Poster
Learning SO(3)-Invariant Semantic Correspondence via Local Shape Transform
Chunghyun Park · Seungwook Kim · Jaesik Park · Minsu Cho
Arch 4A-E Poster #335
{kind=link}
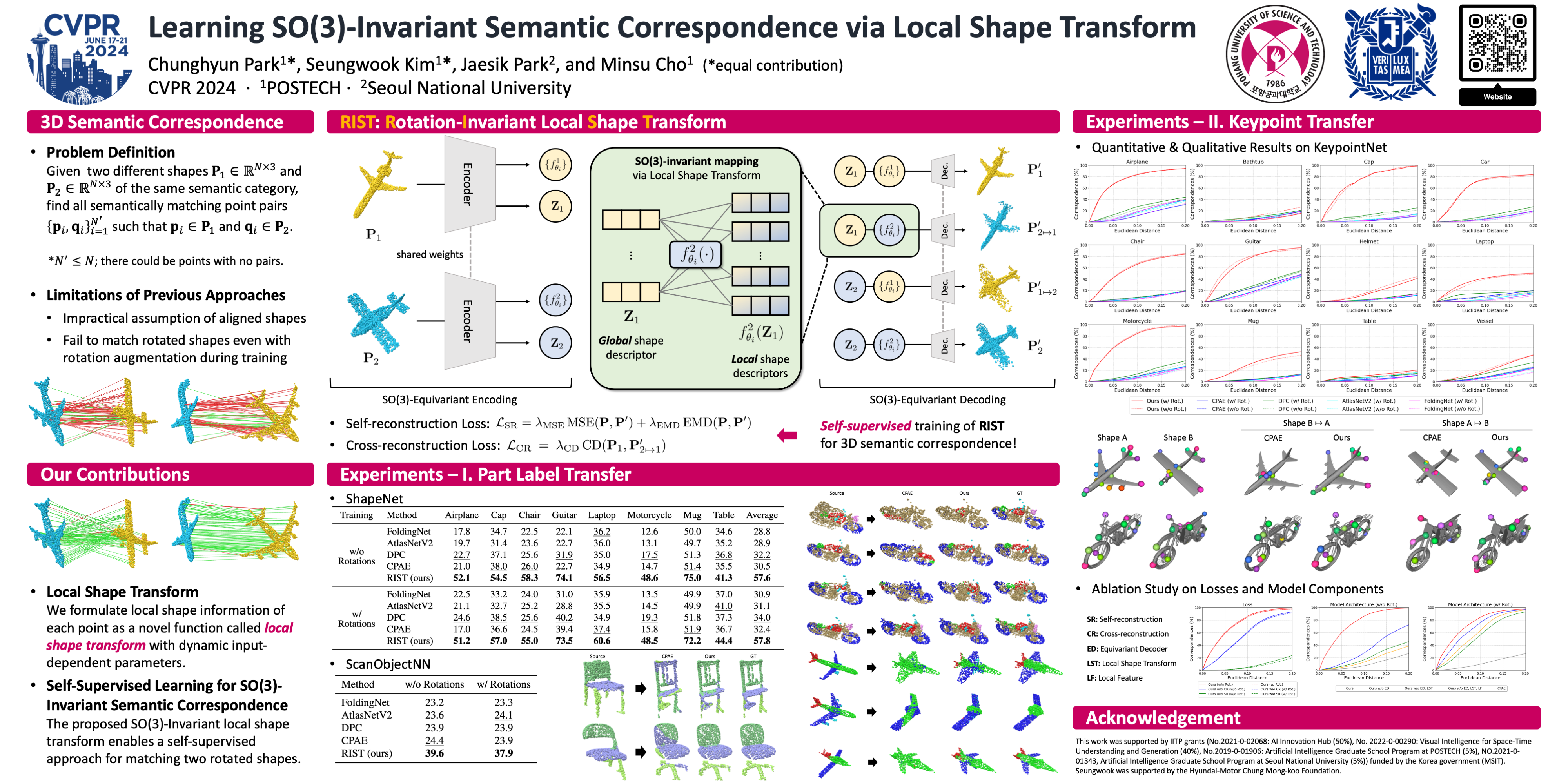
Establishing accurate 3D correspondences between shapes stands as a pivotal challenge with profound implications for computer vision and robotics. However, existing self-supervised methods for this problem assume perfect input shape alignment, restricting their real-world applicability. In this work, we introduce a novel self-supervised Rotation-Invariant 3D correspondence learner with Local Shape Transform, dubbed RIST, that learns to establish dense correspondences between shapes even under challenging intra-class variations and arbitrary orientations. Specifically, RIST learns to dynamically formulate an SO(3)-invariant local shape transform for each point, which maps the SO(3)-equivariant global shape descriptor of the input shape to a local shape descriptor. These local shape descriptors are provided as inputs to our decoder to facilitate point cloud self- and cross-reconstruction. Our proposed self-supervised training pipeline encourages semantically corresponding points from different shapes to be mapped to similar local shape descriptors, enabling RIST to establish dense point-wise correspondences. RIST demonstrates state-of-the-art performances on 3D part label transfer and semantic keypoint transfer given arbitrarily rotated point cloud pairs, outperforming existing methods by significant margins.