Poster
InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models
Jiun Tian Hoe · Xudong Jiang · Chee Seng Chan · Yap-peng Tan · Weipeng Hu
Arch 4A-E Poster #134
{kind=link}
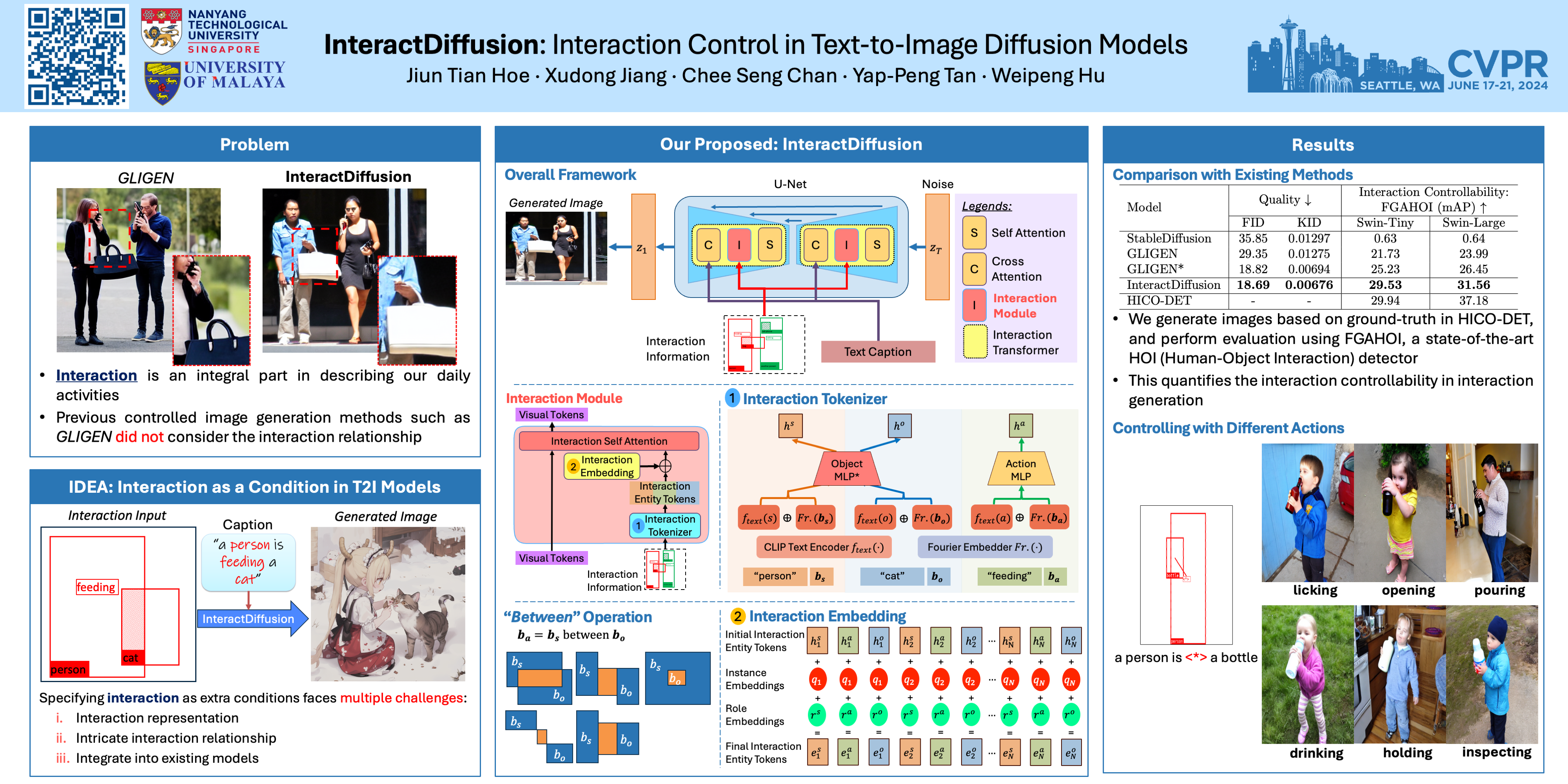
Large-scale text-to-image (T2I) diffusion models have showcased incredible capabilities in generating coherent images based on textual descriptions, enabling vast applications in content generation. While recent advancements have introduced control over factors such as object localization, posture, and image contours, a crucial gap remains in our ability to control the interactions between objects in the generated content. Well-controlling interactions in generated images could yield meaningful applications, such as creating realistic scenes with interacting characters. In this work, we study the problems of conditioning T2I diffusion models with Human-Object Interaction (HOI) information, consisting of a triplet label (person, action, object) and corresponding bounding boxes. We propose a pluggable interaction control model, called InteractDiffusion that extends existing pre-trained T2I diffusion models to enable them being better conditioned on interactions. Specifically, we tokenize the HOI information and learn their relationships via interaction embeddings. A conditioning self-attention layer is trained to map HOI tokens to visual tokens, thereby conditioning the visual tokens better in existing T2I diffusion models. Our model attains the ability to control the interaction and location on existing T2I diffusion models, which outperforms existing baselines by a large margin in HOI detection score, as well as fidelity in FID and KID. The code will be made available.