{kind=link}
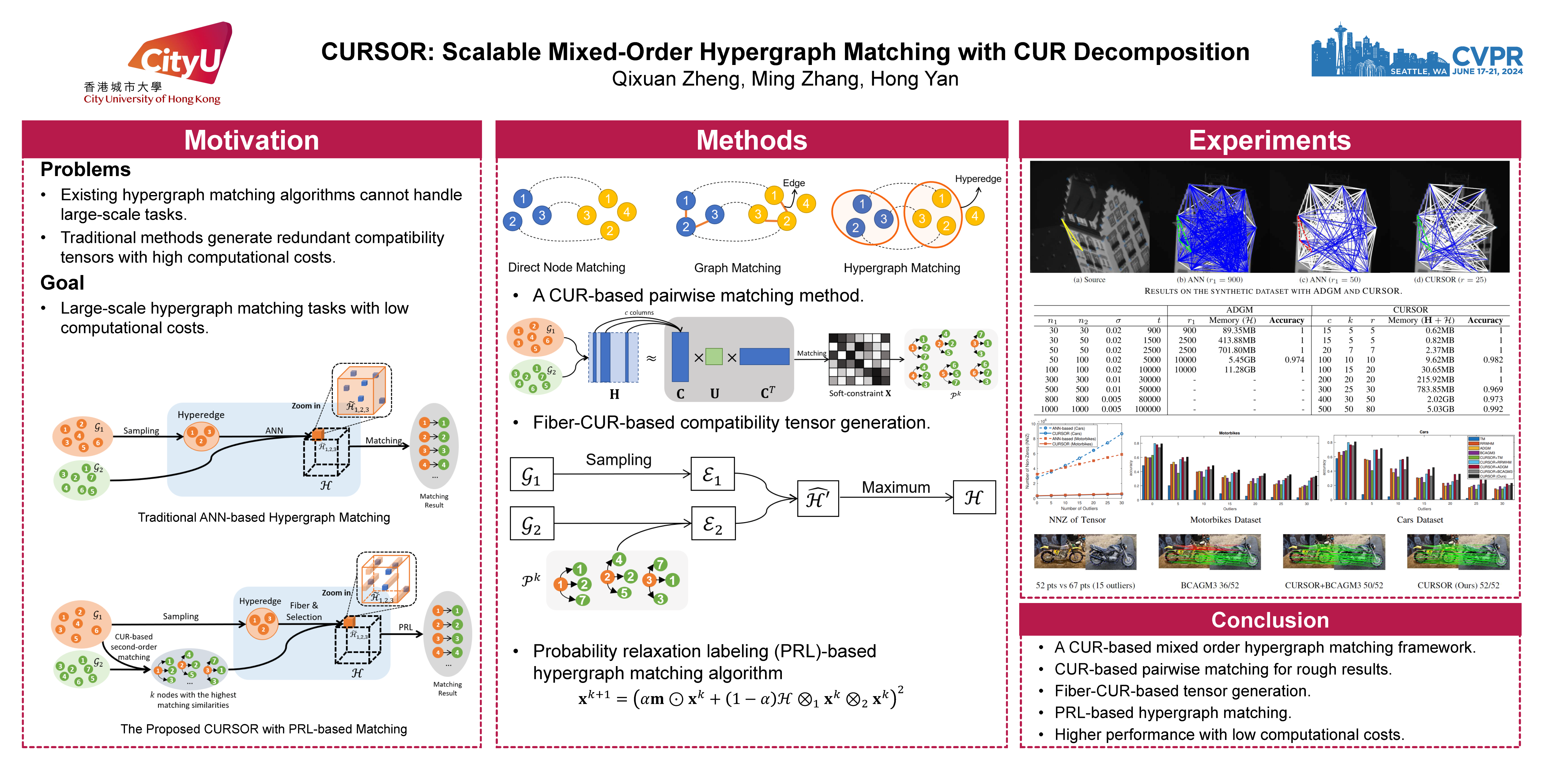
To achieve greater accuracy, hypergraph matching algorithms require exponential increases in computational resources. Recent kd-tree-based approximate nearest neighbor (ANN) methods, despite the sparsity of their compatibility tensor, still require exhaustive calculations for large-scale graph matching. This work utilizes CUR tensor decomposition and introduces a novel cascaded second and third-order hypergraph matching framework (CURSOR) for efficient hypergraph matching. A CUR-based second-order graph matching algorithm is used to provide a rough match, and then the core of CURSOR, a fiber-CUR-based tensor generation method, directly calculates entries of the compatibility tensor by leveraging the initial second-order match result. This significantly decreases the time complexity and tensor density. A probability relaxation labeling (PRL)-based matching algorithm, especially suitable for sparse tensors, is developed. Experiment results on large-scale synthetic datasets and widely-adopted benchmark sets demonstrate the superiority of CURSOR over existing methods. The tensor generation method in CURSOR can be integrated seamlessly into existing hypergraph matching methods to improve their performance and lower their computational costs.