Poster
VSRD: Instance-Aware Volumetric Silhouette Rendering for Weakly Supervised 3D Object Detection
Zihua Liu · Hiroki Sakuma · Masatoshi Okutomi
Arch 4A-E Poster #267
{kind=link}
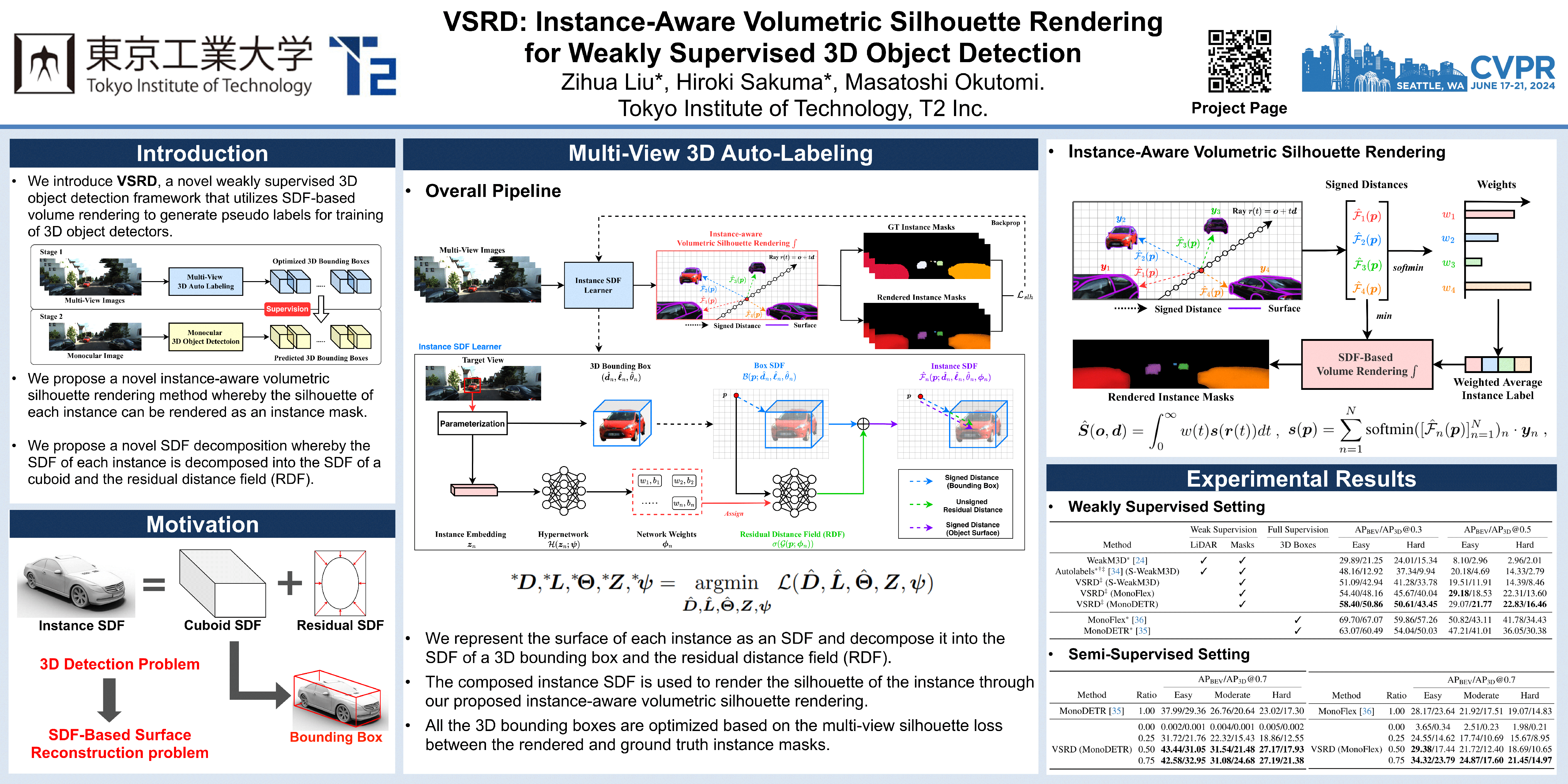
Monocular 3D object detection poses a significant challenge in 3D scene understanding due to its inherently ill-posed nature in monocular depth estimation. Existing methods heavily rely on supervised learning using abundant 3D labels, typically obtained through expensive and labor-intensive annotation on LiDAR point clouds. To tackle this problem, we propose a novel weakly supervised 3D object detection framework named VSRD (Volumetric Silhouette Rendering for Detection) to train 3D object detectors without any 3D supervision but only weak 2D supervision. VSRD consists of multi-view 3D auto-labeling and subsequent training of monocular 3D object detectors using the pseudo labels generated in the auto-labeling stage. In the auto-labeling stage, we represent the surface of each instance as a signed distance field (SDF) and render its silhouette as an instance mask through our proposed instance-aware volumetric silhouette rendering. To directly optimize the 3D bounding boxes through rendering, we decompose the SDF of each instance into the SDF of a cuboid and the residual distance field (RDF) that represents the residual from the cuboid. This mechanism enables us to optimize the 3D bounding boxes in an end-to-end manner by comparing the rendered instance masks with the ground truth instance masks. The optimized 3D bounding boxes serve as effective training data for 3D object detection. We conduct extensive experiments on the KITTI-360 dataset, demonstrating that our method outperforms the existing weakly supervised 3D object detection methods. The code is available at https://github.com/skmhrk1209/VSRD.