{kind=link}
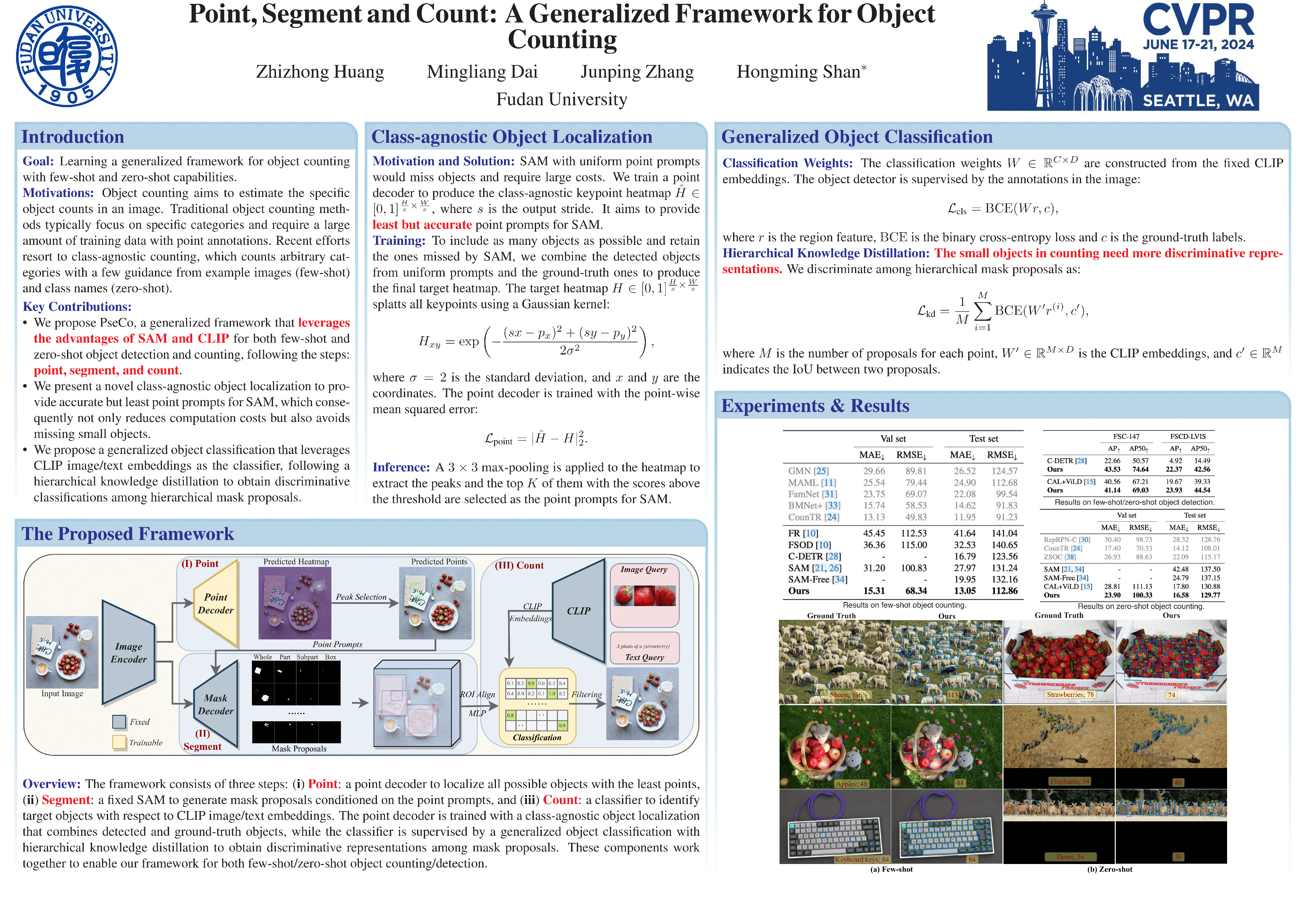
Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147, COCO, and LVIS demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection. Code: https://github.com/Hzzone/PseCo