{kind=link}
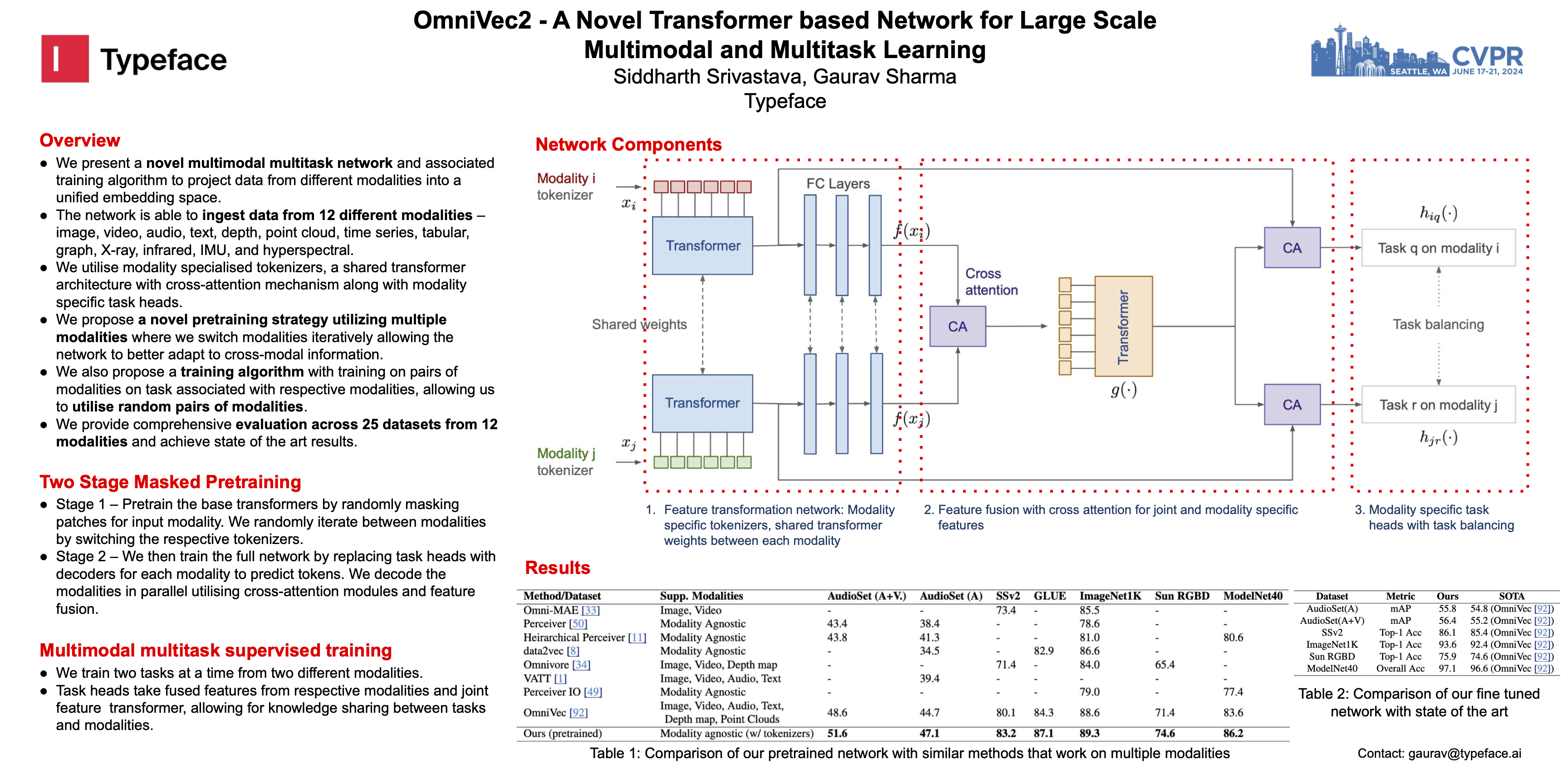
We present a novel multimodal multitask network and associated training algorithm.The method is capable of ingesting data from approximately 12 different modalitiesnamely image, video, audio, text, depth, point cloud, time series, tabular, graph, X-ray, infrared, IMU, and hyperspectral.The proposed approach utilizes modality specialized tokenizers, a shared transformer architecture, and cross-attention mechanisms to project the data from different modalities into a unified embedding space. It addresses multimodal and multitask scenarios by incorporating modality-specific task heads for different tasks in respective modalities. We propose a novel pretraining strategy with iterative modality switching to initialize the network, and a training algorithm which trades off fully joint training over all modalities, with training on pairs of modalities at a time. We provide comprehensive evaluation across 25 datasets from 12 modalities and show state of the art performances, demonstrating the effectiveness of the proposed architecture, pretraining strategy and adapted multitask training.