Poster
Galactic: Scaling End-to-End Reinforcement Learning for Rearrangement at 100k Steps-per-Second
Vincent-Pierre Berges · Andrew Szot · Devendra Singh Chaplot · Aaron Gokaslan · Roozbeh Mottaghi · Dhruv Batra · Eric Undersander
West Building Exhibit Halls ABC 135
{kind=link}
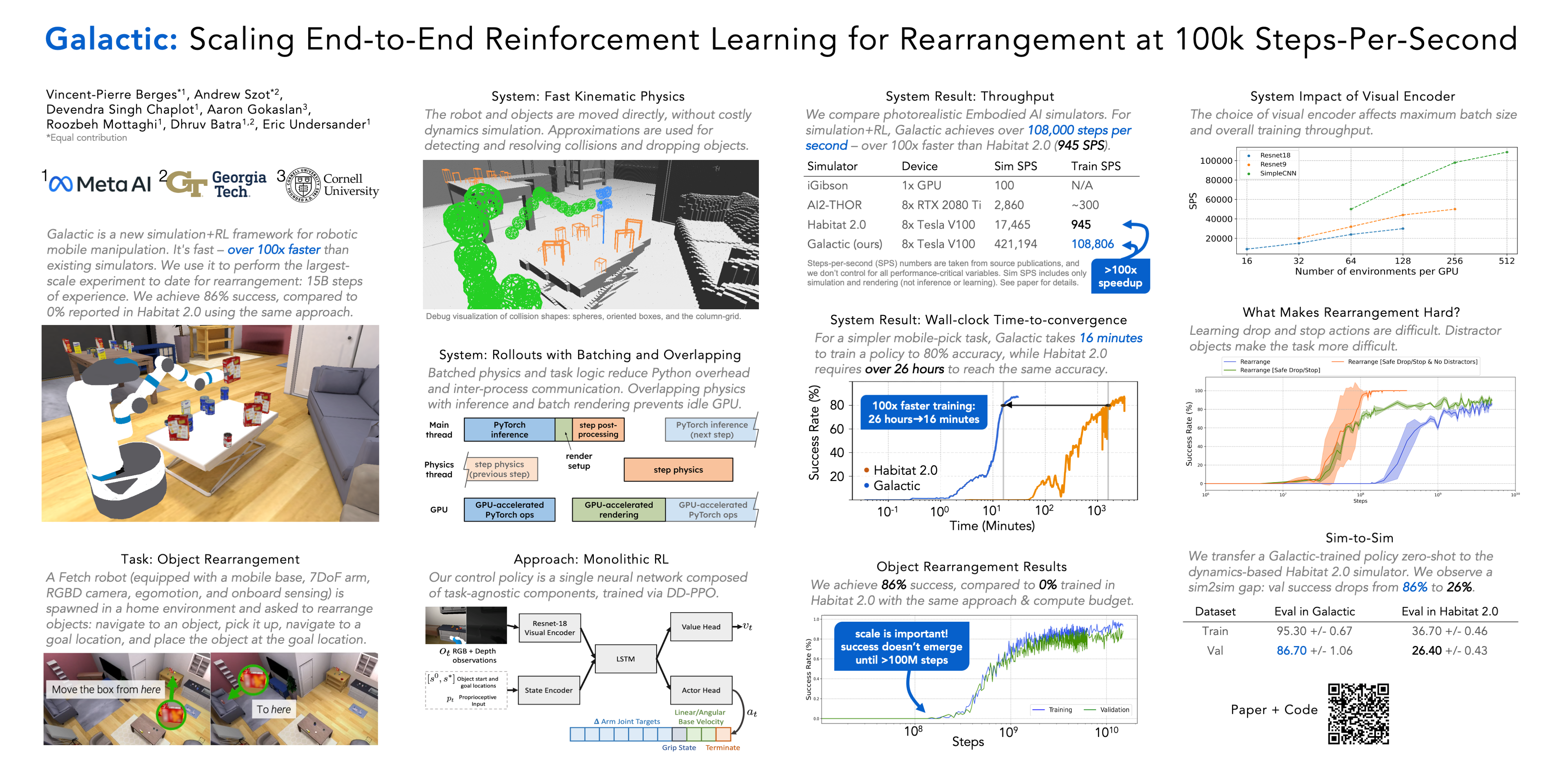
We present Galactic, a large-scale simulation and reinforcement-learning (RL) framework for robotic mobile manipulation in indoor environments. Specifically, a Fetch robot (equipped with a mobile base, 7DoF arm, RGBD camera, egomotion, and onboard sensing) is spawned in a home environment and asked to rearrange objects -- by navigating to an object, picking it up, navigating to a target location, and then placing the object at the target location. Galactic is fast. In terms of simulation speed (rendering + physics), Galactic achieves over 421,000 steps-per-second (SPS) on an 8-GPU node, which is 54x faster than Habitat 2.0 (7699 SPS). More importantly, Galactic was designed to optimize the entire rendering+physics+RL interplay since any bottleneck in the interplay slows down training. In terms of simulation+RL speed (rendering + physics + inference + learning), Galactic achieves over 108,000 SPS, which 88x faster than Habitat 2.0 (1243 SPS). These massive speed-ups not only drastically cut the wall-clock training time of existing experiments, but also unlock an unprecedented scale of new experiments. First, Galactic can train a mobile pick skill to >80% accuracy in under 16 minutes, a 100x speedup compared to the over 24 hours it takes to train the same skill in Habitat 2.0. Second, we use Galactic to perform the largest-scale experiment to date for rearrangement using 5B steps of experience in 46 hours, which is equivalent to 20 years of robot experience. This scaling results in a single neural network composed of task-agnostic components achieving 85% success in GeometricGoal rearrangement, compared to 0% success reported in Habitat 2.0 for the same approach. The code is available at github.com/facebookresearch/galactic.