{kind=link}
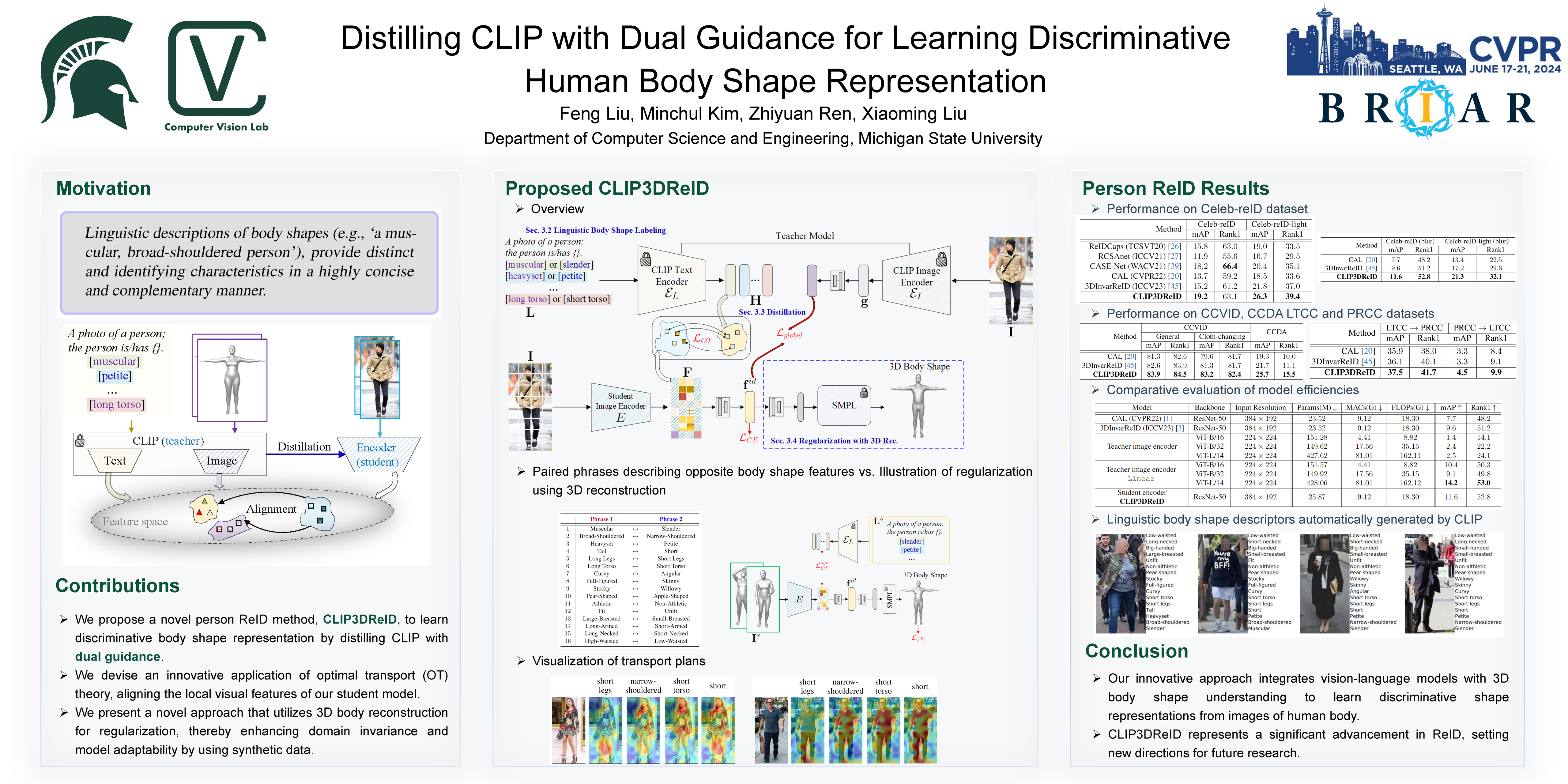
Person Re-Identification (ReID) holds critical importance in computer vision with pivotal applications in public safety and crime prevention. Traditional ReID methods, reliant on appearance attributes such as clothing and color, encounter limitations in long-term scenarios and dynamic environments. To address these challenges, we propose CLIP3DReID, an innovative approach that enhances person ReID by integrating linguistic descriptions with visual perception, leveraging pretrained CLIP model for knowledge distillation. Our method first employs CLIP to automatically label body shapes with linguistic descriptors. We then apply optimal transport theory to align the student model's local visual features with shape-aware tokens derived from CLIP's linguistic output. Additionally, we align the student model's global visual features with those from the CLIP image encoder and the 3D SMPL identity space, fostering enhanced domain robustness. CLIP3DReID notably excels in discerning discriminative body shape features, achieving state-of-the-art results in person ReID. Our approach represents a significant advancement in ReID, offering robust solutions to existing challenges and setting new directions for future research. The code and models will be released upon publication.