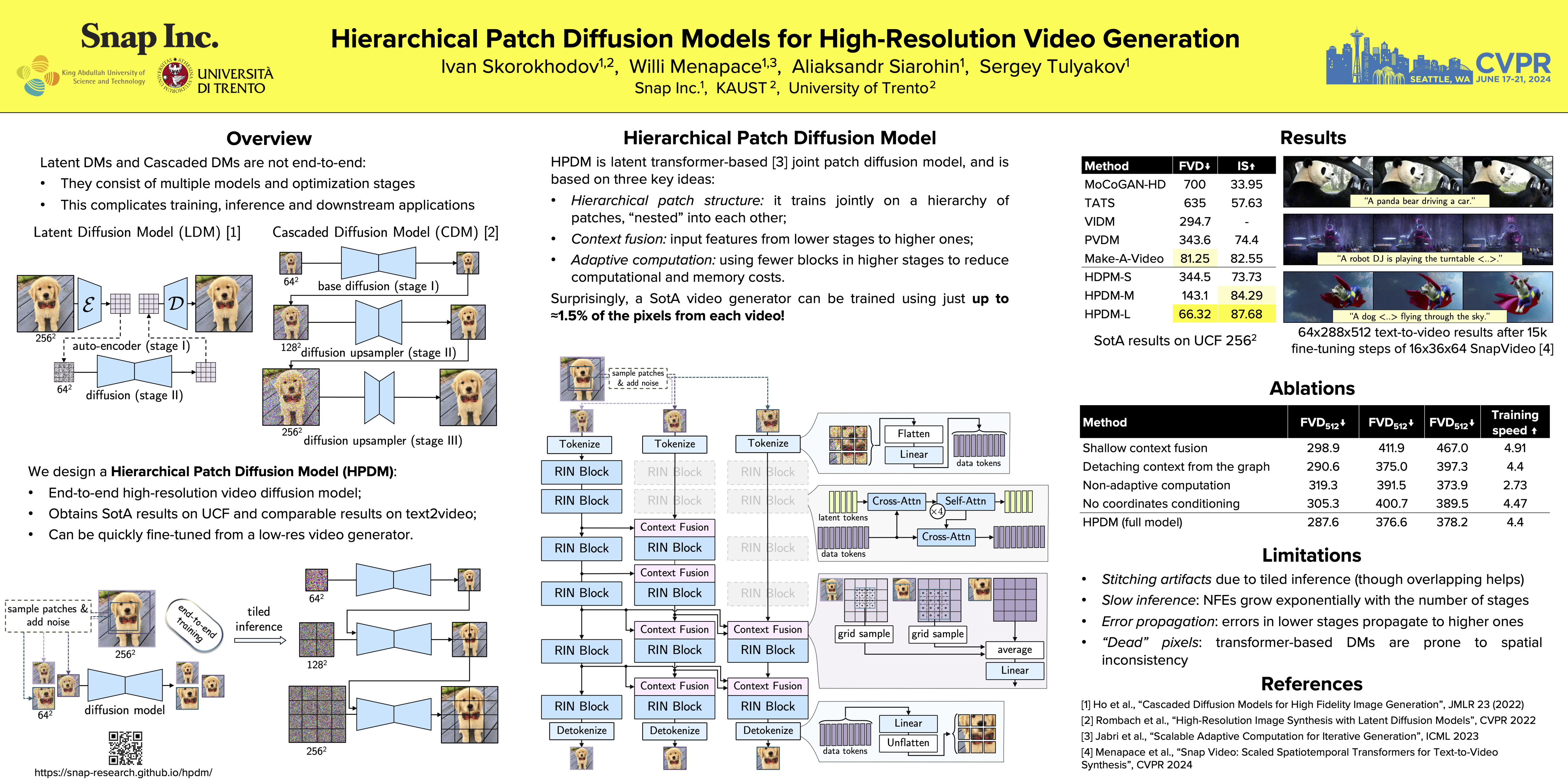
Diffusion models have demonstrated remarkable performance in image and video synthesis. However, scaling them to high-resolution inputs is challenging and requires restructuring the diffusion pipeline into multiple independent components, limiting scalability and complicating downstream applications. In this work, we study patch diffusion models (PDMs) --- a diffusion paradigm which models the distribution of patches, rather than whole inputs, keeping up to ${\approx}$0.7\% of the original pixels. This makes it very efficient during training and unlocks end-to-end optimization on high-resolution videos. We improve PDMs in two principled ways. First, to enforce consistency between patches, we develop \emph{deep context fusion} --- an architectural technique that propagates the context information from low-scale to high-scale patches in a hierarchical manner. Second, to accelerate training and inference, we propose \emph{adaptive computation}, which allocates more network capacity and computation towards coarse image details. The resulting model sets a new state-of-the-art FVD score of 66.32 and Inception Score of 87.68 in class-conditional video generation on UCF-101 $256^2$, surpassing recent methods by more than 100\%. Then, we show that it can be rapidly fine-tuned from a base $36\times 64$ low-resolution generator for high-resolution $64 \times 288 \times 512$ text-to-video synthesis. To the best of our knowledge, our model is the first diffusion-based architecture which is trained on such high resolutions entirely end-to-end. Project webpage: https://snap-research.github.io/hpdm.
Chat is not available.