{kind=link}
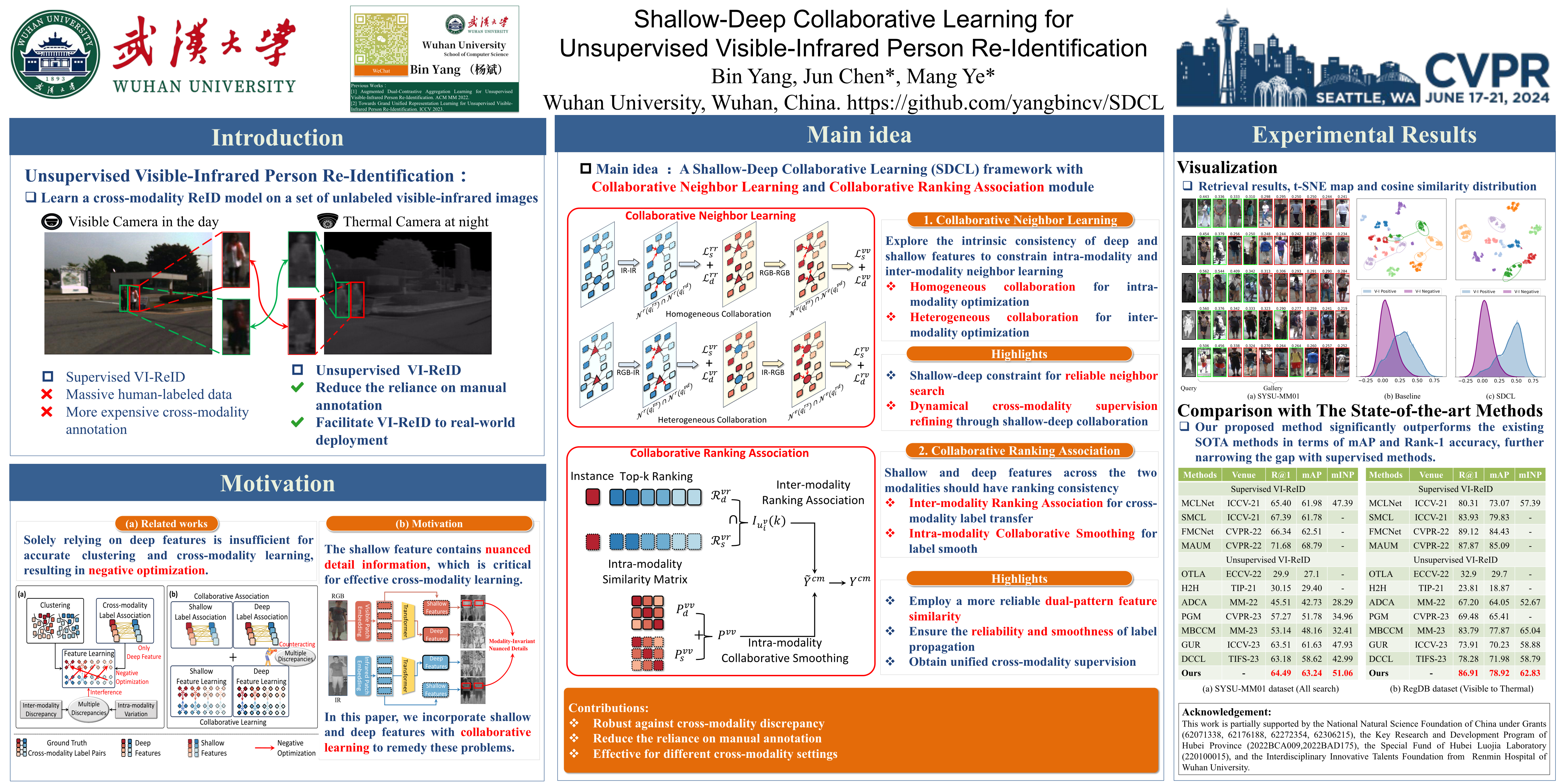
Unsupervised visible-infrared person re-identification (US-VI-ReID) centers on learning a cross-modality retrieval model without labels, reducing the reliance on expensive cross-modality manual annotation. Previous US-VI-ReID works gravitate toward learning cross-modality information with the deep features extracted from the ultimate layer. Nevertheless, interfered by the multiple discrepancies, solely relying on deep features is insufficient for accurately learning modality-invariant features, resulting in negative optimization.The shallow feature from the shallow layers contains nuanced detail information, which is critical for effective cross-modality learning but is disregarded regrettably by the existing methods. To address the above issues, we design a Shallow-Deep Collaborative Learning (SDCL) framework based on the transformer with shallow-deep contrastive learning, incorporating Collaborative Neighbor Learning (CNL) and Collaborative Ranking Association (CRA) module. Specifically, CNL unveils the intrinsic homogeneous and heterogeneous collaboration which are harnessed for neighbor alignment, enhancing the robustness in a dynamic manner. Furthermore, CRA associates the cross-modality labels with the ranking association between shallow and deep features, furnishing valuable supervision for cross-modality learning. Extensive experiments validate the superiority of our method, even outperforming certain supervised counterparts.