{kind=link}
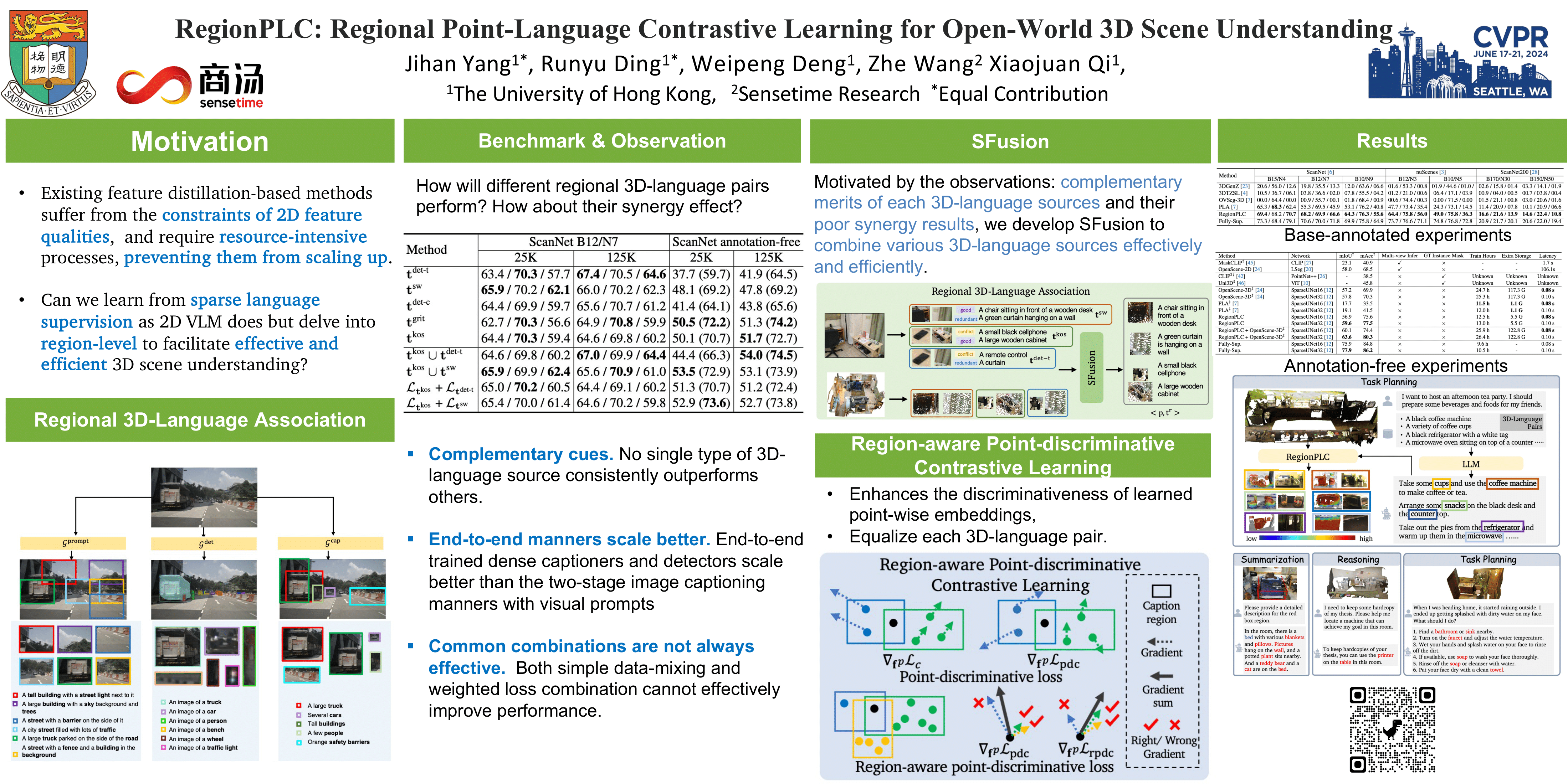
We propose a lightweight and scalable Regional Point-Language Contrastive learning framework, namely RegionPLC, for open-world 3D scene understanding, aiming to identify and recognize open-set objects and categories. Specifically, based on our empirical studies, we introduce a 3D-aware SFusion strategy that fuses 3D vision-language pairs derived from multiple 2D foundation models, yielding high-quality, dense region-level language descriptions without human 3D annotations. Subsequently, we devise a region-aware point-discriminative contrastive learning objective to enable robust and effective 3D learning from dense regional language supervision. We carry out extensive experiments on ScanNet, ScanNet200, and nuScenes datasets, and our model outperforms prior 3D open-world scene understanding approaches by an average of 17.2\% and 9.1\% for semantic and instance segmentation, respectively, while maintaining greater scalability and lower resource demands. Furthermore, our method has the flexibility to be effortlessly integrated with language models to enable open-ended grounded 3D reasoning without extra task-specific training. Code will be released.