{kind=link}
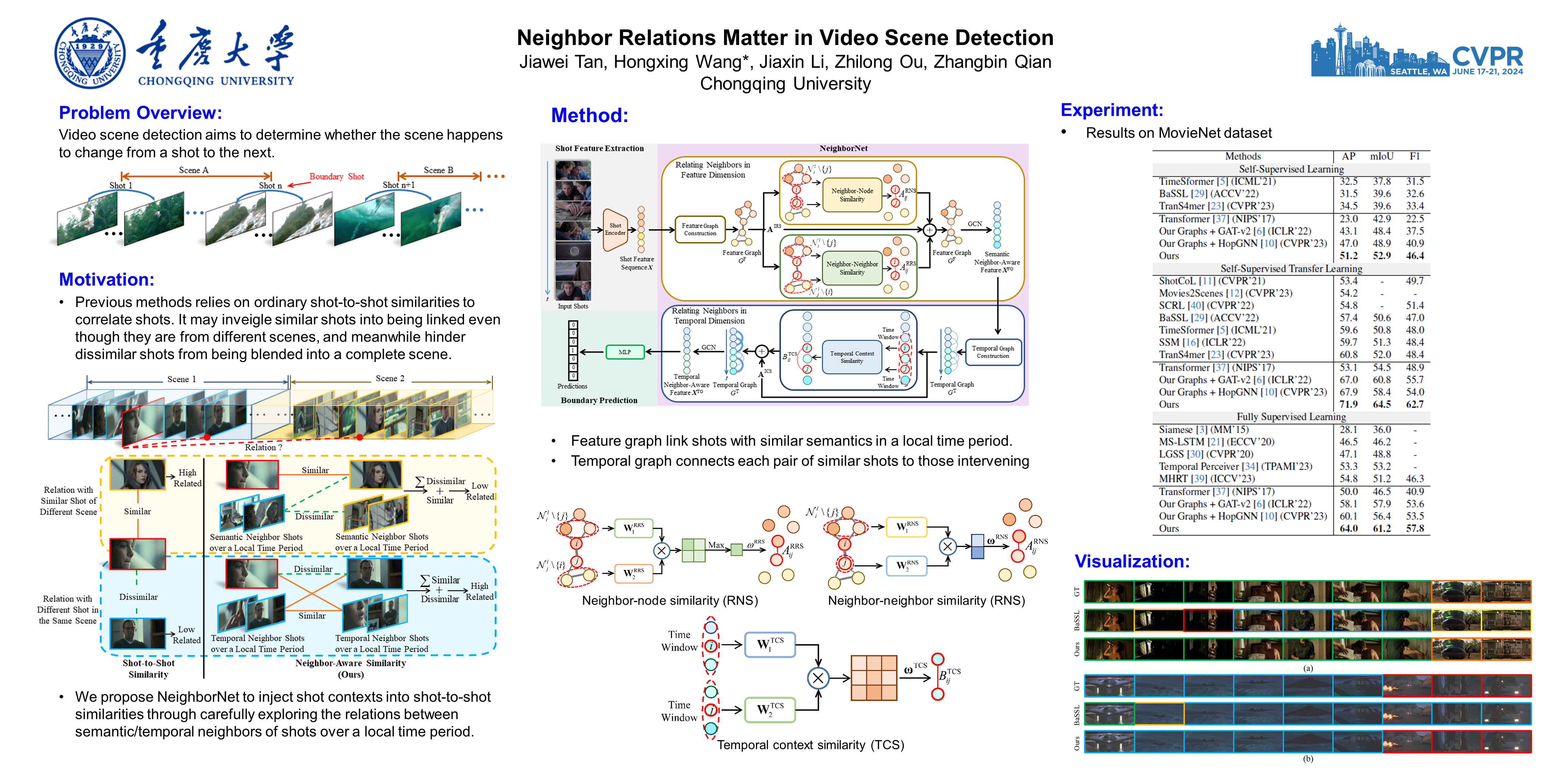
Video scene detection aims to temporally link shots for obtaining semantically compact scenes.It is essential for this task to capture scene-distinguishable affinity among shots by similarity assessment.However, most methods relies on ordinary shot-to-shot similarities, which may inveigle similar shots into being linked even though they are from different scenes, and meanwhile hinder dissimilar shots from being blended into a complete scene.In this paper, we propose NeighborNet to inject shot contexts into shot-to-shot similarities through carefully exploring the relations between semantic/temporal neighbors of shots over a local time period.In this way, shot-to-shot similarities are remeasured as semantic/temporal neighbor-aware similarities so that NeighborNet can learn context embedding into shot features using graph convolutional network.As a result, not only do the learned shot features suppress the affinity among similar shots from different scenes, but they also promote the affinity among dissimilar shots in the same scene.Experimental results on public benchmark datasets show that our proposed NeighborNet yields substantial improvements in video scene detection, especially outperforms released state-of-the-arts by at least 6\% in Average Precision (AP).The code is available at https://github.com/ExMorgan-Alter/NeighborNet.