Poster
Summarize the Past to Predict the Future: Natural Language Descriptions of Context Boost Multimodal Object Interaction Anticipation
Razvan Pasca · Alexey Gavryushin · Muhammad Hamza · Yen-Ling Kuo · Kaichun Mo · Luc Van Gool · Otmar Hilliges · Xi Wang
Arch 4A-E Poster #356
{kind=link}
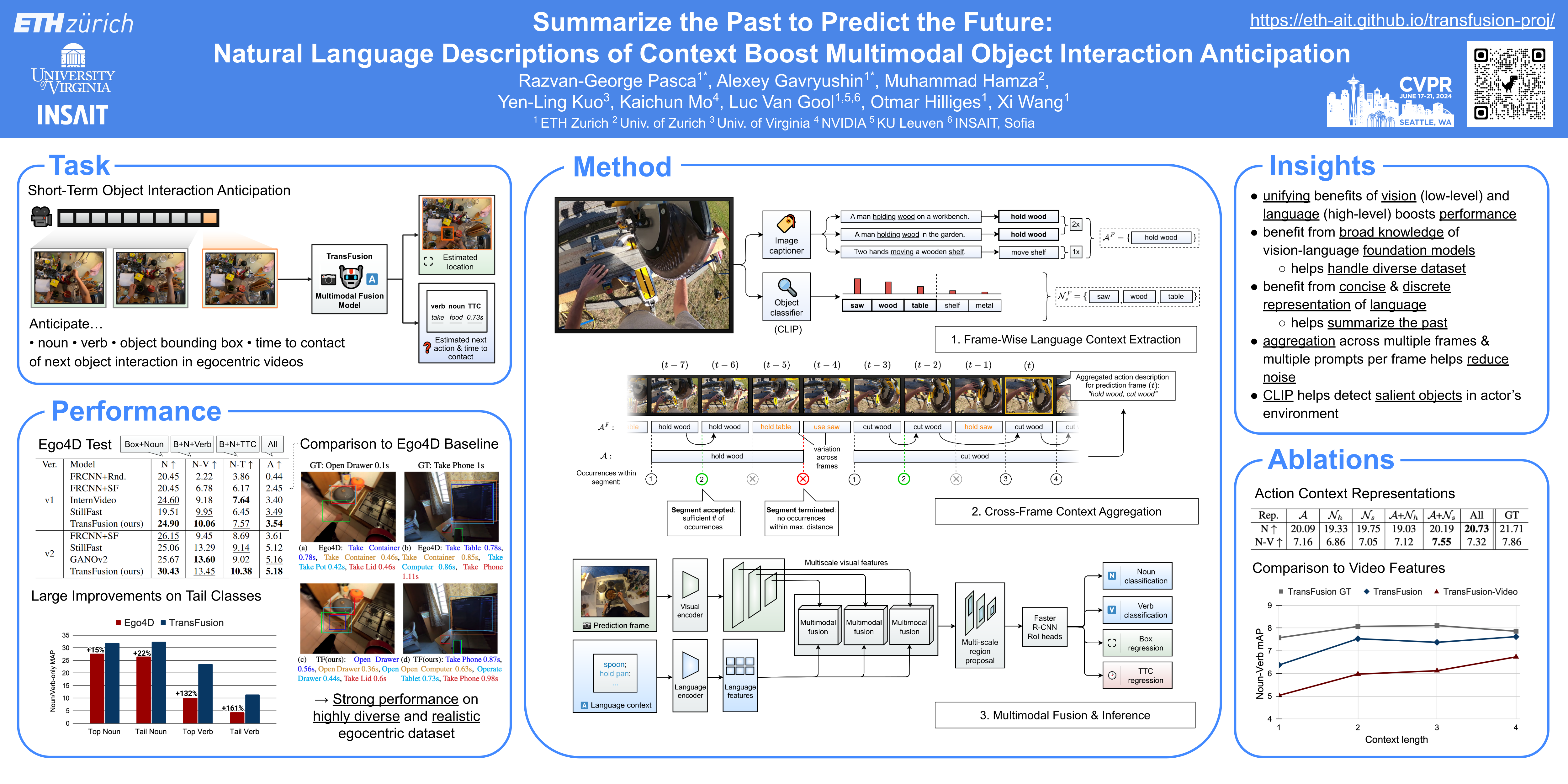
We study object interaction anticipation in egocentric videos. This task requires an understanding of the spatio-temporal context formed by past actions on objects, coined "action context". We propose TransFusion, a multimodal transformer-based architecture for short-term object interaction anticipation. Our method exploits the representational power of language by summarizing the action context textually, after leveraging pre-trained vision-language foundation models to extract the action context from past video frames. The summarized action context and the last observed video frame are processed by the multimodal fusion module to forecast the next object interaction. Experiments on the Ego4D next active object interaction dataset show the effectiveness of our multimodal fusion model and highlight the benefits of using the power of foundation models and language-based context summaries in a task where vision may appear to suffice. Our novel approach outperforms all state-of-the-art methods on both versions of the Ego4D dataset.