{kind=link}
Abstract:
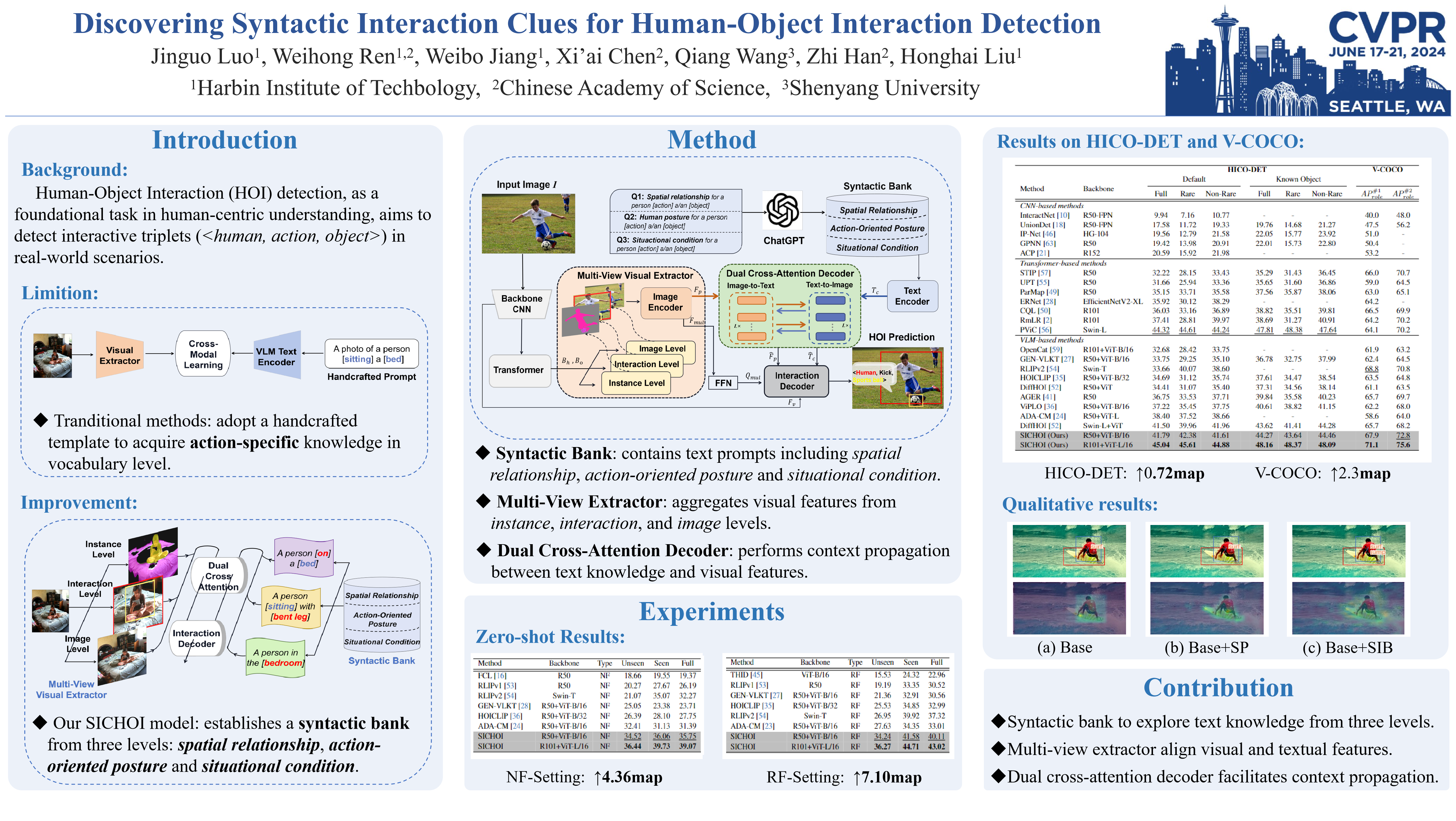
Recently, Vision-Language Model (VLM) has greatly advanced the Human-Object Interaction (HOI) detection. The existing VLM-based HOI detectors typically adopt a hand-crafted template (e.g., a photo of a person [action] a$/$an [object]) to acquire text knowledge through the VLM text encoder. However, such approaches, only encoding the action-specific text prompts in vocabulary level, may suffer from learning ambiguity without exploring the fine-grained clues from the perspective of interaction context. In this paper, we propose a novel method to discover Syntactic Interaction Clues for HOI detection (SICHOI) by using VLM. Specifically, we first investigate what are the essential elements for an interaction context, and then establish a syntactic interaction bank from three levels: spatial relationship, action-oriented posture and situational condition. Further, to align visual features with the syntactic interaction bank, we adopt a multi-view extractor to jointly aggregate visual features from instance, interaction, and image levels accordingly. In addition, we also introduce a dual cross-attention decoder to perform context propagation between text knowledge and visual features, thereby enhancing the HOI detection. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on HICO-DET and V-COCO.
Chat is not available.