{kind=link}
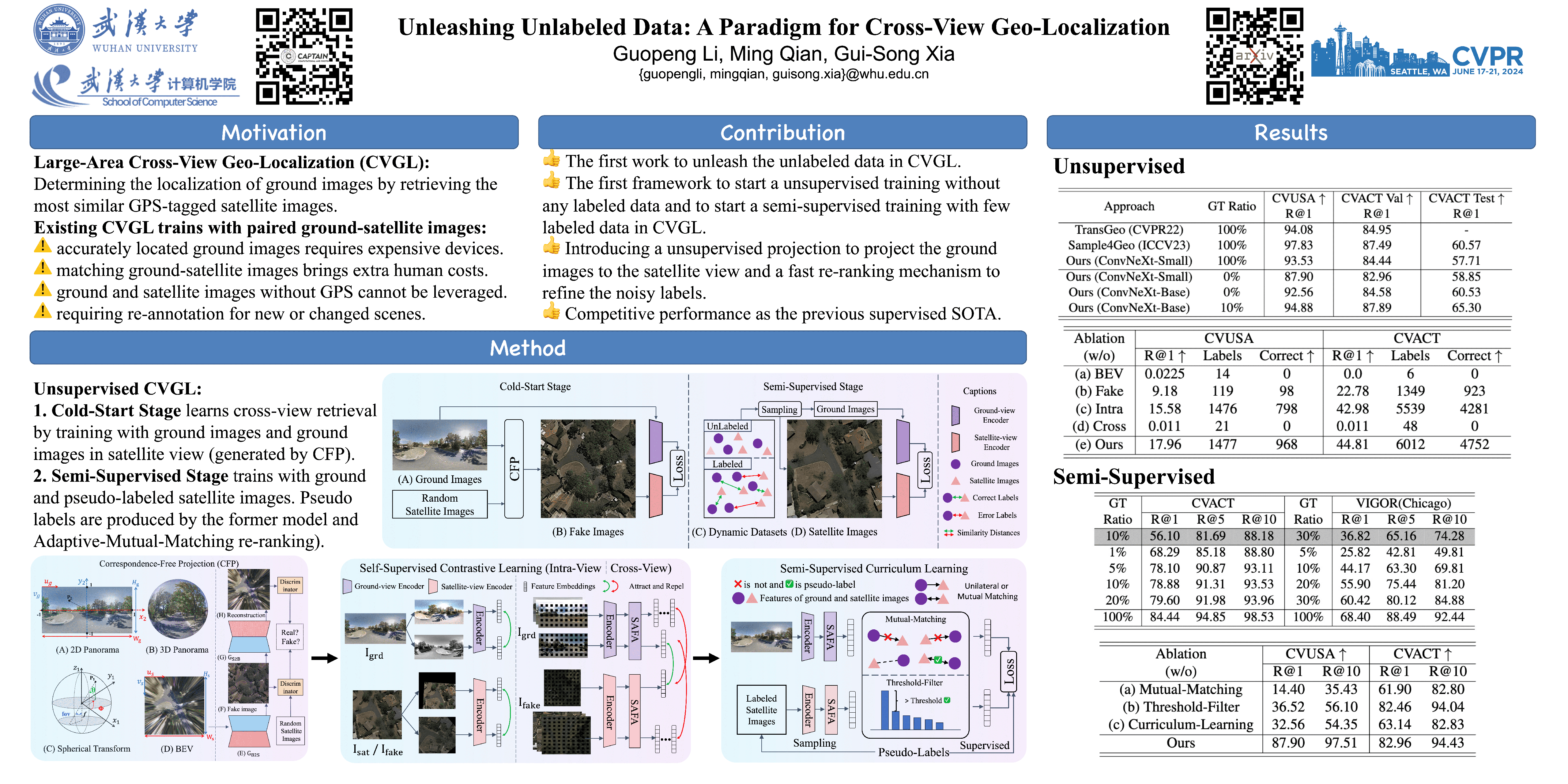
This paper investigates the effective utilization of unlabeled data for large-area cross-view geo-localization (CVGL), encompassing both unsupervised and semi-supervised settings. Common approaches to CVGL rely on ground-satellite image pairs and employ label-driven supervised training. However, the cost of collecting precise cross-view image pairs hinders the deployment of CVGL in real-life scenarios. Without the pairs, CVGL will be more challenging to handle the significant imaging and spatial gaps between ground and satellite images. To this end, we propose an unsupervised framework including a cross-view projection to guide the model for retrieving initial pseudo-labels and a fast re-ranking mechanism to refine the pseudo-labels by leveraging the fact that ``the perfectly paired ground-satellite image is located in a unique and identical scene". The framework exhibits competitive performance compared with supervised works on three open-source benchmarks. Our code and models will be released on https://github.com/liguopeng0923/UCVGL.