{kind=link}
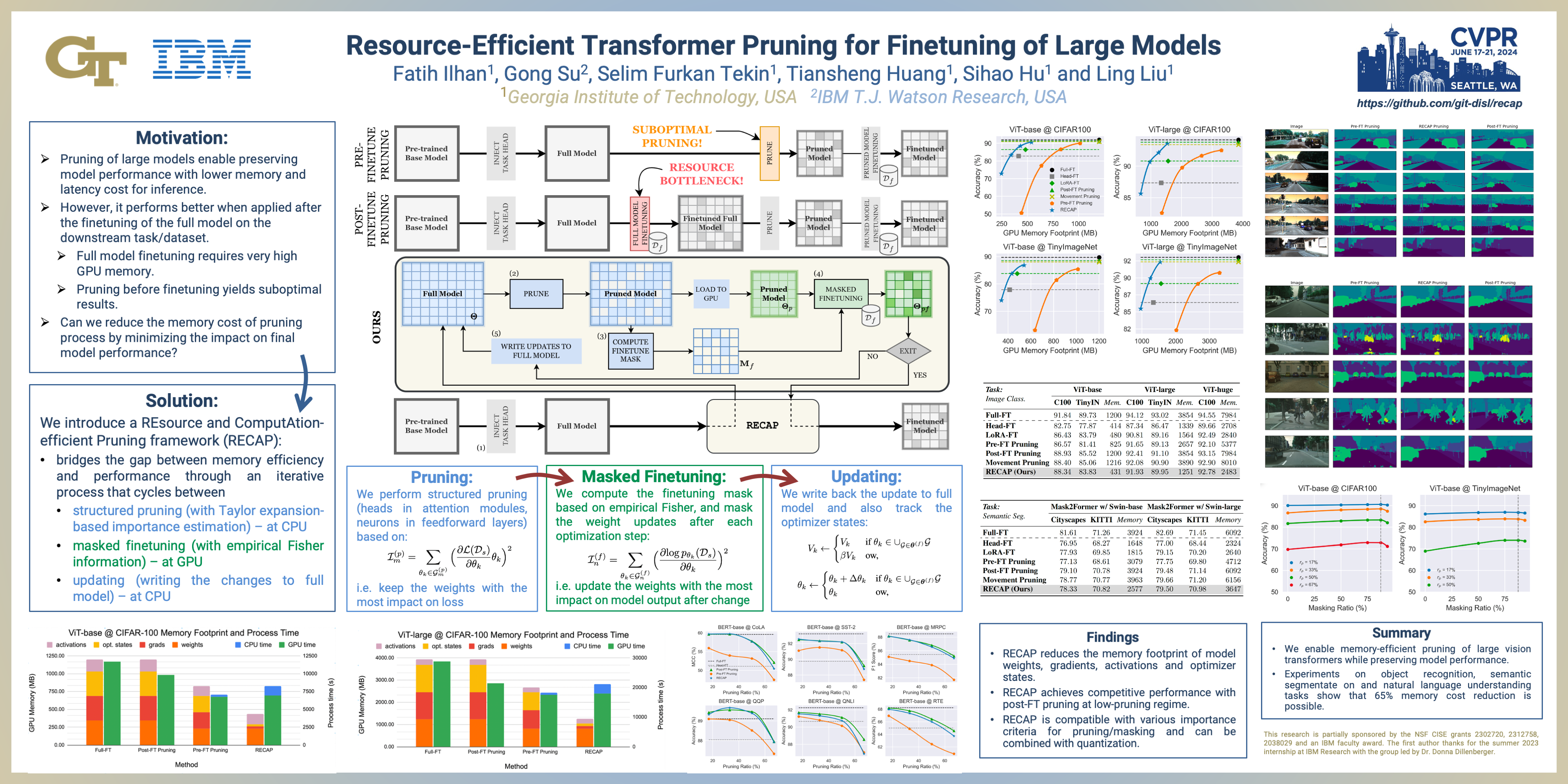
With the recent advances in vision transformers and large language models (LLMs), finetuning costly large models on downstream learning tasks poses significant challenges under limited computational resources. This paper presents a REsource and ComputAtion-efficient Pruning framework (RECAP) for the finetuning of transformer-based large models. RECAP by design bridges the gap between efficiency and performance through an iterative process cycling between pruning, finetuning, and updating stages to explore different chunks of the given large-scale model. At each iteration, we first prune the model with Taylor-approximation-based importance estimation and then only update a subset of the pruned model weights based on the Fisher-information criterion. In this way, RECAP achieves two synergistic and yet conflicting goals: reducing the GPU memory footprint while maintaining model performance, unlike most existing pruning methods that require the model to be finetuned beforehand for better preservation of model performance. We perform extensive experiments with a wide range of large transformer-based architectures on various computer vision and natural language understanding tasks. Compared to recent pruning techniques, we demonstrate that RECAP offers significant improvements in GPU memory efficiency, capable of reducing the footprint by up to 65\%.