Poster
GroupContrast: Semantic-aware Self-supervised Representation Learning for 3D Understanding
Chengyao Wang · Li Jiang · Xiaoyang Wu · Zhuotao Tian · Bohao Peng · Hengshuang Zhao · Jiaya Jia
Arch 4A-E Poster #8
{kind=link}
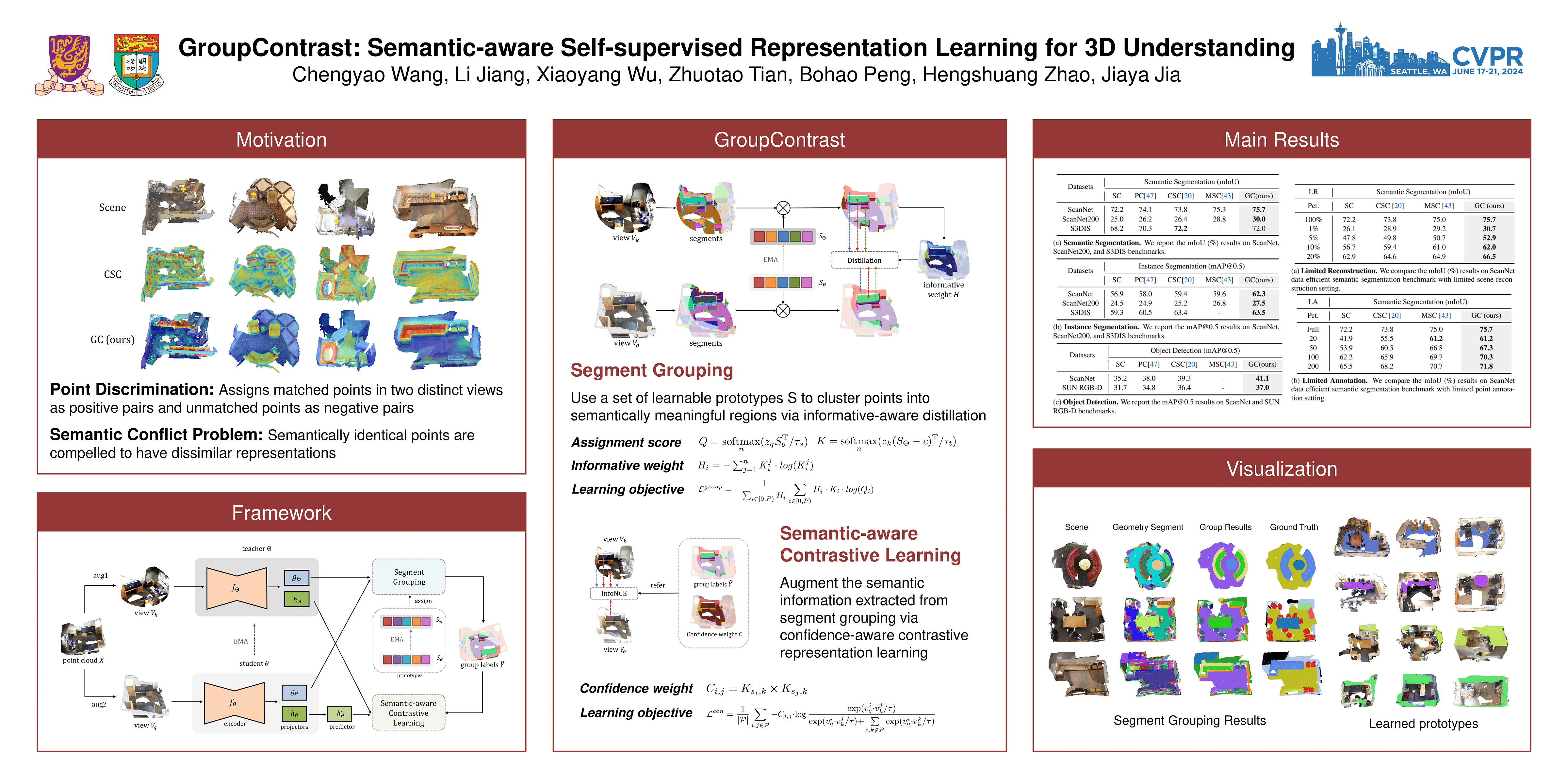
Self-supervised 3D representation learning aims to learn effective representations from large-scale unlabeled point clouds.Most existing approaches adopt point discrimination as the pretext task, which assigns matched points in two distinct views as positive pairs and unmatched points as negative pairs. However, this approach often results in semantically identical points having dissimilar representations, leading to a high number of false negatives and introducing a semantic conflict problem. To address this issue, we propose GroupContrast, a novel approach that combines segment grouping and semantic-aware contrastive learning. Segment grouping partitions points into semantically meaningful regions, which enhances semantic coherence and provides semantic guidance for the subsequent contrastive representation learning. Semantic-aware contrastive learning augments the semantic information extracted from segment grouping and helps to alleviate the issue of semantic conflict. We conducted extensive experiments on multiple 3D scene understanding tasks. The results demonstrate that GroupContrast learns semantically meaningful representations and achieves promising transfer learning performance.