{kind=link}
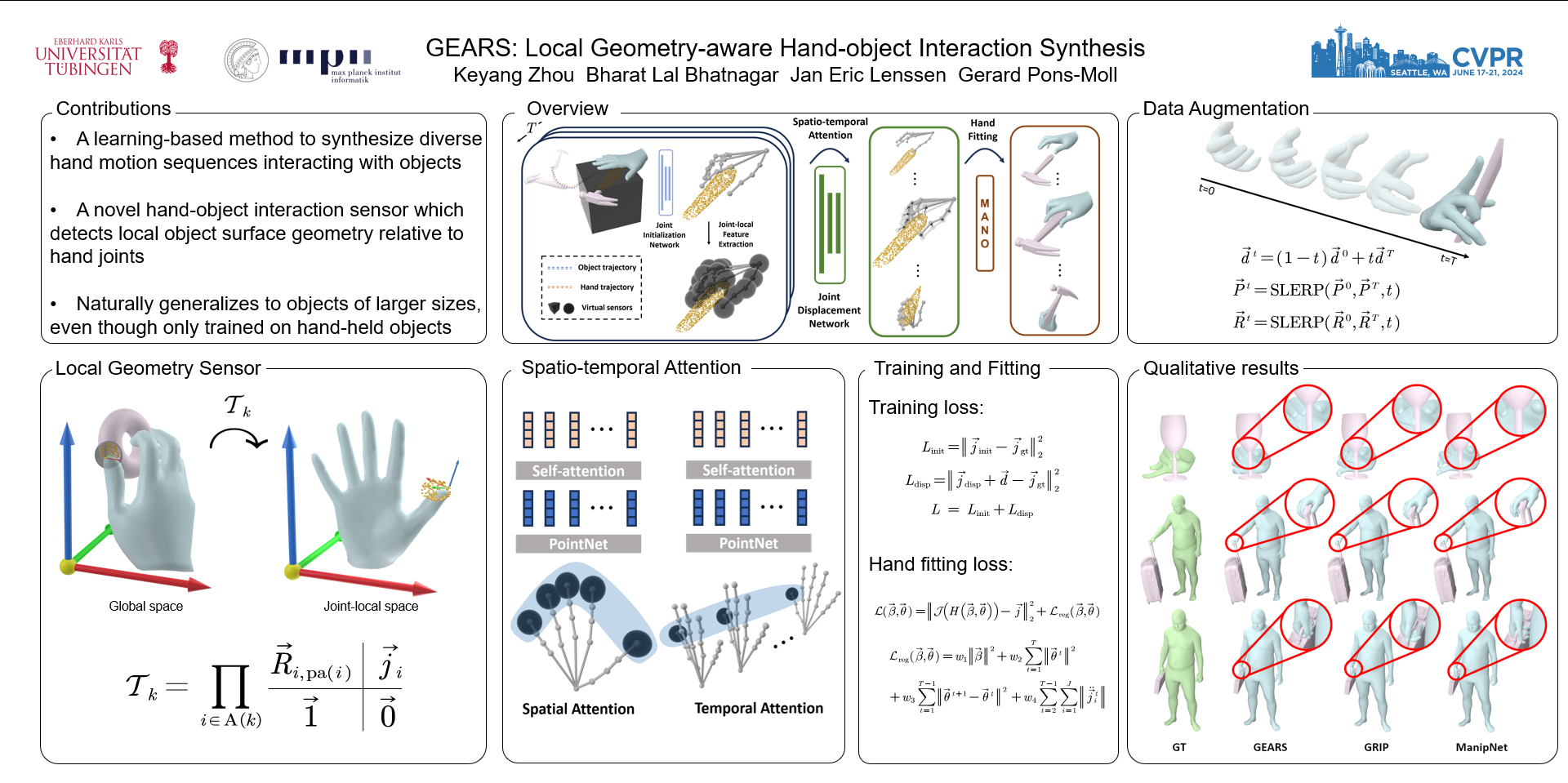
Generating realistic hand motion sequences in interaction with objects has gained increasing attention with the growing interest in digital humans. Prior work has illustrated the effectiveness of employing occupancy-based or distance-based virtual sensors to extract hand-object interaction features. Nonetheless, these methods show limited generalizability across object categories, shapes and sizes. We hypothesize that this is due to two reasons: 1) the limited expressiveness of employed virtual sensors, and 2) scarcity of available training data. To tackle this challenge, we introduce a novel joint-centered sensor designed to reason about local object geometry near potential interaction regions. The sensor queries for object surface points in the neighbourhood of each hand joint. As an important step towards mitigating the learning complexity, we transform the points from global frame to hand template frame and use a shared module to process sensor features of each individual joint. This is followed by a spatio-temporal transformer network aimed at capturing correlation among the joints in different dimensions. Moreover, we devise simple heuristic rules to augment the limited training sequences with vast static hand grasping samples. This leads to a broader spectrum of grasping types observed during training, in turn enhancing our model's generalization capability. We evaluate on two public datasets, GRAB and InterCap, where our method shows superiority over baselines both quantitatively and perceptually. We will release our code and model for further research in this field.