{kind=link}
Abstract:
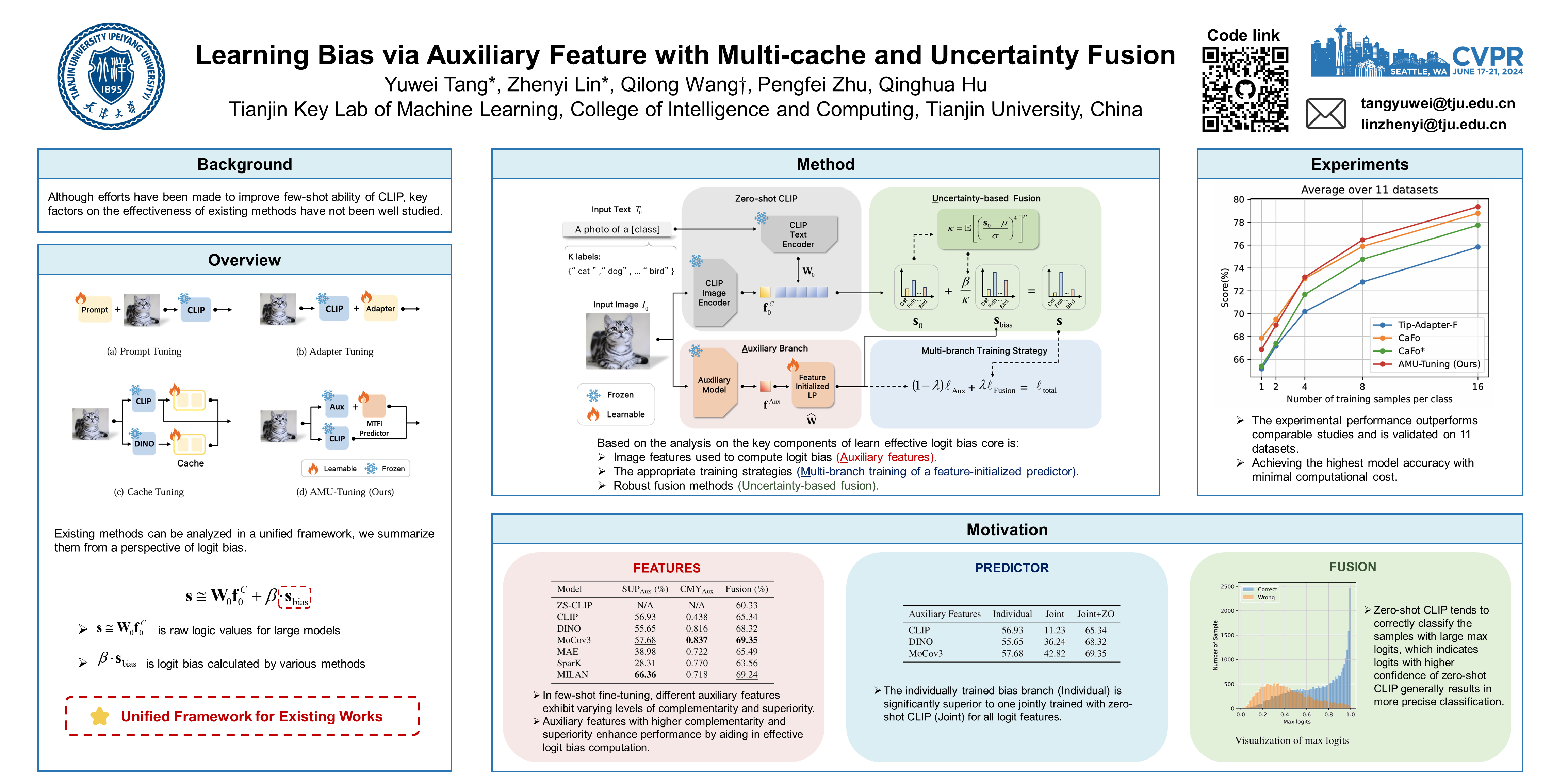
Recently, pre-trained vision-language models (e.g., CLIP) have shown great potential in few-shot learning and attracted a lot of research interest. Although many efforts have been made to improve few-shot generalization ability of CLIP, key factors on the effectiveness of existing methods have not been well studied, limiting further exploration of CLIP's potential in few-shot learning. In this paper, we first introduce a unified formulation to analyze CLIP-based few-shot learning methods from a perspective of logit bias, which encourages us to learn an effective logit bias for further improving performance of CLIP-based few-shot learning methods. To this end, we disassemble three key components involved in computation of logit bias (i.e., logit features, logit predictor, and logit fusion) and empirically analyze the effect on performance of few-shot classification. According to the analysis on the key components, this paper proposes a novel AMU-Tuning method to learn effective logit bias for CLIP-based few-shot classification. Specifically, our AMU-Tuning predicts logit bias by exploiting the appropriate $\underline{\textbf{A}}$uxiliary features, which are fed into an efficient feature-initialized linear classifier with $\underline{\textbf{M}}$ulti-branch training. Finally, an $\underline{\textbf{U}}$ncertainty-based fusion is developed to incorporate logit bias into CLIP for few-shot classification. The experiments are conducted on several widely used benchmarks, and the results show our proposed AMU-Tuning clearly outperforms its counterparts while achieving state-of-the-art performance without bells and whistles.
Chat is not available.