|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
We present VISPROG, a neuro-symbolic approach to solving complex and compositional visual tasks given natural language instructions. VISPROG avoids the need for any task-specific training. Instead, it uses the in-context learning ability of large language models to generate python-like modular programs, which are then executed to get both the solution and a comprehensive and interpretable rationale. Each line of the generated program may invoke one of several off-the-shelf computer vision models, image processing routines, or python functions to produce intermediate outputs that may be consumed by subsequent parts of the program. We demonstrate the flexibility of VISPROG on 4 diverse tasks - compositional visual question answering, zero-shot reasoning on image pairs, factual knowledge object tagging, and language-guided image editing. We believe neuro-symbolic approaches like VISPROG are an exciting avenue to easily and effectively expand the scope of AI systems to serve the long tail of complex tasks that people may wish to perform. |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 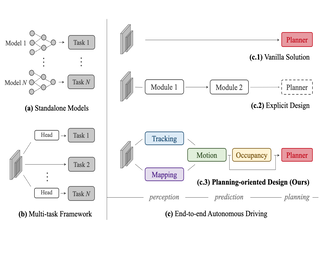
Modern autonomous driving system is characterized as modular tasks in sequential order, i.e., perception, prediction, and planning. In order to perform a wide diversity of tasks and achieve advanced-level intelligence, contemporary approaches either deploy standalone models for individual tasks, or design a multi-task paradigm with separate heads. However, they might suffer from accumulative errors or deficient task coordination. Instead, we argue that a favorable framework should be devised and optimized in pursuit of the ultimate goal, i.e., planning of the self-driving car. Oriented at this, we revisit the key components within perception and prediction, and prioritize the tasks such that all these tasks contribute to planning. We introduce Unified Autonomous Driving (UniAD), a comprehensive framework up-to-date that incorporates full-stack driving tasks in one network. It is exquisitely devised to leverage advantages of each module, and provide complementary feature abstractions for agent interaction from a global perspective. Tasks are communicated with unified query interfaces to facilitate each other toward planning. We instantiate UniAD on the challenging nuScenes benchmark. With extensive ablations, the effectiveness of using such a philosophy is proven by substantially outperforming previous state-of-the-arts in all aspects. Code and models are public. |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
Classifier-free guided diffusion models have recently been shown to be highly effective at high-resolution image generation, and they have been widely used in large-scale diffusion frameworks including DALL·E 2, Stable Diffusion and Imagen. However, a downside of classifier-free guided diffusion models is that they are computationally expensive at inference time since they require evaluating two diffusion models, a class-conditional model and an unconditional model, tens to hundreds of times. To deal with this limitation, we propose an approach to distilling classifier-free guided diffusion models into models that are fast to sample from: Given a pre-trained classifier-free guided model, we first learn a single model to match the output of the combined conditional and unconditional models, and then we progressively distill that model to a diffusion model that requires much fewer sampling steps. For standard diffusion models trained on the pixel-space, our approach is able to generate images visually comparable to that of the original model using as few as 4 sampling steps on ImageNet 64x64 and CIFAR-10, achieving FID/IS scores comparable to that of the original model while being up to 256 times faster to sample from. For diffusion models trained on the latent-space (e.g., Stable Diffusion), our approach is … |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
Neural Radiance Fields (NeRFs) have demonstrated amazing ability to synthesize images of 3D scenes from novel views. However, they rely upon specialized volumetric rendering algorithms based on ray marching that are mismatched to the capabilities of widely deployed graphics hardware. This paper introduces a new NeRF representation based on textured polygons that can synthesize novel images efficiently with standard rendering pipelines. The NeRF is represented as a set of polygons with textures representing binary opacities and feature vectors. Traditional rendering of the polygons with a z-buffer yields an image with features at every pixel, which are interpreted by a small, view-dependent MLP running in a fragment shader to produce a final pixel color. This approach enables NeRFs to be rendered with the traditional polygon rasterization pipeline, which provides massive pixel-level parallelism, achieving interactive frame rates on a wide range of compute platforms, including mobile phones. |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
Estimating 3D human motion from an egocentric video sequence plays a critical role in human behavior understanding and has various applications in VR/AR. However, naively learning a mapping between egocentric videos and human motions is challenging, because the user’s body is often unobserved by the front-facing camera placed on the head of the user. In addition, collecting large-scale, high-quality datasets with paired egocentric videos and 3D human motions requires accurate motion capture devices, which often limit the variety of scenes in the videos to lab-like environments. To eliminate the need for paired egocentric video and human motions, we propose a new method, Ego-Body Pose Estimation via Ego-Head Pose Estimation (EgoEgo), which decomposes the problem into two stages, connected by the head motion as an intermediate representation. EgoEgo first integrates SLAM and a learning approach to estimate accurate head motion. Subsequently, leveraging the estimated head pose as input, EgoEgo utilizes conditional diffusion to generate multiple plausible full-body motions. This disentanglement of head and body pose eliminates the need for training datasets with paired egocentric videos and 3D human motion, enabling us to leverage large-scale egocentric video datasets and motion capture datasets separately. Moreover, for systematic benchmarking, we develop a synthetic dataset, … |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
Large text-to-image models achieved a remarkable leap in the evolution of AI, enabling high-quality and diverse synthesis of images from a given text prompt. However, these models lack the ability to mimic the appearance of subjects in a given reference set and synthesize novel renditions of them in different contexts. In this work, we present a new approach for “personalization” of text-to-image diffusion models. Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can be used to synthesize novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views and lighting conditions that do not appear in the reference images. We apply our technique to several previously-unassailable tasks, including subject recontextualization, text-guided view synthesis, and artistic rendering, all while preserving the subject’s key features. We also provide a new dataset and evaluation protocol for this new task of … |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
As a fundamental problem in computer vision, 3D point cloud registration (PCR) aims to seek the optimal pose to align a point cloud pair. In this paper, we present a 3D registration method with maximal cliques (MAC). The key insight is to loosen the previous maximum clique constraint, and to mine more local consensus information in a graph for accurate pose hypotheses generation: 1) A compatibility graph is constructed to render the affinity relationship between initial correspondences. 2) We search for maximal cliques in the graph, each of which represents a consensus set. We perform node-guided clique selection then, where each node corresponds to the maximal clique with the greatest graph weight. 3) Transformation hypotheses are computed for the selected cliques by SVD algorithm and the best hypothesis is used to perform registration. Extensive experiments on U3M, 3DMatch, 3DLoMatch and KITTI demonstrate that MAC effectively increases registration accuracy, outperforms various state-of-the-art methods and boosts the performance of deep-learned methods. MAC combined with deep-learned methods achieves state-of-the-art registration recall of 95.7% / 78.9% on the 3DMatch / 3DLoMatch. |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 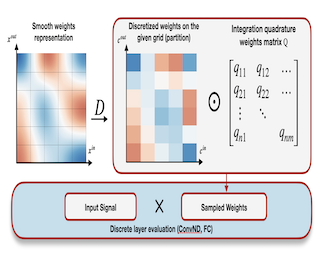
We introduce a new family of deep neural networks. Instead of the conventional representation of network layers as N-dimensional weight tensors, we use continuous layer representation along the filter and channel dimensions. We call such networks Integral Neural Networks (INNs). In particular, the weights of INNs are represented as continuous functions defined on N-dimensional hypercubes, and the discrete transformations of inputs to the layers are replaced by continuous integration operations, accordingly. During the inference stage, our continuous layers can be converted into the traditional tensor representation via numerical integral quadratures. Such kind of representation allows the discretization of a network to an arbitrary size with various discretization intervals for the integral kernels. This approach can be applied to prune the model directly on the edge device while featuring only a small performance loss at high rates of structural pruning without any fine-tuning. To evaluate the practical benefits of our proposed approach, we have conducted experiments using various neural network architectures for multiple tasks. Our reported results show that the proposed INNs achieve the same performance with their conventional discrete counterparts, while being able to preserve approximately the same performance (2 % accuracy loss for ResNet18 on Imagenet) at a high … |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 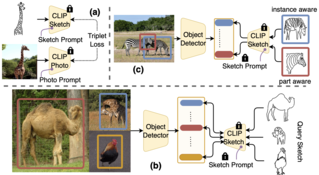
Sketches are highly expressive, inherently capturing subjective and fine-grained visual cues. The exploration of such innate properties of human sketches has, however, been limited to that of image retrieval. In this paper, for the first time, we cultivate the expressiveness of sketches but for the fundamental vision task of object detection. The end result is a sketch-enabled object detection framework that detects based on what you sketch -- that “zebra” (e.g., one that is eating the grass) in a herd of zebras (instance-aware detection), and only the part (e.g., “head” of a “zebra”) that you desire (part-aware detection). We further dictate that our model works without (i) knowing which category to expect at testing (zero-shot) and (ii) not requiring additional bounding boxes (as per fully supervised) and class labels (as per weakly supervised). Instead of devising a model from the ground up, we show an intuitive synergy between foundation models (e.g., CLIP) and existing sketch models build for sketch-based image retrieval (SBIR), which can already elegantly solve the task -- CLIP to provide model generalisation, and SBIR to bridge the (sketch->photo) gap. In particular, we first perform independent prompting on both sketch and photo branches of an SBIR model … |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in a grayscale frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. By directly transferring zero-shot from synthetic to real data, our data-driven tracker outperforms existing approaches in relative feature age by up to 120% while also achieving the lowest latency. This performance gap is further increased to 130% by adapting our tracker to real data with a novel self-supervision strategy. |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
We address the problem of synthesizing novel views from a monocular video depicting a complex dynamic scene. State-of-the-art methods based on temporally varying Neural Radiance Fields (aka dynamic NeRFs) have shown impressive results on this task. However, for long videos with complex object motions and uncontrolled camera trajectories,these methods can produce blurry or inaccurate renderings, hampering their use in real-world applications. Instead of encoding the entire dynamic scene within the weights of MLPs, we present a new approach that addresses these limitations by adopting a volumetric image-based rendering framework that synthesizes new viewpoints by aggregating features from nearby views in a scene motion-aware manner.Our system retains the advantages of prior methods in its ability to model complex scenes and view-dependent effects,but also enables synthesizing photo-realistic novel views from long videos featuring complex scene dynamics with unconstrained camera trajectories. We demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets, and also apply our approach to in-the-wild videos with challenging camera and object motion, where prior methods fail to produce high-quality renderings |
|
Award Candidate
|
Poster
[ West Building Exhibit Halls ABC ] 
Recent advances in modeling 3D objects mostly rely on synthetic datasets due to the lack of large-scale real-scanned 3D databases. To facilitate the development of 3D perception, reconstruction, and generation in the real world, we propose OmniObject3D, a large vocabulary 3D object dataset with massive high-quality real-scanned 3D objects. OmniObject3D has several appealing properties: 1) Large Vocabulary: It comprises 6,000 scanned objects in 190 daily categories, sharing common classes with popular 2D datasets (e.g., ImageNet and LVIS), benefiting the pursuit of generalizable 3D representations. 2) Rich Annotations: Each 3D object is captured with both 2D and 3D sensors, providing textured meshes, point clouds, multiview rendered images, and multiple real-captured videos. 3) Realistic Scans: The professional scanners support high-quality object scans with precise shapes and realistic appearances. With the vast exploration space offered by OmniObject3D, we carefully set up four evaluation tracks: a) robust 3D perception, b) novel-view synthesis, c) neural surface reconstruction, and d) 3D object generation. Extensive studies are performed on these four benchmarks, revealing new observations, challenges, and opportunities for future research in realistic 3D vision. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Current attention algorithms (e.g., self-attention) are stimulus-driven and highlight all the salient objects in an image. However, intelligent agents like humans often guide their attention based on the high-level task at hand, focusing only on task-related objects. This ability of task-guided top-down attention provides task-adaptive representation and helps the model generalize to various tasks. In this paper, we consider top-down attention from a classic Analysis-by-Synthesis (AbS) perspective of vision. Prior work indicates a functional equivalence between visual attention and sparse reconstruction; we show that an AbS visual system that optimizes a similar sparse reconstruction objective modulated by a goal-directed top-down signal naturally simulates top-down attention. We further propose Analysis-by-Synthesis Vision Transformer (AbSViT), which is a top-down modulated ViT model that variationally approximates AbS, and achieves controllable top-down attention. For real-world applications, AbSViT consistently improves over baselines on Vision-Language tasks such as VQA and zero-shot retrieval where language guides the top-down attention. AbSViT can also serve as a general backbone, improving performance on classification, semantic segmentation, and model robustness. Project page: https://sites.google.com/view/absvit. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Face recognition is a prevailing authentication solution in numerous biometric applications. Physical adversarial attacks, as an important surrogate, can identify the weaknesses of face recognition systems and evaluate their robustness before deployed. However, most existing physical attacks are either detectable readily or ineffective against commercial recognition systems. The goal of this work is to develop a more reliable technique that can carry out an end-to-end evaluation of adversarial robustness for commercial systems. It requires that this technique can simultaneously deceive black-box recognition models and evade defensive mechanisms. To fulfill this, we design adversarial textured 3D meshes (AT3D) with an elaborate topology on a human face, which can be 3D-printed and pasted on the attacker’s face to evade the defenses. However, the mesh-based optimization regime calculates gradients in high-dimensional mesh space, and can be trapped into local optima with unsatisfactory transferability. To deviate from the mesh-based space, we propose to perturb the low-dimensional coefficient space based on 3D Morphable Model, which significantly improves black-box transferability meanwhile enjoying faster search efficiency and better visual quality. Extensive experiments in digital and physical scenarios show that our method effectively explores the security vulnerabilities of multiple popular commercial services, including three recognition APIs, four anti-spoofing … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Geometric model fitting is a challenging but fundamental computer vision problem. Recently, quantum optimization has been shown to enhance robust fitting for the case of a single model, while leaving the question of multi-model fitting open. In response to this challenge, this paper shows that the latter case can significantly benefit from quantum hardware and proposes the first quantum approach to multi-model fitting (MMF). We formulate MMF as a problem that can be efficiently sampled by modern adiabatic quantum computers without the relaxation of the objective function. We also propose an iterative and decomposed version of our method, which supports real-world-sized problems. The experimental evaluation demonstrates promising results on a variety of datasets. The source code is available at https://github.com/FarinaMatteo/qmmf. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We propose Text2Scene, a method to automatically create realistic textures for virtual scenes composed of multiple objects. Guided by a reference image and text descriptions, our pipeline adds detailed texture on labeled 3D geometries in the room such that the generated colors respect the hierarchical structure or semantic parts that are often composed of similar materials. Instead of applying flat stylization on the entire scene at a single step, we obtain weak semantic cues from geometric segmentation, which are further clarified by assigning initial colors to segmented parts. Then we add texture details for individual objects such that their projections on image space exhibit feature embedding aligned with the embedding of the input. The decomposition makes the entire pipeline tractable to a moderate amount of computation resources and memory. As our framework utilizes the existing resources of image and text embedding, it does not require dedicated datasets with high-quality textures designed by skillful artists. To the best of our knowledge, it is the first practical and scalable approach that can create detailed and realistic textures of the desired style that maintain structural context for scenes with multiple objects. |
|
Highlight
|
SplineCam: Exact Visualization and Characterization of Deep Network Geometry and Decision Boundaries
Poster
[ West Building Exhibit Halls ABC ] 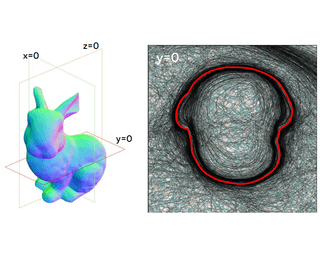
Current Deep Network (DN) visualization and interpretability methods rely heavily on data space visualizations such as scoring which dimensions of the data are responsible for their associated prediction or generating new data features or samples that best match a given DN unit or representation. In this paper, we go one step further by developing the first provably exact method for computing the geometry of a DN’s mapping -- including its decision boundary -- over a specified region of the data space. By leveraging the theory of Continuous Piecewise Linear (CPWL) spline DNs, SplineCam exactly computes a DN’s geometry without resorting to approximations such as sampling or architecture simplification. SplineCam applies to any DN architecture based on CPWL activation nonlinearities, including (leaky) ReLU, absolute value, maxout, and max-pooling and can also be applied to regression DNs such as implicit neural representations. Beyond decision boundary visualization and characterization, SplineCam enables one to compare architectures, measure generalizability, and sample from the decision boundary on or off the data manifold. Project website: https://bit.ly/splinecam |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recent conditional image generation methods produce images of remarkable diversity, fidelity and realism. However, the majority of these methods allow conditioning only on labels or text prompts, which limits their level of control over the generation result. In this paper, we introduce MaskSketch, an image generation method that allows spatial conditioning of the generation result using a guiding sketch as an extra conditioning signal during sampling. MaskSketch utilizes a pre-trained masked generative transformer, requiring no model training or paired supervision, and works with input sketches of different levels of abstraction. We show that intermediate self-attention maps of a masked generative transformer encode important structural information of the input image, such as scene layout and object shape, and we propose a novel sampling method based on this observation to enable structure-guided generation. Our results show that MaskSketch achieves high image realism and fidelity to the guiding structure. Evaluated on standard benchmark datasets, MaskSketch outperforms state-of-the-art methods for sketch-to-image translation, as well as unpaired image-to-image translation approaches. The code can be found on our project website: https://masksketch.github.io/ |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 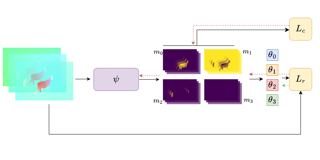
Motion segmentation is one of the main tasks in computer vision and is relevant for many applications. The optical flow (OF) is the input generally used to segment every frame of a video sequence into regions of coherent motion. Temporal consistency is a key feature of motion segmentation, but it is often neglected. In this paper, we propose an original unsupervised spatio-temporal framework for motion segmentation from optical flow that fully investigates the temporal dimension of the problem. More specifically, we have defined a 3D network for multiple motion segmentation that takes as input a sub-volume of successive optical flows and delivers accordingly a sub-volume of coherent segmentation maps. Our network is trained in a fully unsupervised way, and the loss function combines a flow reconstruction term involving spatio-temporal parametric motion models, and a regularization term enforcing temporal consistency on the masks. We have specified an easy temporal linkage of the predicted segments. Besides, we have proposed a flexible and efficient way of coding U-nets. We report experiments on several VOS benchmarks with convincing quantitative results, while not using appearance and not training with any ground-truth data. We also highlight through visual results the distinctive contribution of the short- and … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The matching of 3D shapes has been extensively studied for shapes represented as surface meshes, as well as for shapes represented as point clouds. While point clouds are a common representation of raw real-world 3D data (e.g. from laser scanners), meshes encode rich and expressive topological information, but their creation typically requires some form of (often manual) curation. In turn, methods that purely rely on point clouds are unable to meet the matching quality of mesh-based methods that utilise the additional topological structure. In this work we close this gap by introducing a self-supervised multimodal learning strategy that combines mesh-based functional map regularisation with a contrastive loss that couples mesh and point cloud data. Our shape matching approach allows to obtain intramodal correspondences for triangle meshes, complete point clouds, and partially observed point clouds, as well as correspondences across these data modalities. We demonstrate that our method achieves state-of-the-art results on several challenging benchmark datasets even in comparison to recent supervised methods, and that our method reaches previously unseen cross-dataset generalisation ability. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Existing face forgery detection models try to discriminate fake images by detecting only spatial artifacts (e.g., generative artifacts, blending) or mainly temporal artifacts (e.g., flickering, discontinuity). They may experience significant performance degradation when facing out-domain artifacts. In this paper, we propose to capture both spatial and temporal artifacts in one model for face forgery detection. A simple idea is to leverage a spatiotemporal model (3D ConvNet). However, we find that it may easily rely on one type of artifact and ignore the other. To address this issue, we present a novel training strategy called AltFreezing for more general face forgery detection. The AltFreezing aims to encourage the model to detect both spatial and temporal artifacts. It divides the weights of a spatiotemporal network into two groups: spatial- and temporal-related. Then the two groups of weights are alternately frozen during the training process so that the model can learn spatial and temporal features to distinguish real or fake videos. Furthermore, we introduce various video-level data augmentation methods to improve the generalization capability of the forgery detection model. Extensive experiments show that our framework outperforms existing methods in terms of generalization to unseen manipulations and datasets. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Reconstructing the 3D shape of an object from a single RGB image is a long-standing problem in computer vision. In this paper, we propose a novel method for single-image 3D reconstruction which generates a sparse point cloud via a conditional denoising diffusion process. Our method takes as input a single RGB image along with its camera pose and gradually denoises a set of 3D points, whose positions are initially sampled randomly from a three-dimensional Gaussian distribution, into the shape of an object. The key to our method is a geometrically-consistent conditioning process which we call projection conditioning: at each step in the diffusion process, we project local image features onto the partially-denoised point cloud from the given camera pose. This projection conditioning process enables us to generate high-resolution sparse geometries that are well-aligned with the input image and can additionally be used to predict point colors after shape reconstruction. Moreover, due to the probabilistic nature of the diffusion process, our method is naturally capable of generating multiple different shapes consistent with a single input image. In contrast to prior work, our approach not only performs well on synthetic benchmarks but also gives large qualitative improvements on complex real-world data. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] Correctness of instance segmentation constitutes counting the number of objects, correctly localizing all predictions and classifying each localized prediction. Average Precision is the de-facto metric used to measure all these constituents of segmentation. However, this metric does not penalize duplicate predictions in the high-recall range, and cannot distinguish instances that are localized correctly but categorized incorrectly. This weakness has inadvertently led to network designs that achieve significant gains in AP but also introduce a large number of false positives. We therefore cannot rely on AP to choose a model that provides an optimal tradeoff between false positives and high recall. To resolve this dilemma, we review alternative metrics in the literature and propose two new measures to explicitly measure the amount of both spatial and categorical duplicate predictions. We also propose a Semantic Sorting and NMS module to remove these duplicates based on a pixel occupancy matching scheme. Experiments show that modern segmentation networks have significant gains in AP, but also contain a considerable amount of duplicates. Our Semantic Sorting and NMS can be added as a plug-and-play module to mitigate hedged predictions and preserve AP. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Visual Place Recognition (VPR) estimates the location of query images by matching them with images in a reference database. Conventional methods generally adopt aggregated CNN features for global retrieval and RANSAC-based geometric verification for reranking. However, RANSAC only employs geometric information but ignores other possible information that could be useful for reranking, e.g. local feature correlations, and attention values. In this paper, we propose a unified place recognition framework that handles both retrieval and reranking with a novel transformer model, named R2Former. The proposed reranking module takes feature correlation, attention value, and xy coordinates into account, and learns to determine whether the image pair is from the same location. The whole pipeline is end-to-end trainable and the reranking module alone can also be adopted on other CNN or transformer backbones as a generic component. Remarkably, R2Former significantly outperforms state-of-the-art methods on major VPR datasets with much less inference time and memory consumption. It also achieves the state-of-the-art on the hold-out MSLS challenge set and could serve as a simple yet strong solution for real-world large-scale applications. Experiments also show vision transformer tokens are comparable and sometimes better than CNN local features on local matching. The code is released at https://github.com/Jeff-Zilence/R2Former. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Existing vector quantization (VQ) based autoregressive models follow a two-stage generation paradigm that first learns a codebook to encode images as discrete codes, and then completes generation based on the learned codebook. However, they encode fixed-size image regions into fixed-length codes and ignore their naturally different information densities, which results in insufficiency in important regions and redundancy in unimportant ones, and finally degrades the generation quality and speed. Moreover, the fixed-length coding leads to an unnatural raster-scan autoregressive generation. To address the problem, we propose a novel two-stage framework: (1) Dynamic-Quantization VAE (DQ-VAE) which encodes image regions into variable-length codes based on their information densities for an accurate & compact code representation. (2) DQ-Transformer which thereby generates images autoregressively from coarse-grained (smooth regions with fewer codes) to fine-grained (details regions with more codes) by modeling the position and content of codes in each granularity alternately, through a novel stacked-transformer architecture and shared-content, non-shared position input layers designs. Comprehensive experiments on various generation tasks validate our superiorities in both effectiveness and efficiency. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 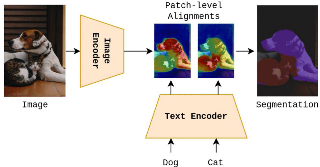
We introduce Patch Aligned Contrastive Learning (PACL), a modified compatibility function for CLIP’s contrastive loss, intending to train an alignment between the patch tokens of the vision encoder and the CLS token of the text encoder. With such an alignment, a model can identify regions of an image corresponding to a given text input, and therefore transfer seamlessly to the task of open vocabulary semantic segmentation without requiring any segmentation annotations during training. Using pre-trained CLIP encoders with PACL, we are able to set the state-of-the-art on the task of open vocabulary zero-shot segmentation on 4 different segmentation benchmarks: Pascal VOC, Pascal Context, COCO Stuff and ADE20K. Furthermore, we show that PACL is also applicable to image-level predictions and when used with a CLIP backbone, provides a general improvement in zero-shot classification accuracy compared to CLIP, across a suite of 12 image classification datasets. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 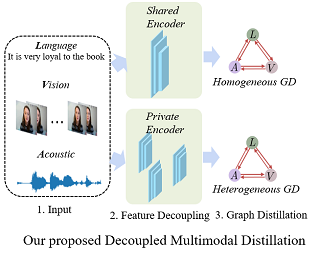
Human multimodal emotion recognition (MER) aims to perceive human emotions via language, visual and acoustic modalities. Despite the impressive performance of previous MER approaches, the inherent multimodal heterogeneities still haunt and the contribution of different modalities varies significantly. In this work, we mitigate this issue by proposing a decoupled multimodal distillation (DMD) approach that facilitates flexible and adaptive crossmodal knowledge distillation, aiming to enhance the discriminative features of each modality. Specially, the representation of each modality is decoupled into two parts, i.e., modality-irrelevant/-exclusive spaces, in a self-regression manner. DMD utilizes a graph distillation unit (GD-Unit) for each decoupled part so that each GD can be performed in a more specialized and effective manner. A GD-Unit consists of a dynamic graph where each vertice represents a modality and each edge indicates a dynamic knowledge distillation. Such GD paradigm provides a flexible knowledge transfer manner where the distillation weights can be automatically learned, thus enabling diverse crossmodal knowledge transfer patterns. Experimental results show DMD consistently obtains superior performance than state-of-the-art MER methods. Visualization results show the graph edges in DMD exhibit meaningful distributional patterns w.r.t. the modality-irrelevant/-exclusive feature spaces. Codes are released at https://github.com/mdswyz/DMD. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 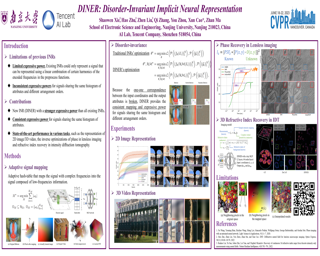
Implicit neural representation (INR) characterizes the attributes of a signal as a function of corresponding coordinates which emerges as a sharp weapon for solving inverse problems. However, the capacity of INR is limited by the spectral bias in the network training. In this paper, we find that such a frequency-related problem could be largely solved by re-arranging the coordinates of the input signal, for which we propose the disorder-invariant implicit neural representation (DINER) by augmenting a hash-table to a traditional INR backbone. Given discrete signals sharing the same histogram of attributes and different arrangement orders, the hash-table could project the coordinates into the same distribution for which the mapped signal can be better modeled using the subsequent INR network, leading to significantly alleviated spectral bias. Experiments not only reveal the generalization of the DINER for different INR backbones (MLP vs. SIREN) and various tasks (image/video representation, phase retrieval, and refractive index recovery) but also show the superiority over the state-of-the-art algorithms both in quality and speed. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 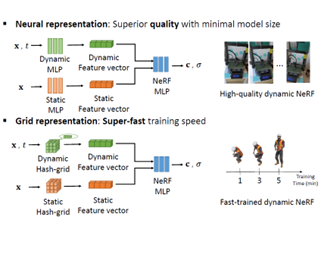
Temporal interpolation often plays a crucial role to learn meaningful representations in dynamic scenes. In this paper, we propose a novel method to train spatiotemporal neural radiance fields of dynamic scenes based on temporal interpolation of feature vectors. Two feature interpolation methods are suggested depending on underlying representations, neural networks or grids. In the neural representation, we extract features from space-time inputs via multiple neural network modules and interpolate them based on time frames. The proposed multi-level feature interpolation network effectively captures features of both short-term and long-term time ranges. In the grid representation, space-time features are learned via four-dimensional hash grids, which remarkably reduces training time. The grid representation shows more than 100 times faster training speed than the previous neural-net-based methods while maintaining the rendering quality. Concatenating static and dynamic features and adding a simple smoothness term further improve the performance of our proposed models. Despite the simplicity of the model architectures, our method achieved state-of-the-art performance both in rendering quality for the neural representation and in training speed for the grid representation. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 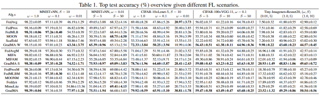
Federated Learning (FL) has emerged as a de facto machine learning area and received rapid increasing research interests from the community. However, catastrophic forgetting caused by data heterogeneity and partial participation poses distinctive challenges for FL, which are detrimental to the performance. To tackle the problems, we propose a new FL approach (namely GradMA), which takes inspiration from continual learning to simultaneously correct the server-side and worker-side update directions as well as take full advantage of server’s rich computing and memory resources. Furthermore, we elaborate a memory reduction strategy to enable GradMA to accommodate FL with a large scale of workers. We then analyze convergence of GradMA theoretically under the smooth non-convex setting and show that its convergence rate achieves a linear speed up w.r.t the increasing number of sampled active workers. At last, our extensive experiments on various image classification tasks show that GradMA achieves significant performance gains in accuracy and communication efficiency compared to SOTA baselines. We provide our code here: https://github.com/lkyddd/GradMA. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Rigorously testing autonomy systems is essential for making safe self-driving vehicles (SDV) a reality. It requires one to generate safety critical scenarios beyond what can be collected safely in the world, as many scenarios happen rarely on our roads. To accurately evaluate performance, we need to test the SDV on these scenarios in closed-loop, where the SDV and other actors interact with each other at each timestep. Previously recorded driving logs provide a rich resource to build these new scenarios from, but for closed loop evaluation, we need to modify the sensor data based on the new scene configuration and the SDV’s decisions, as actors might be added or removed and the trajectories of existing actors and the SDV will differ from the original log. In this paper, we present UniSim, a neural sensor simulator that takes a single recorded log captured by a sensor-equipped vehicle and converts it into a realistic closed-loop multi-sensor simulation. UniSim builds neural feature grids to reconstruct both the static background and dynamic actors in the scene, and composites them together to simulate LiDAR and camera data at new viewpoints, with actors added or removed and at new placements. To better handle extrapolated views, we … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 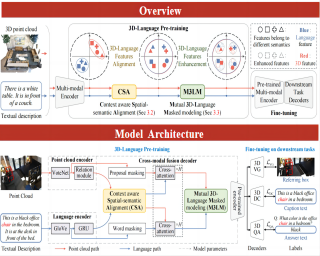
3D visual language reasoning plays an important role in effective human-computer interaction. The current approaches for 3D visual reasoning are task-specific, and lack pre-training methods to learn generic representations that can transfer across various tasks. Despite the encouraging progress in vision-language pre-training for image-text data, 3D-language pre-training is still an open issue due to limited 3D-language paired data, highly sparse and irregular structure of point clouds and ambiguities in spatial relations of 3D objects with viewpoint changes. In this paper, we present a generic 3D-language pre-training approach, that tackles multiple facets of 3D-language reasoning by learning universal representations. Our learning objective constitutes two main parts. 1) Context aware spatial-semantic alignment to establish fine-grained correspondence between point clouds and texts. It reduces relational ambiguities by aligning 3D spatial relationships with textual semantic context. 2) Mutual 3D-Language Masked modeling to enable cross-modality information exchange. Instead of reconstructing sparse 3D points for which language can hardly provide cues, we propose masked proposal reasoning to learn semantic class and mask-invariant representations. Our proposed 3D-language pre-training method achieves promising results once adapted to various downstream tasks, including 3D visual grounding, 3D dense captioning and 3D question answering. Our codes are available at https://github.com/leolyj/3D-VLP |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Egocentric videos are often available in the form of uninterrupted, uncurated long videos capturing the camera wearers’ daily life activities.Understanding these videos requires models to be able to reason about activities, objects, and their interactions. However, current video benchmarks study these problems independently and under short, curated clips. In contrast, real-world applications, e.g., AR assistants, require bundling these problems for both model development and evaluation. In this paper, we propose to study these problems in a joint framework for long video understanding. Our contributions are three-fold. First, we propose an integrated framework, namely Relational Space-Time Query (ReST), for evaluating video understanding models via templated spatiotemporal queries. Second, we introduce two new benchmarks, ReST-ADL and ReST-Ego4D, which augment the existing egocentric video datasets with abundant query annotations generated by the ReST framework. Finally, we present a set of baselines and in-depth analysis on the two benchmarks and provide insights about the query tasks. We view our integrated framework and benchmarks as a step towards comprehensive, multi-step reasoning in long videos, and believe it will facilitate the development of next generations of video understanding models. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Video-language embeddings are a promising avenue for injecting semantics into visual representations, but existing methods capture only short-term associations between seconds-long video clips and their accompanying text. We propose HierVL, a novel hierarchical video-language embedding that simultaneously accounts for both long-term and short-term associations. As training data, we take videos accompanied by timestamped text descriptions of human actions, together with a high-level text summary of the activity throughout the long video (as are available in Ego4D). We introduce a hierarchical contrastive training objective that encourages text-visual alignment at both the clip level and video level. While the clip-level constraints use the step-by-step descriptions to capture what is happening in that instant, the video-level constraints use the summary text to capture why it is happening, i.e., the broader context for the activity and the intent of the actor. Our hierarchical scheme yields a clip representation that outperforms its single-level counterpart, as well as a long-term video representation that achieves SotA results on tasks requiring long-term video modeling. HierVL successfully transfers to multiple challenging downstream tasks (in EPIC-KITCHENS-100, Charades-Ego, HowTo100M) in both zero-shot and fine-tuned settings. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 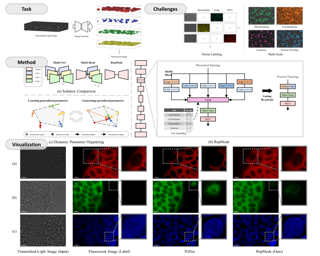
In biological research, fluorescence staining is a key technique to reveal the locations and morphology of subcellular structures. However, it is slow, expensive, and harmful to cells. In this paper, we model it as a deep learning task termed subcellular structure prediction (SSP), aiming to predict the 3D fluorescent images of multiple subcellular structures from a 3D transmitted-light image. Unfortunately, due to the limitations of current biotechnology, each image is partially labeled in SSP. Besides, naturally, subcellular structures vary considerably in size, which causes the multi-scale issue of SSP. To overcome these challenges, we propose Re-parameterizing Mixture-of-Diverse-Experts (RepMode), a network that dynamically organizes its parameters with task-aware priors to handle specified single-label prediction tasks. In RepMode, the Mixture-of-Diverse-Experts (MoDE) block is designed to learn the generalized parameters for all tasks, and gating re-parameterization (GatRep) is performed to generate the specialized parameters for each task, by which RepMode can maintain a compact practical topology exactly like a plain network, and meanwhile achieves a powerful theoretical topology. Comprehensive experiments show that RepMode can achieve state-of-the-art overall performance in SSP. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Indirect time-of-flight (iToF) imaging allows us to capture dense depth information at a low cost. However, iToF imaging often suffers from multipath interference (MPI) artifacts in the presence of scattering media, resulting in severe depth-accuracy degradation. For instance, iToF cameras cannot measure depth accurately through fog because ToF active illumination scatters back to the sensor before reaching the farther target surface. In this work, we propose a polarimetric iToF imaging method that can capture depth information robustly through scattering media. Our observations on the principle of indirect ToF imaging and polarization of light allow us to formulate a novel computational model of scattering-aware polarimetric phase measurements that enables us to correct MPI errors. We first devise a scattering-aware polarimetric iToF model that can estimate the phase of unpolarized backscattered light. We then combine the optical filtering of polarization and our computational modeling of unpolarized backscattered light via scattering analysis of phase and amplitude. This allows us to tackle the MPI problem by estimating the scattering energy through the participating media. We validate our method on an experimental setup using a customized off-the-shelf iToF camera. Our method outperforms baseline methods by a significant margin by means of our scattering model and … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Geometric camera calibration is often required for applications that understand the perspective of the image. We propose perspective fields as a representation that models the local perspective properties of an image. Perspective Fields contain per-pixel information about the camera view, parameterized as an up vector and a latitude value. This representation has a number of advantages as it makes minimal assumptions about the camera model and is invariant or equivariant to common image editing operations like cropping, warping, and rotation. It is also more interpretable and aligned with human perception. We train a neural network to predict Perspective Fields and the predicted Perspective Fields can be converted to calibration parameters easily. We demonstrate the robustness of our approach under various scenarios compared with camera calibration-based methods and show example applications in image compositing. Project page: https://jinlinyi.github.io/PerspectiveFields/ |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 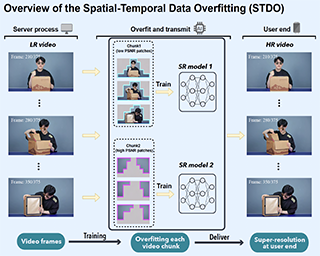
As deep convolutional neural networks (DNNs) are widely used in various fields of computer vision, leveraging the overfitting ability of the DNN to achieve video resolution upscaling has become a new trend in the modern video delivery system. By dividing videos into chunks and overfitting each chunk with a super-resolution model, the server encodes videos before transmitting them to the clients, thus achieving better video quality and transmission efficiency. However, a large number of chunks are expected to ensure good overfitting quality, which substantially increases the storage and consumes more bandwidth resources for data transmission. On the other hand, decreasing the number of chunks through training optimization techniques usually requires high model capacity, which significantly slows down execution speed. To reconcile such, we propose a novel method for high-quality and efficient video resolution upscaling tasks, which leverages the spatial-temporal information to accurately divide video into chunks, thus keeping the number of chunks as well as the model size to a minimum. Additionally, we advance our method into a single overfitting model by a data-aware joint training technique, which further reduces the storage requirement with negligible quality drop. We deploy our proposed overfitting models on an off-the-shelf mobile phone, and experimental … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 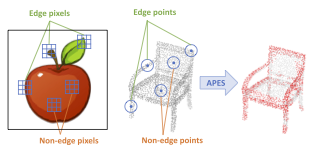
Point cloud sampling is a less explored research topic for this data representation. The most commonly used sampling methods are still classical random sampling and farthest point sampling. With the development of neural networks, various methods have been proposed to sample point clouds in a task-based learning manner. However, these methods are mostly generative-based, rather than selecting points directly using mathematical statistics. Inspired by the Canny edge detection algorithm for images and with the help of the attention mechanism, this paper proposes a non-generative Attention-based Point cloud Edge Sampling method (APES), which captures salient points in the point cloud outline. Both qualitative and quantitative experimental results show the superior performance of our sampling method on common benchmark tasks. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Self-supervised pretraining has achieved remarkable success in high-level vision, but its application in low-level vision remains ambiguous and not well-established. What is the primitive intention of pretraining? What is the core problem of pretraining in low-level vision? In this paper, we aim to answer these essential questions and establish a new pretraining scheme for low-level vision. Specifically, we examine previous pretraining methods in both high-level and low-level vision, and categorize current low-level vision tasks into two groups based on the difficulty of data acquisition: low-cost and high-cost tasks. Existing literature has mainly focused on pretraining for low-cost tasks, where the observed performance improvement is often limited. However, we argue that pretraining is more significant for high-cost tasks, where data acquisition is more challenging. To learn a general low-level vision representation that can improve the performance of various tasks, we propose a new pretraining paradigm called degradation autoencoder (DegAE). DegAE follows the philosophy of designing pretext task for self-supervised pretraining and is elaborately tailored to low-level vision. With DegAE pretraining, SwinIR achieves a 6.88dB performance gain on image dehaze task, while Uformer obtains 3.22dB and 0.54dB improvement on dehaze and derain tasks, respectively. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Unsupervised domain adaptation (UDA) in semantic segmentation transfers the knowledge of the source domain to the target one to improve the adaptability of the segmentation model in the target domain. The need to access labeled source data makes UDA unable to handle adaptation scenarios involving privacy, property rights protection, and confidentiality. In this paper, we focus on unsupervised model adaptation (UMA), also called source-free domain adaptation, which adapts a source-trained model to the target domain without accessing source data. We find that the online self-training method has the potential to be deployed in UMA, but the lack of source domain loss will greatly weaken the stability and adaptability of the method. We analyze the two possible reasons for the degradation of online self-training, i.e. inopportune updates of the teacher model and biased knowledge from source-trained model. Based on this, we propose a dynamic teacher update mechanism and a training-consistency based resampling strategy to improve the stability and adaptability of online self training. On multiple model adaptation benchmarks, our method obtains new state-of-the-art performance, which is comparable or even better than state-of-the-art UDA methods. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 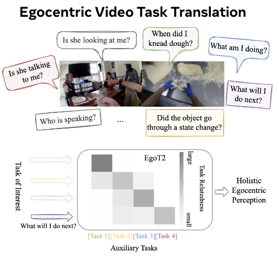
Different video understanding tasks are typically treated in isolation, and even with distinct types of curated data (e.g., classifying sports in one dataset, tracking animals in another). However, in wearable cameras, the immersive egocentric perspective of a person engaging with the world around them presents an interconnected web of video understanding tasks---hand-object manipulations, navigation in the space, or human-human interactions---that unfold continuously, driven by the person’s goals. We argue that this calls for a much more unified approach. We propose EgoTask Translation (EgoT2), which takes a collection of models optimized on separate tasks and learns to translate their outputs for improved performance on any or all of them at once. Unlike traditional transfer or multi-task learning, EgoT2’s “flipped design” entails separate task-specific backbones and a task translator shared across all tasks, which captures synergies between even heterogeneous tasks and mitigates task competition. Demonstrating our model on a wide array of video tasks from Ego4D, we show its advantages over existing transfer paradigms and achieve top-ranked results on four of the Ego4D 2022 benchmark challenges. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We propose DisCo-CLIP, a distributed memory-efficient CLIP training approach, to reduce the memory consumption of contrastive loss when training contrastive learning models. Our approach decomposes the contrastive loss and its gradient computation into two parts, one to calculate the intra-GPU gradients and the other to compute the inter-GPU gradients. According to our decomposition, only the intra-GPU gradients are computed on the current GPU, while the inter-GPU gradients are collected via all_reduce from other GPUs instead of being repeatedly computed on every GPU. In this way, we can reduce the GPU memory consumption of contrastive loss computation from O(B^2) to O(B^2 / N), where B and N are the batch size and the number of GPUs used for training. Such a distributed solution is mathematically equivalent to the original non-distributed contrastive loss computation, without sacrificing any computation accuracy. It is particularly efficient for large-batch CLIP training. For instance, DisCo-CLIP can enable contrastive training of a ViT-B/32 model with a batch size of 32K or 196K using 8 or 64 A100 40GB GPUs, compared with the original CLIP solution which requires 128 A100 40GB GPUs to train a ViT-B/32 model with a batch size of 32K. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 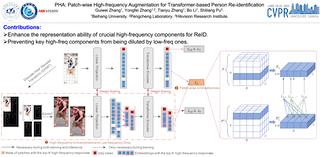
Although recent studies empirically show that injecting Convolutional Neural Networks (CNNs) into Vision Transformers (ViTs) can improve the performance of person re-identification, the rationale behind it remains elusive. From a frequency perspective, we reveal that ViTs perform worse than CNNs in preserving key high-frequency components (e.g, clothes texture details) since high-frequency components are inevitably diluted by low-frequency ones due to the intrinsic Self-Attention within ViTs. To remedy such inadequacy of the ViT, we propose a Patch-wise High-frequency Augmentation (PHA) method with two core designs. First, to enhance the feature representation ability of high-frequency components, we split patches with high-frequency components by the Discrete Haar Wavelet Transform, then empower the ViT to take the split patches as auxiliary input. Second, to prevent high-frequency components from being diluted by low-frequency ones when taking the entire sequence as input during network optimization, we propose a novel patch-wise contrastive loss. From the view of gradient optimization, it acts as an implicit augmentation to improve the representation ability of key high-frequency components. This benefits the ViT to capture key high-frequency components to extract discriminative person representations. PHA is necessary during training and can be removed during inference, without bringing extra complexity. Extensive experiments on widely-used … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 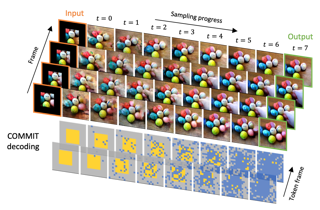
We introduce the MAsked Generative VIdeo Transformer, MAGVIT, to tackle various video synthesis tasks with a single model. We introduce a 3D tokenizer to quantize a video into spatial-temporal visual tokens and propose an embedding method for masked video token modeling to facilitate multi-task learning. We conduct extensive experiments to demonstrate the quality, efficiency, and flexibility of MAGVIT. Our experiments show that (i) MAGVIT performs favorably against state-of-the-art approaches and establishes the best-published FVD on three video generation benchmarks, including the challenging Kinetics-600. (ii) MAGVIT outperforms existing methods in inference time by two orders of magnitude against diffusion models and by 60x against autoregressive models. (iii) A single MAGVIT model supports ten diverse generation tasks and generalizes across videos from different visual domains. The source code and trained models will be released to the public at https://magvit.cs.cmu.edu. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 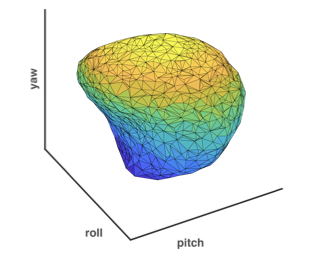
The two-stage object pose estimation paradigm first detects semantic keypoints on the image and then estimates the 6D pose by minimizing reprojection errors. Despite performing well on standard benchmarks, existing techniques offer no provable guarantees on the quality and uncertainty of the estimation. In this paper, we inject two fundamental changes, namely conformal keypoint detection and geometric uncertainty propagation, into the two-stage paradigm and propose the first pose estimator that endows an estimation with provable and computable worst-case error bounds. On one hand, conformal keypoint detection applies the statistical machinery of inductive conformal prediction to convert heuristic keypoint detections into circular or elliptical prediction sets that cover the groundtruth keypoints with a user-specified marginal probability (e.g., 90%). Geometric uncertainty propagation, on the other, propagates the geometric constraints on the keypoints to the 6D object pose, leading to a Pose UnceRtainty SEt (PURSE) that guarantees coverage of the groundtruth pose with the same probability. The PURSE, however, is a nonconvex set that does not directly lead to estimated poses and uncertainties. Therefore, we develop RANdom SAmple averaGing (RANSAG) to compute an average pose and apply semidefinite relaxation to upper bound the worst-case errors between the average pose and the groundtruth. On … |
|
Highlight
|
PointClustering: Unsupervised Point Cloud Pre-Training Using Transformation Invariance in Clustering
Poster
[ West Building Exhibit Halls ABC ] 
Feature invariance under different data transformations, i.e., transformation invariance, can be regarded as a type of self-supervision for representation learning. In this paper, we present PointClustering, a new unsupervised representation learning scheme that leverages transformation invariance for point cloud pre-training. PointClustering formulates the pretext task as deep clustering and employs transformation invariance as an inductive bias, following the philosophy that common point cloud transformation will not change the geometric properties and semantics. Technically, PointClustering iteratively optimizes the feature clusters and backbone, and delves into the transformation invariance as learning regularization from two perspectives: point level and instance level. Point-level invariance learning maintains local geometric properties through gathering point features of one instance across transformations, while instance-level invariance learning further measures clusters over the entire dataset to explore semantics of instances. Our PointClustering is architecture-agnostic and readily applicable to MLP-based, CNN-based and Transformer-based backbones. We empirically demonstrate that the models pre-learnt on the ScanNet dataset by PointClustering provide superior performances on six benchmarks, across downstream tasks of classification and segmentation. More remarkably, PointClustering achieves an accuracy of 94.5% on ModelNet40 with Transformer backbone. Source code is available at https://github.com/FuchenUSTC/PointClustering. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The recent success of text-to-image synthesis has taken the world by storm and captured the general public’s imagination. From a technical standpoint, it also marked a drastic change in the favored architecture to design generative image models. GANs used to be the de facto choice, with techniques like StyleGAN. With DALL-E 2, auto-regressive and diffusion models became the new standard for large-scale generative models overnight. This rapid shift raises a fundamental question: can we scale up GANs to benefit from large datasets like LAION? We find that naively increasing the capacity of the StyleGAN architecture quickly becomes unstable. We introduce GigaGAN, a new GAN architecture that far exceeds this limit, demonstrating GANs as a viable option for text-to-image synthesis. GigaGAN offers three major advantages. First, it is orders of magnitude faster at inference time, taking only 0.13 seconds to synthesize a 512px image. Second, it can synthesize high-resolution images, for example, 16-megapixel images in 3.66 seconds. Finally, GigaGAN supports various latent space editing applications such as latent interpolation, style mixing, and vector arithmetic operations. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 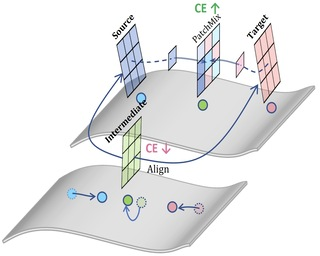
Endeavors have been recently made to leverage the vision transformer (ViT) for the challenging unsupervised domain adaptation (UDA) task. They typically adopt the cross-attention in ViT for direct domain alignment. However, as the performance of cross-attention highly relies on the quality of pseudo labels for targeted samples, it becomes less effective when the domain gap becomes large. We solve this problem from a game theory’s perspective with the proposed model dubbed as PMTrans, which bridges source and target domains with an intermediate domain. Specifically, we propose a novel ViT-based module called PatchMix that effectively builds up the intermediate domain, i.e., probability distribution, by learning to sample patches from both domains based on the game-theoretical models. This way, it learns to mix the patches from the source and target domains to maximize the cross entropy (CE), while exploiting two semi-supervised mixup losses in the feature and label spaces to minimize it. As such, we interpret the process of UDA as a min-max CE game with three players, including the feature extractor, classifier, and PatchMix, to find the Nash Equilibria. Moreover, we leverage attention maps from ViT to re-weight the label of each patch by its importance, making it possible to obtain … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In contrast to sparse keypoints, a handful of line segments can concisely encode the high-level scene layout, as they often delineate the main structural elements. In addition to offering strong geometric cues, they are also omnipresent in urban landscapes and indoor scenes. Despite their apparent advantages, current line-based reconstruction methods are far behind their point-based counterparts. In this paper we aim to close the gap by introducing LIMAP, a library for 3D line mapping that robustly and efficiently creates 3D line maps from multi-view imagery. This is achieved through revisiting the degeneracy problem of line triangulation, carefully crafted scoring and track building, and exploiting structural priors such as line coincidence, parallelism, and orthogonality. Our code integrates seamlessly with existing point-based Structure-from-Motion methods and can leverage their 3D points to further improve the line reconstruction. Furthermore, as a byproduct, the method is able to recover 3D association graphs between lines and points / vanishing points (VPs). In thorough experiments, we show that LIMAP significantly outperforms existing approaches for 3D line mapping. Our robust 3D line maps also open up new research directions. We show two example applications: visual localization and bundle adjustment, where integrating lines alongside points yields the best results. … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 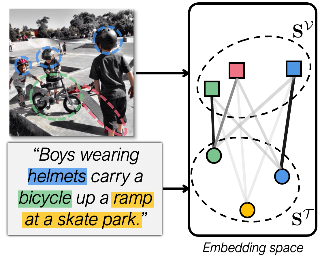
Cross-modal retrieval across image and text modalities is a challenging task due to its inherent ambiguity: An image often exhibits various situations, and a caption can be coupled with diverse images. Set-based embedding has been studied as a solution to this problem. It seeks to encode a sample into a set of different embedding vectors that capture different semantics of the sample. In this paper, we present a novel set-based embedding method, which is distinct from previous work in two aspects. First, we present a new similarity function called smooth-Chamfer similarity, which is designed to alleviate the side effects of existing similarity functions for set-based embedding. Second, we propose a novel set prediction module to produce a set of embedding vectors that effectively captures diverse semantics of input by the slot attention mechanism. Our method is evaluated on the COCO and Flickr30K datasets across different visual backbones, where it outperforms existing methods including ones that demand substantially larger computation at inference. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 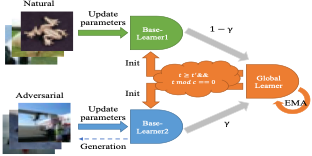
Deep neural networks obtained by standard training have been constantly plagued by adversarial examples. Although adversarial training demonstrates its capability to defend against adversarial examples, unfortunately, it leads to an inevitable drop in the natural generalization. To address the issue, we decouple the natural generalization and the robust generalization from joint training and formulate different training strategies for each one. Specifically, instead of minimizing a global loss on the expectation over these two generalization errors, we propose a bi-expert framework called Generalist where we simultaneously train base learners with task-aware strategies so that they can specialize in their own fields. The parameters of base learners are collected and combined to form a global learner at intervals during the training process. The global learner is then distributed to the base learners as initialized parameters for continued training. Theoretically, we prove that the risks of Generalist will get lower once the base learners are well trained. Extensive experiments verify the applicability of Generalist to achieve high accuracy on natural examples while maintaining considerable robustness to adversarial ones. Code is available at https://github.com/PKU-ML/Generalist. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 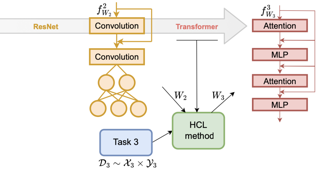
We propose a novel framework and a solution to tackle the continual learning (CL) problem with changing network architectures. Most CL methods focus on adapting a single architecture to a new task/class by modifying its weights. However, with rapid progress in architecture design, the problem of adapting existing solutions to novel architectures becomes relevant. To address this limitation, we propose Heterogeneous Continual Learning (HCL), where a wide range of evolving network architectures emerge continually together with novel data/tasks. As a solution, we build on top of the distillation family of techniques and modify it to a new setting where a weaker model takes the role of a teacher; meanwhile, a new stronger architecture acts as a student. Furthermore, we consider a setup of limited access to previous data and propose Quick Deep Inversion (QDI) to recover prior task visual features to support knowledge transfer. QDI significantly reduces computational costs compared to previous solutions and improves overall performance. In summary, we propose a new setup for CL with a modified knowledge distillation paradigm and design a quick data inversion method to enhance distillation. Our evaluation of various benchmarks shows a significant improvement on accuracy in comparison to state-of-the-art methods over various … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Virtual reality and augmented reality (XR) bring increasing demand for 3D content generation. However, creating high-quality 3D content requires tedious work from a human expert. In this work, we study the challenging task of lifting a single image to a 3D object and, for the first time, demonstrate the ability to generate a plausible 3D object with 360° views that corresponds well with the given reference image. By conditioning on the reference image, our model can fulfill the everlasting curiosity for synthesizing novel views of objects from images. Our technique sheds light on a promising direction of easing the workflows for 3D artists and XR designers. We propose a novel framework, dubbed NeuralLift-360, that utilizes a depth-aware neural radiance representation (NeRF) and learns to craft the scene guided by denoising diffusion models. By introducing a ranking loss, our NeuralLift-360 can be guided with rough depth estimation in the wild. We also adopt a CLIP-guided sampling strategy for the diffusion prior to provide coherent guidance. Extensive experiments demonstrate that our NeuralLift-360 significantly outperforms existing state-of-the-art baselines. Project page: https://vita-group.github.io/NeuralLift-360/ |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, we find that--across 7 architectures trained with 4 algorithms on massive datasets--they struggle at compositionality. To arrive at this conclusion, we introduce a new compositionality evaluation benchmark, CREPE, which measures two important aspects of compositionality identified by cognitive science literature: systematicity and productivity. To measure systematicity, CREPE consists of a test dataset containing over 370K image-text pairs and three different seen-unseen splits. The three splits are designed to test models trained on three popular training datasets: CC-12M, YFCC-15M, and LAION-400M. We also generate 325K, 316K, and 309K hard negative captions for a subset of the pairs. To test productivity, CREPE contains 17K image-text pairs with nine different complexities plus 278K hard negative captions with atomic, swapping, and negation foils. The datasets are generated by repurposing the Visual Genome scene graphs and region descriptions and applying handcrafted templates and GPT-3. For systematicity, we find that model performance decreases consistently when novel compositions dominate the retrieval set, with Recall@1 dropping by up to 9%. For productivity, models’ retrieval success decays as complexity increases, frequently nearing … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 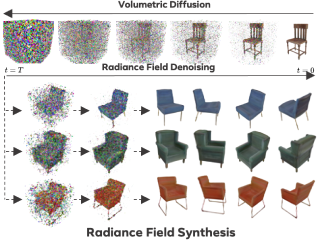
We introduce DiffRF, a novel approach for 3D radiance field synthesis based on denoising diffusion probabilistic models. While existing diffusion-based methods operate on images, latent codes, or point cloud data, we are the first to directly generate volumetric radiance fields. To this end, we propose a 3D denoising model which directly operates on an explicit voxel grid representation. However, as radiance fields generated from a set of posed images can be ambiguous and contain artifacts, obtaining ground truth radiance field samples is non-trivial. We address this challenge by pairing the denoising formulation with a rendering loss, enabling our model to learn a deviated prior that favours good image quality instead of trying to replicate fitting errors like floating artifacts. In contrast to 2D-diffusion models, our model learns multi-view consistent priors, enabling free-view synthesis and accurate shape generation. Compared to 3D GANs, our diffusion-based approach naturally enables conditional generation like masked completion or single-view 3D synthesis at inference time. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In this paper, we study the problem of procedure planning in instructional videos, which aims to make goal-directed plans given the current visual observations in unstructured real-life videos. Previous works cast this problem as a sequence planning problem and leverage either heavy intermediate visual observations or natural language instructions as supervision, resulting in complex learning schemes and expensive annotation costs. In contrast, we treat this problem as a distribution fitting problem. In this sense, we model the whole intermediate action sequence distribution with a diffusion model (PDPP), and thus transform the planning problem to a sampling process from this distribution. In addition, we remove the expensive intermediate supervision, and simply use task labels from instructional videos as supervision instead. Our model is a U-Net based diffusion model, which directly samples action sequences from the learned distribution with the given start and end observations. Furthermore, we apply an efficient projection method to provide accurate conditional guides for our model during the learning and sampling process. Experiments on three datasets with different scales show that our PDPP model can achieve the state-of-the-art performance on multiple metrics, even without the task supervision. Code and trained models are available at https://github.com/MCG-NJU/PDPP. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Privacy-preserving image generation has been important for segments such as medical domains that have sensitive and limited data. The benefits of guaranteed privacy come at the costs of generated images’ quality and utility due to the privacy budget constraints. The utility is currently measured by the gen2real accuracy (g2r%), i.e., the accuracy on real data of a downstream classifier trained using generated data. However, apart from this standard utility, we identify the “reversed utility” as another crucial aspect, which computes the accuracy on generated data of a classifier trained using real data, dubbed as real2gen accuracy (r2g%). Jointly considering these two views of utility, the standard and the reversed, could help the generation model better improve transferability between fake and real data. Therefore, we propose a novel private image generation method that incorporates a dual-purpose auxiliary classifier, which alternates between learning from real data and fake data, into the training of differentially private GANs. Additionally, our deliberate training strategies such as sequential training contributes to accelerating the generator’s convergence and further boosting the performance upon exhausting the privacy budget. Our results achieve new state-of-the-arts over all metrics on three benchmarks: MNIST, Fashion-MNIST, and CelebA. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 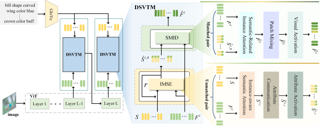
Generalized Zero-Shot Learning (GZSL) identifies unseen categories by knowledge transferred from the seen domain, relying on the intrinsic interactions between visual and semantic information. Prior works mainly localize regions corresponding to the sharing attributes. When various visual appearances correspond to the same attribute, the sharing attributes inevitably introduce semantic ambiguity, hampering the exploration of accurate semantic-visual interactions. In this paper, we deploy the dual semantic-visual transformer module (DSVTM) to progressively model the correspondences between attribute prototypes and visual features, constituting a progressive semantic-visual mutual adaption (PSVMA) network for semantic disambiguation and knowledge transferability improvement. Specifically, DSVTM devises an instance-motivated semantic encoder that learns instance-centric prototypes to adapt to different images, enabling the recast of the unmatched semantic-visual pair into the matched one. Then, a semantic-motivated instance decoder strengthens accurate cross-domain interactions between the matched pair for semantic-related instance adaption, encouraging the generation of unambiguous visual representations. Moreover, to mitigate the bias towards seen classes in GZSL, a debiasing loss is proposed to pursue response consistency between seen and unseen predictions. The PSVMA consistently yields superior performances against other state-of-the-art methods. Code will be available at: https://github.com/ManLiuCoder/PSVMA. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 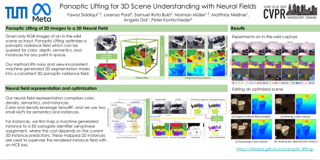
We propose Panoptic Lifting, a novel approach for learning panoptic 3D volumetric representations from images of in-the-wild scenes. Once trained, our model can render color images together with 3D-consistent panoptic segmentation from novel viewpoints. Unlike existing approaches which use 3D input directly or indirectly, our method requires only machine-generated 2D panoptic segmentation masks inferred from a pre-trained network. Our core contribution is a panoptic lifting scheme based on a neural field representation that generates a unified and multi-view consistent, 3D panoptic representation of the scene. To account for inconsistencies of 2D instance identifiers across views, we solve a linear assignment with a cost based on the model’s current predictions and the machine-generated segmentation masks, thus enabling us to lift 2D instances to 3D in a consistent way. We further propose and ablate contributions that make our method more robust to noisy, machine-generated labels, including test-time augmentations for confidence estimates, segment consistency loss, bounded segmentation fields, and gradient stopping. Experimental results validate our approach on the challenging Hypersim, Replica, and ScanNet datasets, improving by 8.4, 13.8, and 10.6% in scene-level PQ over state of the art. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In the field of binocular stereo matching, remarkable progress has been made by iterative methods like RAFT-Stereo and CREStereo. However, most of these methods lose information during the iterative process, making it difficult to generate more detailed difference maps that take full advantage of high-frequency information. We propose the Decouple module to alleviate the problem of data coupling and allow features containing subtle details to transfer across the iterations which proves to alleviate the problem significantly in the ablations. To further capture high-frequency details, we propose a Normalization Refinement module that unifies the disparities as a proportion of the disparities over the width of the image, which address the problem of module failure in cross-domain scenarios. Further, with the above improvements, the ResNet-like feature extractor that has not been changed for years becomes a bottleneck. Towards this end, we proposed a multi-scale and multi-stage feature extractor that introduces the channel-wise self-attention mechanism which greatly addresses this bottleneck. Our method (DLNR) ranks 1st on the Middlebury leaderboard, significantly outperforming the next best method by 13.04%. Our method also achieves SOTA performance on the KITTI-2015 benchmark for D1-fg. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Modern perception systems of autonomous vehicles are known to be sensitive to occlusions and lack the capability of long perceiving range. It has been one of the key bottlenecks that prevents Level 5 autonomy. Recent research has demonstrated that the Vehicle-to-Vehicle (V2V) cooperative perception system has great potential to revolutionize the autonomous driving industry. However, the lack of a real-world dataset hinders the progress of this field. To facilitate the development of cooperative perception, we present V2V4Real, the first large-scale real-world multi-modal dataset for V2V perception. The data is collected by two vehicles equipped with multi-modal sensors driving together through diverse scenarios. Our V2V4Real dataset covers a driving area of 410 km, comprising 20K LiDAR frames, 40K RGB frames, 240K annotated 3D bounding boxes for 5 classes, and HDMaps that cover all the driving routes. V2V4Real introduces three perception tasks, including cooperative 3D object detection, cooperative 3D object tracking, and Sim2Real domain adaptation for cooperative perception. We provide comprehensive benchmarks of recent cooperative perception algorithms on three tasks. The V2V4Real dataset can be found at research.seas.ucla.edu/mobility-lab/v2v4real/. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 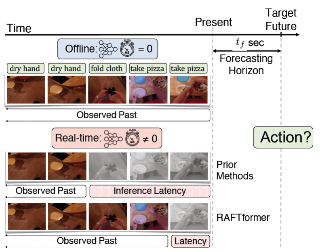
We present RAFTformer, a real-time action forecasting transformer for latency aware real-world action forecasting applications. RAFTformer is a two-stage fully transformer based architecture which consists of a video transformer backbone that operates on high resolution, short range clips and a head transformer encoder that temporally aggregates information from multiple short range clips to span a long-term horizon. Additionally, we propose a self-supervised shuffled causal masking scheme to improve model generalization during training. Finally, we also propose a real-time evaluation setting that directly couples model inference latency to overall forecasting performance and brings forth an hitherto overlooked trade-off between latency and action forecasting performance. Our parsimonious network design facilitates RAFTformer inference latency to be 9x smaller than prior works at the same forecasting accuracy. Owing to its two-staged design, RAFTformer uses 94% less training compute and 90% lesser training parameters to outperform prior state-of-the-art baselines by 4.9 points on EGTEA Gaze+ and by 1.4 points on EPIC-Kitchens-100 dataset, as measured by Top-5 recall (T5R) in the offline setting. In the real-time setting, RAFTformer outperforms prior works by an even greater margin of upto 4.4 T5R points on the EPIC-Kitchens-100 dataset. Project Webpage: https://karttikeya.github.io/publication/RAFTformer/ |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 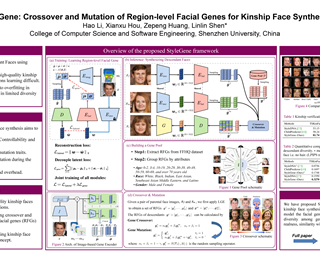
High-fidelity kinship face synthesis has many potential applications, such as kinship verification, missing child identification, and social media analysis. However, it is challenging to synthesize high-quality descendant faces with genetic relations due to the lack of large-scale, high-quality annotated kinship data. This paper proposes RFG (Region-level Facial Gene) extraction framework to address this issue. We propose to use IGE (Image-based Gene Encoder), LGE (Latent-based Gene Encoder) and Gene Decoder to learn the RFGs of a given face image, and the relationships between RFGs and the latent space of StyleGAN2. As cycle-like losses are designed to measure the L_2 distances between the output of Gene Decoder and image encoder, and that between the output of LGE and IGE, only face images are required to train our framework, i.e. no paired kinship face data is required. Based upon the proposed RFGs, a crossover and mutation module is further designed to inherit the facial parts of parents. A Gene Pool has also been used to introduce the variations into the mutation of RFGs. The diversity of the faces of descendants can thus be significantly increased. Qualitative, quantitative, and subjective experiments on FIW, TSKinFace, and FF-Databases clearly show that the quality and diversity of … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Referring Expression Segmentation (RES) aims to generate a segmentation mask for the object described by a given language expression. Existing classic RES datasets and methods commonly support single-target expressions only, i.e., one expression refers to one target object. Multi-target and no-target expressions are not considered. This limits the usage of RES in practice. In this paper, we introduce a new benchmark called Generalized Referring Expression Segmentation (GRES), which extends the classic RES to allow expressions to refer to an arbitrary number of target objects. Towards this, we construct the first large-scale GRES dataset called gRefCOCO that contains multi-target, no-target, and single-target expressions. GRES and gRefCOCO are designed to be well-compatible with RES, facilitating extensive experiments to study the performance gap of the existing RES methods on the GRES task. In the experimental study, we find that one of the big challenges of GRES is complex relationship modeling. Based on this, we propose a region-based GRES baseline ReLA that adaptively divides the image into regions with sub-instance clues, and explicitly models the region-region and region-language dependencies. The proposed approach ReLA achieves new state-of-the-art performance on the both newly proposed GRES and classic RES tasks. The proposed gRefCOCO dataset and method are … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present ODISE: Open-vocabulary DIffusion-based panoptic SEgmentation, which unifies pre-trained text-image diffusion and discriminative models to perform open-vocabulary panoptic segmentation. Text-to-image diffusion models have the remarkable ability to generate high-quality images with diverse open-vocabulary language descriptions. This demonstrates that their internal representation space is highly correlated with open concepts in the real world. Text-image discriminative models like CLIP, on the other hand, are good at classifying images into open-vocabulary labels. We leverage the frozen internal representations of both these models to perform panoptic segmentation of any category in the wild. Our approach outperforms the previous state of the art by significant margins on both open-vocabulary panoptic and semantic segmentation tasks. In particular, with COCO training only, our method achieves 23.4 PQ and 30.0 mIoU on the ADE20K dataset, with 8.3 PQ and 7.9 mIoU absolute improvement over the previous state of the art. We open-source our code and models at https://github.com/NVlabs/ODISE. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Neural Radiance Field (NeRF) has recently emerged as a powerful representation to synthesize photorealistic novel views. While showing impressive performance, it relies on the availability of dense input views with highly accurate camera poses, thus limiting its application in real-world scenarios. In this work, we introduce Sparse Pose Adjusting Radiance Field (SPARF), to address the challenge of novel-view synthesis given only few wide-baseline input images (as low as 3) with noisy camera poses. Our approach exploits multi-view geometry constraints in order to jointly learn the NeRF and refine the camera poses. By relying on pixel matches extracted between the input views, our multi-view correspondence objective enforces the optimized scene and camera poses to converge to a global and geometrically accurate solution. Our depth consistency loss further encourages the reconstructed scene to be consistent from any viewpoint. Our approach sets a new state of the art in the sparse-view regime on multiple challenging datasets. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Outlier-robust estimation involves estimating some parameters (e.g., 3D rotations) from data samples in the presence of outliers, and is typically formulated as a non-convex and non-smooth problem. For this problem, the classical method called iteratively reweighted least-squares (IRLS) and its variants have shown impressive performance. This paper makes several contributions towards understanding why these algorithms work so well. First, we incorporate majorization and graduated non-convexity (GNC) into the IRLS framework and prove that the resulting IRLS variant is a convergent method for outlier-robust estimation. Moreover, in the robust regression context with a constant fraction of outliers, we prove this IRLS variant converges to the ground truth at a global linear and local quadratic rate for a random Gaussian feature matrix with high probability. Experiments corroborate our theory and show that the proposed IRLS variant converges within 5-10 iterations for typical problem instances of outlier-robust estimation, while state-of-the-art methods need at least 30 iterations. A basic implementation of our method is provided: https://github.com/liangzu/IRLS-CVPR2023 |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Inferring the structure of 3D scenes from 2D observations is a fundamental challenge in computer vision. Recently popularized approaches based on neural scene representations have achieved tremendous impact and have been applied across a variety of applications. One of the major remaining challenges in this space is training a single model which can provide latent representations which effectively generalize beyond a single scene. Scene Representation Transformer (SRT) has shown promise in this direction, but scaling it to a larger set of diverse scenes is challenging and necessitates accurately posed ground truth data. To address this problem, we propose RUST (Really Unposed Scene representation Transformer), a pose-free approach to novel view synthesis trained on RGB images alone. Our main insight is that one can train a Pose Encoder that peeks at the target image and learns a latent pose embedding which is used by the decoder for view synthesis. We perform an empirical investigation into the learned latent pose structure and show that it allows meaningful test-time camera transformations and accurate explicit pose readouts. Perhaps surprisingly, RUST achieves similar quality as methods which have access to perfect camera pose, thereby unlocking the potential for large-scale training of amortized neural scene representations. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video forensics method, based on anomaly detection, that can identify these inconsistencies, and that can be trained solely using real, unlabeled data. We train an autoregressive model to generate sequences of audio-visual features, using feature sets that capture the temporal synchronization between video frames and sound. At test time, we then flag videos that the model assigns low probability. Despite being trained entirely on real videos, our model obtains strong performance on the task of detecting manipulated speech videos. Project site: https://cfeng16.github.io/audio-visual-forensics. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Semantic image editing provides users with a flexible tool to modify a given image guided by a corresponding segmentation map. In this task, the features of the foreground objects and the backgrounds are quite different. However, all previous methods handle backgrounds and objects as a whole using a monolithic model. Consequently, they remain limited in processing content-rich images and suffer from generating unrealistic objects and texture-inconsistent backgrounds. To address this issue, we propose a novel paradigm, Semantic Image Editing by Disentangling Object and Background (SIEDOB), the core idea of which is to explicitly leverages several heterogeneous subnetworks for objects and backgrounds. First, SIEDOB disassembles the edited input into background regions and instance-level objects. Then, we feed them into the dedicated generators. Finally, all synthesized parts are embedded in their original locations and utilize a fusion network to obtain a harmonized result. Moreover, to produce high-quality edited images, we propose some innovative designs, including Semantic-Aware Self-Propagation Module, Boundary-Anchored Patch Discriminator, and Style-Diversity Object Generator, and integrate them into SIEDOB. We conduct extensive experiments on Cityscapes and ADE20K-Room datasets and exhibit that our method remarkably outperforms the baselines, especially in synthesizing realistic and diverse objects and texture-consistent backgrounds. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 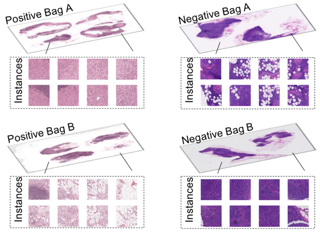
Multi-instance learning (MIL) is an effective paradigm for whole-slide pathological images (WSIs) classification to handle the gigapixel resolution and slide-level label. Prevailing MIL methods primarily focus on improving the feature extractor and aggregator. However, one deficiency of these methods is that the bag contextual prior may trick the model into capturing spurious correlations between bags and labels. This deficiency is a confounder that limits the performance of existing MIL methods. In this paper, we propose a novel scheme, Interventional Bag Multi-Instance Learning (IBMIL), to achieve deconfounded bag-level prediction. Unlike traditional likelihood-based strategies, the proposed scheme is based on the backdoor adjustment to achieve the interventional training, thus is capable of suppressing the bias caused by the bag contextual prior. Note that the principle of IBMIL is orthogonal to existing bag MIL methods. Therefore, IBMIL is able to bring consistent performance boosting to existing schemes, achieving new state-of-the-art performance. Code is available at https://github.com/HHHedo/IBMIL. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 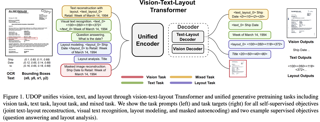
We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 8 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 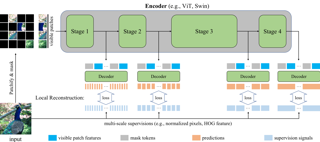
Masked Image Modeling (MIM) achieves outstanding success in self-supervised representation learning. Unfortunately, MIM models typically have huge computational burden and slow learning process, which is an inevitable obstacle for their industrial applications. Although the lower layers play the key role in MIM, existing MIM models conduct reconstruction task only at the top layer of encoder. The lower layers are not explicitly guided and the interaction among their patches is only used for calculating new activations. Considering the reconstruction task requires non-trivial inter-patch interactions to reason target signals, we apply it to multiple local layers including lower and upper layers. Further, since the multiple layers expect to learn the information of different scales, we design local multi-scale reconstruction, where the lower and upper layers reconstruct fine-scale and coarse-scale supervision signals respectively. This design not only accelerates the representation learning process by explicitly guiding multiple layers, but also facilitates multi-scale semantical understanding to the input. Extensive experiments show that with significantly less pre-training burden, our model achieves comparable or better performance on classification, detection and segmentation tasks than existing MIM models. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Objects make unique sounds under different perturbations, environment conditions, and poses relative to the listener. While prior works have modeled impact sounds and sound propagation in simulation, we lack a standard dataset of impact sound fields of real objects for audio-visual learning and calibration of the sim-to-real gap. We present RealImpact, a large-scale dataset of real object impact sounds recorded under controlled conditions. RealImpact contains 150,000 recordings of impact sounds of 50 everyday objects with detailed annotations, including their impact locations, microphone locations, contact force profiles, material labels, and RGBD images. We make preliminary attempts to use our dataset as a reference to current simulation methods for estimating object impact sounds that match the real world. Moreover, we demonstrate the usefulness of our dataset as a testbed for acoustic and audio-visual learning via the evaluation of two benchmark tasks, including listener location classification and visual acoustic matching. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The accuracy of crowd counting in images has improved greatly in recent years due to the development of deep neural networks for predicting crowd density maps. However, most methods do not further explore the ability to localize people in the density map, with those few works adopting simple methods, like finding the local peaks in the density map. In this paper, we propose the optimal transport minimization (OT-M) algorithm for crowd localization with density maps. The objective of OT-M is to find a target point map that has the minimal Sinkhorn distance with the input density map, and we propose an iterative algorithm to compute the solution. We then apply OT-M to generate hard pseudo-labels (point maps) for semi-supervised counting, rather than the soft pseudo-labels (density maps) used in previous methods. Our hard pseudo-labels provide stronger supervision, and also enable the use of recent density-to-point loss functions for training. We also propose a confidence weighting strategy to give higher weight to the more reliable unlabeled data. Extensive experiments show that our methods achieve outstanding performance on both crowd localization and semi-supervised counting. Code is available at https://github.com/Elin24/OT-M. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] While adaptive learning rate methods, such as Adam, have achieved remarkable improvement in optimizing Deep Neural Networks (DNNs), they consider only the diagonal elements of the full preconditioned matrix. Though the full-matrix preconditioned gradient methods theoretically have a lower regret bound, they are impractical for use to train DNNs because of the high complexity. In this paper, we present a general regret bound with a constrained full-matrix preconditioned gradient and show that the updating formula of the preconditioner can be derived by solving a cone-constrained optimization problem. With the block-diagonal and Kronecker-factorized constraints, a specific guide function can be obtained. By minimizing the upper bound of the guide function, we develop a new DNN optimizer, termed AdaBK. A series of techniques, including statistics updating, dampening, efficient matrix inverse root computation, and gradient amplitude preservation, are developed to make AdaBK effective and efficient to implement. The proposed AdaBK can be readily embedded into many existing DNN optimizers, e.g., SGDM and AdamW, and the corresponding SGDMBK and AdamWBK algorithms demonstrate significant improvements over existing DNN optimizers on benchmark vision tasks, including image classification, object detection and segmentation. The source code will be made publicly available. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 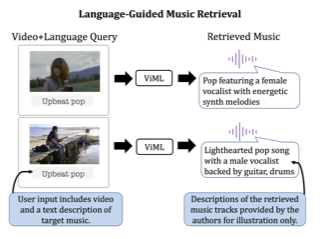
We propose a method to recommend music for an input video while allowing a user to guide music selection with free-form natural language. A key challenge of this problem setting is that existing music video datasets provide the needed (video, music) training pairs, but lack text descriptions of the music. This work addresses this challenge with the following three contributions. First, we propose a text-synthesis approach that relies on an analogy-based prompting procedure to generate natural language music descriptions from a large-scale language model (BLOOM-176B) given pre-trained music tagger outputs and a small number of human text descriptions. Second, we use these synthesized music descriptions to train a new trimodal model, which fuses text and video input representations to query music samples. For training, we introduce a text dropout regularization mechanism which we show is critical to model performance. Our model design allows for the retrieved music audio to agree with the two input modalities by matching visual style depicted in the video and musical genre, mood, or instrumentation described in the natural language query. Third, to evaluate our approach, we collect a testing dataset for our problem by annotating a subset of 4k clips from the YT8M-MusicVideo dataset with … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] We propose a new framework for conditional image synthesis from semantic layouts of any precision levels, ranging from pure text to a 2D semantic canvas with precise shapes. More specifically, the input layout consists of one or more semantic regions with free-form text descriptions and adjustable precision levels, which can be set based on the desired controllability. The framework naturally reduces to text-to-image (T2I) at the lowest level with no shape information, and it becomes segmentation-to-image (S2I) at the highest level. By supporting the levels in-between, our framework is flexible in assisting users of different drawing expertise and at different stages of their creative workflow. We introduce several novel techniques to address the challenges coming with this new setup, including a pipeline for collecting training data; a precision-encoded mask pyramid and a text feature map representation to jointly encode precision level, semantics, and composition information; and a multi-scale guided diffusion model to synthesize images. To evaluate the proposed method, we collect a test dataset containing user-drawn layouts with diverse scenes and styles. Experimental results show that the proposed method can generate high-quality images following the layout at given precision, and compares favorably against existing methods. Project page https://zengxianyu.github.io/scenec/ |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Domain shift degrades the performance of object detection models in practical applications. To alleviate the influence of domain shift, plenty of previous work try to decouple and learn the domain-invariant (common) features from source domains via domain adversarial learning (DAL). However, inspired by causal mechanisms, we find that previous methods ignore the implicit insignificant non-causal factors hidden in the common features. This is mainly due to the single-view nature of DAL. In this work, we present an idea to remove non-causal factors from common features by multi-view adversarial training on source domains, because we observe that such insignificant non-causal factors may still be significant in other latent spaces (views) due to the multi-mode structure of data. To summarize, we propose a Multi-view Adversarial Discriminator (MAD) based domain generalization model, consisting of a Spurious Correlations Generator (SCG) that increases the diversity of source domain by random augmentation and a Multi-View Domain Classifier (MVDC) that maps features to multiple latent spaces, such that the non-causal factors are removed and the domain-invariant features are purified. Extensive experiments on six benchmarks show our MAD obtains state-of-the-art performance. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Vector graphics (VG) are ubiquitous in industrial designs. In this paper, we address semantic segmentation of a typical VG, i.e., roughcast floorplans with bare wall structures, whose output can be directly used for further applications like interior furnishing and room space modeling. Previous semantic segmentation works mostly process well-decorated floorplans in raster images and usually yield aliased boundaries and outlier fragments in segmented rooms, due to pixel-level segmentation that ignores the regular elements (e.g. line segments) in vector floorplans. To overcome these issues, we propose to fully utilize the regular elements in vector floorplans for more integral segmentation. Our pipeline predicts room segmentation from vector floorplans by dually classifying line segments as room boundaries, and regions partitioned by line segments as room segments. To fully exploit the structural relationships between lines and regions, we use two-stream graph neural networks to process the line segments and partitioned regions respectively, and devise a novel modulated graph attention layer to fuse the heterogeneous information from one stream to the other. Extensive experiments show that by directly operating on vector floorplans, we outperform image-based methods in both mIoU and mAcc. In addition, we propose a new metric that captures room integrity and boundary regularity, … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Clothes undergo complex geometric deformations, which lead to appearance changes. To edit human videos in a physically plausible way, a texture map must take into account not only the garment transformation induced by the body movements and clothes fitting, but also its 3D fine-grained surface geometry. This poses, however, a new challenge of 3D reconstruction of dynamic clothes from an image or a video. In this paper, we show that it is possible to edit dressed human images and videos without 3D reconstruction. We estimate a geometry aware texture map between the garment region in an image and the texture space, a.k.a, UV map. Our UV map is designed to preserve isometry with respect to the underlying 3D surface by making use of the 3D surface normals predicted from the image. Our approach captures the underlying geometry of the garment in a self-supervised way, requiring no ground truth annotation of UV maps and can be readily extended to predict temporally coherent UV maps. We demonstrate that our method outperforms the state-of-the-art human UV map estimation approaches on both real and synthetic data. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 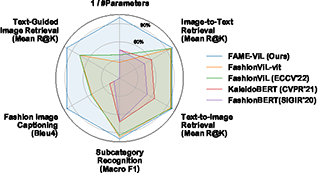
In the fashion domain, there exists a variety of vision-and-language (V+L) tasks, including cross-modal retrieval, text-guided image retrieval, multi-modal classification, and image captioning. They differ drastically in each individual input/output format and dataset size. It has been common to design a task-specific model and fine-tune it independently from a pre-trained V+L model (e.g., CLIP). This results in parameter inefficiency and inability to exploit inter-task relatedness. To address such issues, we propose a novel FAshion-focused Multi-task Efficient learning method for Vision-and-Language tasks (FAME-ViL) in this work. Compared with existing approaches, FAME-ViL applies a single model for multiple heterogeneous fashion tasks, therefore being much more parameter-efficient. It is enabled by two novel components: (1) a task-versatile architecture with cross-attention adapters and task-specific adapters integrated into a unified V+L model, and (2) a stable and effective multi-task training strategy that supports learning from heterogeneous data and prevents negative transfer. Extensive experiments on four fashion tasks show that our FAME-ViL can save 61.5% of parameters over alternatives, while significantly outperforming the conventional independently trained single-task models. Code is available at https://github.com/BrandonHanx/FAME-ViL. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The objective of this paper is an automatic Audio Description (AD) model that ingests movies and outputs AD in text form. Generating high-quality movie AD is challenging due to the dependency of the descriptions on context, and the limited amount of training data available. In this work, we leverage the power of pretrained foundation models, such as GPT and CLIP, and only train a mapping network that bridges the two models for visually-conditioned text generation. In order to obtain high-quality AD, we make the following four contributions: (i) we incorporate context from the movie clip, AD from previous clips, as well as the subtitles; (ii) we address the lack of training data by pretraining on large-scale datasets, where visual or contextual information is unavailable, e.g. text-only AD without movies or visual captioning datasets without context; (iii) we improve on the currently available AD datasets, by removing label noise in the MAD dataset, and adding character naming information; and (iv) we obtain strong results on the movie AD task compared with previous methods. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recent works have shown that unstructured text (documents) from online sources can serve as useful auxiliary information for zero-shot image classification. However, these methods require access to a high-quality source like Wikipedia and are limited to a single source of information. Large Language Models (LLM) trained on web-scale text show impressive abilities to repurpose their learned knowledge for a multitude of tasks. In this work, we provide a novel perspective on using an LLM to provide text supervision for a zero-shot image classification model. The LLM is provided with a few text descriptions from different annotators as examples. The LLM is conditioned on these examples to generate multiple text descriptions for each class (referred to as views). Our proposed model, I2MVFormer, learns multi-view semantic embeddings for zero-shot image classification with these class views. We show that each text view of a class provides complementary information allowing a model to learn a highly discriminative class embedding. Moreover, we show that I2MVFormer is better at consuming the multi-view text supervision from LLM compared to baseline models. I2MVFormer establishes a new state-of-the-art on three public benchmark datasets for zero-shot image classification with unsupervised semantic embeddings. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 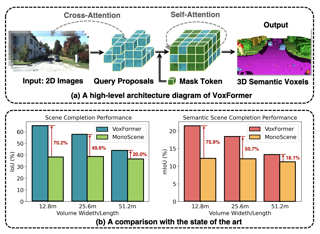
Humans can easily imagine the complete 3D geometry of occluded objects and scenes. This appealing ability is vital for recognition and understanding. To enable such capability in AI systems, we propose VoxFormer, a Transformer-based semantic scene completion framework that can output complete 3D volumetric semantics from only 2D images. Our framework adopts a two-stage design where we start from a sparse set of visible and occupied voxel queries from depth estimation, followed by a densification stage that generates dense 3D voxels from the sparse ones. A key idea of this design is that the visual features on 2D images correspond only to the visible scene structures rather than the occluded or empty spaces. Therefore, starting with the featurization and prediction of the visible structures is more reliable. Once we obtain the set of sparse queries, we apply a masked autoencoder design to propagate the information to all the voxels by self-attention. Experiments on SemanticKITTI show that VoxFormer outperforms the state of the art with a relative improvement of 20.0% in geometry and 18.1% in semantics and reduces GPU memory during training to less than 16GB. Our code is available on https://github.com/NVlabs/VoxFormer. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 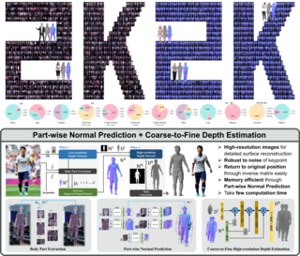
High-quality 3D human body reconstruction requires high-fidelity and large-scale training data and appropriate network design that effectively exploits the high-resolution input images. To tackle these problems, we propose a simple yet effective 3D human digitization method called 2K2K, which constructs a large-scale 2K human dataset and infers 3D human models from 2K resolution images. The proposed method separately recovers the global shape of a human and its details. The low-resolution depth network predicts the global structure from a low-resolution image, and the part-wise image-to-normal network predicts the details of the 3D human body structure. The high-resolution depth network merges the global 3D shape and the detailed structures to infer the high-resolution front and back side depth maps. Finally, an off-the-shelf mesh generator reconstructs the full 3D human model, which are available at https://github.com/SangHunHan92/2K2K. In addition, we also provide 2,050 3D human models, including texture maps, 3D joints, and SMPL parameters for research purposes. In experiments, we demonstrate competitive performance over the recent works on various datasets. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 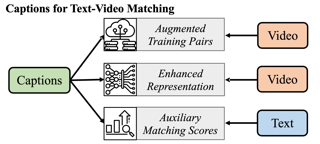
Most existing text-video retrieval methods focus on cross-modal matching between the visual content of videos and textual query sentences. However, in real-world scenarios, online videos are often accompanied by relevant text information such as titles, tags, and even subtitles, which can be utilized to match textual queries. This insight has motivated us to propose a novel approach to text-video retrieval, where we directly generate associated captions from videos using zero-shot video captioning with knowledge from web-scale pre-trained models (e.g., CLIP and GPT-2). Given the generated captions, a natural question arises: what benefits do they bring to text-video retrieval? To answer this, we introduce Cap4Video, a new framework that leverages captions in three ways: i) Input data: video-caption pairs can augment the training data. ii) Intermediate feature interaction: we perform cross-modal feature interaction between the video and caption to produce enhanced video representations. iii) Output score: the Query-Caption matching branch can complement the original Query-Video matching branch for text-video retrieval. We conduct comprehensive ablation studies to demonstrate the effectiveness of our approach. Without any post-processing, Cap4Video achieves state-of-the-art performance on four standard text-video retrieval benchmarks: MSR-VTT (51.4%), VATEX (66.6%), MSVD (51.8%), and DiDeMo (52.0%). The code is available at https://github.com/whwu95/Cap4Video. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present ESLAM, an efficient implicit neural representation method for Simultaneous Localization and Mapping (SLAM). ESLAM reads RGB-D frames with unknown camera poses in a sequential manner and incrementally reconstructs the scene representation while estimating the current camera position in the scene. We incorporate the latest advances in Neural Radiance Fields (NeRF) into a SLAM system, resulting in an efficient and accurate dense visual SLAM method. Our scene representation consists of multi-scale axis-aligned perpendicular feature planes and shallow decoders that, for each point in the continuous space, decode the interpolated features into Truncated Signed Distance Field (TSDF) and RGB values. Our extensive experiments on three standard datasets, Replica, ScanNet, and TUM RGB-D show that ESLAM improves the accuracy of 3D reconstruction and camera localization of state-of-the-art dense visual SLAM methods by more than 50%, while it runs up to 10 times faster and does not require any pre-training. Project page: https://www.idiap.ch/paper/eslam |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Category-agnostic pose estimation (CAPE) aims to predict keypoints for arbitrary categories given support images with keypoint annotations. Existing approaches match the keypoints across the image for localization. However, such a one-stage matching paradigm shows inferior accuracy: the prediction heavily relies on the matching results, which can be noisy due to the open set nature in CAPE. For example, two mirror-symmetric keypoints (e.g., left and right eyes) in the query image can both trigger high similarity on certain support keypoints (eyes), which leads to duplicated or opposite predictions. To calibrate the inaccurate matching results, we introduce a two-stage framework, where matched keypoints from the first stage are viewed as similarity-aware position proposals. Then, the model learns to fetch relevant features to correct the initial proposals in the second stage. We instantiate the framework with a transformer model tailored for CAPE. The transformer encoder incorporates specific designs to improve the representation and similarity modeling in the first matching stage. In the second stage, similarity-aware proposals are packed as queries in the decoder for refinement via cross-attention. Our method surpasses the previous best approach by large margins on CAPE benchmark MP-100 on both accuracy and efficiency. Code available at https://github.com/flyinglynx/CapeFormer |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Establishing pixel-level matches between image pairs is vital for a variety of computer vision applications. However, achieving robust image matching remains challenging because CNN extracted descriptors usually lack discriminative ability in texture-less regions and keypoint detectors are only good at identifying keypoints with a specific level of structure. To deal with these issues, a novel image matching method is proposed by Jointly Learning Hierarchical Detectors and Contextual Descriptors via Agent-based Transformers (D2Former), including a contextual feature descriptor learning (CFDL) module and a hierarchical keypoint detector learning (HKDL) module. The proposed D2Former enjoys several merits. First, the proposed CFDL module can model long-range contexts efficiently and effectively with the aid of designed descriptor agents. Second, the HKDL module can generate keypoint detectors in a hierarchical way, which is helpful for detecting keypoints with diverse levels of structures. Extensive experimental results on four challenging benchmarks show that our proposed method significantly outperforms state-of-the-art image matching methods. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Visual Question Answering (VQA) models often perform poorly on out-of-distribution data and struggle on domain generalization. Due to the multi-modal nature of this task, multiple factors of variation are intertwined, making generalization difficult to analyze. This motivates us to introduce a virtual benchmark, Super-CLEVR, where different factors in VQA domain shifts can be isolated in order that their effects can be studied independently. Four factors are considered: visual complexity, question redundancy, concept distribution and concept compositionality. With controllably generated data, Super-CLEVR enables us to test VQA methods in situations where the test data differs from the training data along each of these axes. We study four existing methods, including two neural symbolic methods NSCL and NSVQA, and two non-symbolic methods FiLM and mDETR; and our proposed method, probabilistic NSVQA (P-NSVQA), which extends NSVQA with uncertainty reasoning. P-NSVQA outperforms other methods on three of the four domain shift factors. Our results suggest that disentangling reasoning and perception, combined with probabilistic uncertainty, form a strong VQA model that is more robust to domain shifts. The dataset and code are released at https://github.com/Lizw14/Super-CLEVR. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
This paper presents a 3D diffusion model that automatically generates 3D digital avatars represented as neural radiance fields (NeRFs). A significant challenge for 3D diffusion is that the memory and processing costs are prohibitive for producing high-quality results with rich details. To tackle this problem, we propose the roll-out diffusion network (RODIN), which takes a 3D NeRF model represented as multiple 2D feature maps and rolls out them onto a single 2D feature plane within which we perform 3D-aware diffusion. The RODIN model brings much-needed computational efficiency while preserving the integrity of 3D diffusion by using 3D-aware convolution that attends to projected features in the 2D plane according to their original relationships in 3D. We also use latent conditioning to orchestrate the feature generation with global coherence, leading to high-fidelity avatars and enabling semantic editing based on text prompts. Finally, we use hierarchical synthesis to further enhance details. The 3D avatars generated by our model compare favorably with those produced by existing techniques. We can generate highly detailed avatars with realistic hairstyles and facial hair. We also demonstrate 3D avatar generation from image or text, as well as text-guided editability. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Coordinate-based implicit neural networks, or neural fields, have emerged as useful representations of shape and appearance in 3D computer vision. Despite advances however, it remains challenging to build neural fields for categories of objects without datasets like ShapeNet that provide “canonicalized” object instances that are consistently aligned for their 3D position and orientation (pose). We present Canonical Field Network (CaFi-Net), a self-supervised method to canonicalize the 3D pose of instances from an object category represented as neural fields, specifically neural radiance fields (NeRFs). CaFi-Net directly learns from continuous and noisy radiance fields using a Siamese network architecture that is designed to extract equivariant field features for category-level canonicalization. During inference, our method takes pre-trained neural radiance fields of novel object instances at arbitrary 3D pose, and estimates a canonical field with consistent 3D pose across the entire category. Extensive experiments on a new dataset of 1300 NeRF models across 13 object categories show that our method matches or exceeds the performance of 3D point cloud-based methods. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 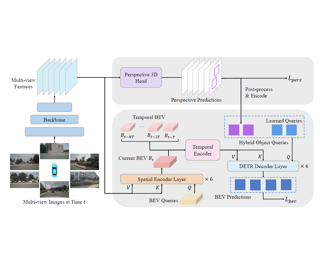
We present a novel bird’s-eye-view (BEV) detector with perspective supervision, which converges faster and better suits modern image backbones. Existing state-of-the-art BEV detectors are often tied to certain depth pre-trained backbones like VoVNet, hindering the synergy between booming image backbones and BEV detectors. To address this limitation, we prioritize easing the optimization of BEV detectors by introducing perspective space supervision. To this end, we propose a two-stage BEV detector, where proposals from the perspective head are fed into the bird’s-eye-view head for final predictions. To evaluate the effectiveness of our model, we conduct extensive ablation studies focusing on the form of supervision and the generality of the proposed detector. The proposed method is verified with a wide spectrum of traditional and modern image backbones and achieves new SoTA results on the large-scale nuScenes dataset. The code shall be released soon. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In this paper, we propose an end-to-end Retrieval-Augmented Visual Language Model (REVEAL) that learns to encode world knowledge into a large-scale memory, and to retrieve from it to answer knowledge-intensive queries. REVEAL consists of four key components: the memory, the encoder, the retriever and the generator. The large-scale memory encodes various sources of multimodal world knowledge (e.g. image-text pairs, question answering pairs, knowledge graph triplets, etc.) via a unified encoder. The retriever finds the most relevant knowledge entries in the memory, and the generator fuses the retrieved knowledge with the input query to produce the output. A key novelty in our approach is that the memory, encoder, retriever and generator are all pre-trained end-to-end on a massive amount of data. Furthermore, our approach can use a diverse set of multimodal knowledge sources, which is shown to result in significant gains. We show that REVEAL achieves state-of-the-art results on visual question answering and image captioning. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recent work leverages the expressive power of genera- tive adversarial networks (GANs) to generate labeled syn- thetic datasets. These dataset generation methods often require new annotations of synthetic images, which forces practitioners to seek out annotators, curate a set of synthetic images, and ensure the quality of generated labels. We in- troduce the HandsOff framework, a technique capable of producing an unlimited number of synthetic images and cor- responding labels after being trained on less than 50 pre- existing labeled images. Our framework avoids the practi- cal drawbacks of prior work by unifying the field of GAN in- version with dataset generation. We generate datasets with rich pixel-wise labels in multiple challenging domains such as faces, cars, full-body human poses, and urban driving scenes. Our method achieves state-of-the-art performance in semantic segmentation, keypoint detection, and depth es- timation compared to prior dataset generation approaches and transfer learning baselines. We additionally showcase its ability to address broad challenges in model develop- ment which stem from fixed, hand-annotated datasets, such as the long-tail problem in semantic segmentation. Project page: austinxu87.github.io/handsoff. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Learned image compression (LIC) methods have exhibited promising progress and superior rate-distortion performance compared with classical image compression standards. Most existing LIC methods are Convolutional Neural Networks-based (CNN-based) or Transformer-based, which have different advantages. Exploiting both advantages is a point worth exploring, which has two challenges: 1) how to effectively fuse the two methods? 2) how to achieve higher performance with a suitable complexity? In this paper, we propose an efficient parallel Transformer-CNN Mixture (TCM) block with a controllable complexity to incorporate the local modeling ability of CNN and the non-local modeling ability of transformers to improve the overall architecture of image compression models. Besides, inspired by the recent progress of entropy estimation models and attention modules, we propose a channel-wise entropy model with parameter-efficient swin-transformer-based attention (SWAtten) modules by using channel squeezing. Experimental results demonstrate our proposed method achieves state-of-the-art rate-distortion performances on three different resolution datasets (i.e., Kodak, Tecnick, CLIC Professional Validation) compared to existing LIC methods. The code is at https://github.com/jmliu206/LIC_TCM. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In this paper, we explore a novel model reusing task tailored for graph neural networks (GNNs), termed as “deep graph reprogramming”. We strive to reprogram a pre-trained GNN, without amending raw node features nor model parameters, to handle a bunch of cross-level downstream tasks in various domains. To this end, we propose an innovative Data Reprogramming paradigm alongside a Model Reprogramming paradigm. The former one aims to address the challenge of diversified graph feature dimensions for various tasks on the input side, while the latter alleviates the dilemma of fixed per-task-per-model behavior on the model side. For data reprogramming, we specifically devise an elaborated Meta-FeatPadding method to deal with heterogeneous input dimensions, and also develop a transductive Edge-Slimming as well as an inductive Meta-GraPadding approach for diverse homogenous samples. Meanwhile, for model reprogramming, we propose a novel task-adaptive Reprogrammable-Aggregator, to endow the frozen model with larger expressive capacities in handling cross-domain tasks. Experiments on fourteen datasets across node/graph classification/regression, 3D object recognition, and distributed action recognition, demonstrate that the proposed methods yield gratifying results, on par with those by re-training from scratch. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We propose a novel knowledge distillation framework for effectively teaching a sensorimotor student agent to drive from the supervision of a privileged teacher agent. Current distillation for sensorimotor agents methods tend to result in suboptimal learned driving behavior by the student, which we hypothesize is due to inherent differences between the input, modeling capacity, and optimization processes of the two agents. We develop a novel distillation scheme that can address these limitations and close the gap between the sensorimotor agent and its privileged teacher. Our key insight is to design a student which learns to align their input features with the teacher’s privileged Bird’s Eye View (BEV) space. The student then can benefit from direct supervision by the teacher over the internal representation learning. To scaffold the difficult sensorimotor learning task, the student model is optimized via a student-paced coaching mechanism with various auxiliary supervision. We further propose a high-capacity imitation learned privileged agent that surpasses prior privileged agents in CARLA and ensures the student learns safe driving behavior. Our proposed sensorimotor agent results in a robust image-based behavior cloning agent in CARLA, improving over current models by over 20.6% in driving score without requiring LiDAR, historical observations, ensemble of … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Video frame interpolation (VFI) is the task that synthesizes the intermediate frame given two consecutive frames. Most of the previous studies have focused on appropriate frame warping operations and refinement modules for the warped frames. These studies have been conducted on natural videos containing only continuous motions. However, many practical videos contain various unnatural objects with discontinuous motions such as logos, user interfaces and subtitles. We propose three techniques that can make the existing deep learning-based VFI architectures robust to these elements. First is a novel data augmentation strategy called figure-text mixing (FTM) which can make the models learn discontinuous motions during training stage without any extra dataset. Second, we propose a simple but effective module that predicts a map called discontinuity map (D-map), which densely distinguishes between areas of continuous and discontinuous motions. Lastly, we propose loss functions to give supervisions of the discontinuous motion areas which can be applied along with FTM and D-map. We additionally collect a special test benchmark called Graphical Discontinuous Motion (GDM) dataset consisting of some mobile games and chatting videos. Applied to the various state-of-the-art VFI networks, our method significantly improves the interpolation qualities on the videos from not only GDM dataset, but … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Real-world deployment of reliable object detectors is crucial for applications such as autonomous driving. However, general-purpose object detectors like Faster R-CNN are prone to providing overconfident predictions for outlier objects. Recent outlier-aware object detection approaches estimate the density of instance-wide features with class-conditional Gaussians and train on synthesized outlier features from their low-likelihood regions. However, this strategy does not guarantee that the synthesized outlier features will have a low likelihood according to the other class-conditional Gaussians. We propose a novel outlier-aware object detection framework that distinguishes outliers from inlier objects by learning the joint data distribution of all inlier classes with an invertible normalizing flow. The appropriate sampling of the flow model ensures that the synthesized outliers have a lower likelihood than inliers of all object classes, thereby modeling a better decision boundary between inlier and outlier objects. Our approach significantly outperforms the state-of-the-art for outlier-aware object detection on both image and video datasets. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Class-incremental semantic segmentation aims to incrementally learn new classes while maintaining the capability to segment old ones, and suffers catastrophic forgetting since the old-class labels are unavailable. Most existing methods are based on convolutional networks and prevent forgetting through knowledge distillation, which (1) need to add additional convolutional layers to predict new classes, and (2) ignore to distinguish different regions corresponding to old and new classes during knowledge distillation and roughly distill all the features, thus limiting the learning of new classes. Based on the above observations, we propose a new transformer framework for class-incremental semantic segmentation, dubbed Incrementer, which only needs to add new class tokens to the transformer decoder for new-class learning. Based on the Incrementer, we propose a new knowledge distillation scheme that focuses on the distillation in the old-class regions, which reduces the constraints of the old model on the new-class learning, thus improving the plasticity. Moreover, we propose a class deconfusion strategy to alleviate the overfitting to new classes and the confusion of similar classes. Our method is simple and effective, and extensive experiments show that our method outperforms the SOTAs by a large margin (5~15 absolute points boosts on both Pascal VOC and ADE20k). … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Existing semantic segmentation approaches are often limited by costly pixel-wise annotations and predefined classes. In this work, we present CLIP-S^4 that leverages self-supervised pixel representation learning and vision-language models to enable various semantic segmentation tasks (e.g., unsupervised, transfer learning, language-driven segmentation) without any human annotations and unknown class information. We first learn pixel embeddings with pixel-segment contrastive learning from different augmented views of images. To further improve the pixel embeddings and enable language-driven semantic segmentation, we design two types of consistency guided by vision-language models: 1) embedding consistency, aligning our pixel embeddings to the joint feature space of a pre-trained vision-language model, CLIP; and 2) semantic consistency, forcing our model to make the same predictions as CLIP over a set of carefully designed target classes with both known and unknown prototypes. Thus, CLIP-S^4 enables a new task of class-free semantic segmentation where no unknown class information is needed during training. As a result, our approach shows consistent and substantial performance improvement over four popular benchmarks compared with the state-of-the-art unsupervised and language-driven semantic segmentation methods. More importantly, our method outperforms these methods on unknown class recognition by a large margin. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 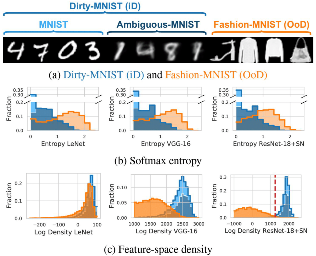
Reliable uncertainty from deterministic single-forward pass models is sought after because conventional methods of uncertainty quantification are computationally expensive. We take two complex single-forward-pass uncertainty approaches, DUQ and SNGP, and examine whether they mainly rely on a well-regularized feature space. Crucially, without using their more complex methods for estimating uncertainty, we find that a single softmax neural net with such a regularized feature-space, achieved via residual connections and spectral normalization, outperforms DUQ and SNGP’s epistemic uncertainty predictions using simple Gaussian Discriminant Analysis post-training as a separate feature-space density estimator---without fine-tuning on OoD data, feature ensembling, or input pre-procressing. Our conceptually simple Deep Deterministic Uncertainty (DDU) baseline can also be used to disentangle aleatoric and epistemic uncertainty and performs as well as Deep Ensembles, the state-of-the art for uncertainty prediction, on several OoD benchmarks (CIFAR-10/100 vs SVHN/Tiny-ImageNet, ImageNet vs ImageNet-O), active learning settings across different model architectures, as well as in large scale vision tasks like semantic segmentation, while being computationally cheaper. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 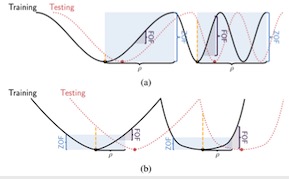
Recently, flat minima are proven to be effective for improving generalization and sharpness-aware minimization (SAM) achieves state-of-the-art performance. Yet the current definition of flatness discussed in SAM and its follow-ups are limited to the zeroth-order flatness (i.e., the worst-case loss within a perturbation radius). We show that the zeroth-order flatness can be insufficient to discriminate minima with low generalization error from those with high generalization error both when there is a single minimum or multiple minima within the given perturbation radius. Thus we present first-order flatness, a stronger measure of flatness focusing on the maximal gradient norm within a perturbation radius which bounds both the maximal eigenvalue of Hessian at local minima and the regularization function of SAM. We also present a novel training procedure named Gradient norm Aware Minimization (GAM) to seek minima with uniformly small curvature across all directions. Experimental results show that GAM improves the generalization of models trained with current optimizers such as SGD and AdamW on various datasets and networks. Furthermore, we show that GAM can help SAM find flatter minima and achieve better generalization. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Image-text contrastive learning models such as CLIP have demonstrated strong task transfer ability. The high generality and usability of these visual models is achieved via a web-scale data collection process to ensure broad concept coverage, followed by expensive pre-training to feed all the knowledge into model weights. Alternatively, we propose REACT, REtrieval-Augmented CusTomization, a framework to acquire the relevant web knowledge to build customized visual models for target domains. We retrieve the most relevant image-text pairs (~3% of CLIP pre-training data) from the web-scale database as external knowledge and propose to customize the model by only training new modularized blocks while freezing all the original weights. The effectiveness of REACT is demonstrated via extensive experiments on classification, retrieval, detection and segmentation tasks, including zero, few, and full-shot settings. Particularly, on the zero-shot classification task, compared with CLIP, it achieves up to 5.4% improvement on ImageNet and 3.7% on the ELEVATER benchmark (20 datasets). |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We argue that there are many notions of ‘similarity’ and that models, like humans, should be able to adapt to these dynamically. This contrasts with most representation learning methods, supervised or self-supervised, which learn a fixed embedding function and hence implicitly assume a single notion of similarity. For instance, models trained on ImageNet are biased towards object categories, while a user might prefer the model to focus on colors, textures or specific elements in the scene. In this paper, we propose the GeneCIS (‘genesis’) benchmark, which measures models’ ability to adapt to a range of similarity conditions. Extending prior work, our benchmark is designed for zero-shot evaluation only, and hence considers an open-set of similarity conditions. We find that baselines from powerful CLIP models struggle on GeneCIS and that performance on the benchmark is only weakly correlated with ImageNet accuracy, suggesting that simply scaling existing methods is not fruitful. We further propose a simple, scalable solution based on automatically mining information from existing image-caption datasets. We find our method offers a substantial boost over the baselines on GeneCIS, and further improves zero-shot performance on related image retrieval benchmarks. In fact, though evaluated zero-shot, our model surpasses state-of-the-art supervised models on … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Camouflaged Instance Segmentation (CIS) aims at predicting the instance-level masks of camouflaged objects, which are usually the animals in the wild adapting their appearance to match the surroundings. Previous instance segmentation methods perform poorly on this task as they are easily disturbed by the deceptive camouflage. To address these challenges, we propose a novel De-camouflaging Network (DCNet) including a pixel-level camouflage decoupling module and an instance-level camouflage suppression module. The proposed DCNet enjoys several merits. First, the pixel-level camouflage decoupling module can extract camouflage characteristics based on the Fourier transformation. Then a difference attention mechanism is proposed to eliminate the camouflage characteristics while reserving target object characteristics in the pixel feature. Second, the instance-level camouflage suppression module can aggregate rich instance information from pixels by use of instance prototypes. To mitigate the effect of background noise during segmentation, we introduce some reliable reference points to build a more robust similarity measurement. With the aid of these two modules, our DCNet can effectively model de-camouflaging and achieve accurate segmentation for camouflaged instances. Extensive experimental results on two benchmarks demonstrate that our DCNet performs favorably against state-of-the-art CIS methods, e.g., with more than 5% performance gains on COD10K and NC4K datasets in … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We propose the first framework to learn control policies for vision-based human-to-robot handovers, a critical task for human-robot interaction. While research in Embodied AI has made significant progress in training robot agents in simulated environments, interacting with humans remains challenging due to the difficulties of simulating humans. Fortunately, recent research has developed realistic simulated environments for human-to-robot handovers. Leveraging this result, we introduce a method that is trained with a human-in-the-loop via a two-stage teacher-student framework that uses motion and grasp planning, reinforcement learning, and self-supervision. We show significant performance gains over baselines on a simulation benchmark, sim-to-sim transfer and sim-to-real transfer. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present ImageBind, an approach to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. We show that all combinations of paired data are not necessary to train such a joint embedding, and only image-paired data is sufficient to bind the modalities together. ImageBind can leverage recent large scale vision-language models, and extends their zero-shot capabilities to new modalities just by using their natural pairing with images. It enables novel emergent applications ‘out-of-the-box’ including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation. The emergent capabilities improve with the strength of the image encoder and we set a new state-of-the-art on emergent zero-shot recognition tasks across modalities, outperforming specialist supervised models. Finally, we show strong few-shot recognition results outperforming prior work, and that ImageBind serves as a new way to evaluate vision models for visual and non-visual tasks. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 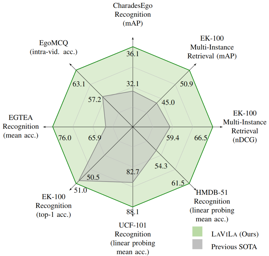
We introduce LAVILA, a new approach to learning video-language representations by leveraging Large Language Models (LLMs). We repurpose pre-trained LLMs to be conditioned on visual input, and finetune them to create automatic video narrators. Our auto-generated narrations offer a number of advantages, including dense coverage of long videos, better temporal synchronization of the visual information and text, and much higher diversity of text. The video-language embedding learned contrastively with these narrations outperforms the previous state-of-the-art on multiple first-person and third-person video tasks, both in zero-shot and finetuned setups. Most notably, LAVILA obtains an absolute gain of 10.1% on EGTEA classification and 5.9% Epic-Kitchens-100 multi-instance retrieval benchmarks. Furthermore, LAVILA trained with only half the narrations from the Ego4D dataset outperforms models trained on the full set, and shows positive scaling behavior on increasing pre-training data and model size. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Densely annotating LiDAR point clouds is costly, which often restrains the scalability of fully-supervised learning methods. In this work, we study the underexplored semi-supervised learning (SSL) in LiDAR semantic segmentation. Our core idea is to leverage the strong spatial cues of LiDAR point clouds to better exploit unlabeled data. We propose LaserMix to mix laser beams from different LiDAR scans and then encourage the model to make consistent and confident predictions before and after mixing. Our framework has three appealing properties. 1) Generic: LaserMix is agnostic to LiDAR representations (e.g., range view and voxel), and hence our SSL framework can be universally applied. 2) Statistically grounded: We provide a detailed analysis to theoretically explain the applicability of the proposed framework. 3) Effective: Comprehensive experimental analysis on popular LiDAR segmentation datasets (nuScenes, SemanticKITTI, and ScribbleKITTI) demonstrates our effectiveness and superiority. Notably, we achieve competitive results over fully-supervised counterparts with 2x to 5x fewer labels and improve the supervised-only baseline significantly by relatively 10.8%. We hope this concise yet high-performing framework could facilitate future research in semi-supervised LiDAR segmentation. Code is publicly available. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Lighting effects such as shadows or reflections are key in making synthetic images realistic and visually appealing. To generate such effects, traditional computer graphics uses a physically-based renderer along with 3D geometry. To compensate for the lack of geometry in 2D Image compositing, recent deep learning-based approaches introduced a pixel height representation to generate soft shadows and reflections. However, the lack of geometry limits the quality of the generated soft shadows and constrains reflections to pure specular ones. We introduce PixHt-Lab, a system leveraging an explicit mapping from pixel height representation to 3D space. Using this mapping, PixHt-Lab reconstructs both the cutout and background geometry and renders realistic, diverse, lighting effects for image compositing. Given a surface with physically-based materials, we can render reflections with varying glossiness. To generate more realistic soft shadows, we further propose to use 3D-aware buffer channels to guide a neural renderer. Both quantitative and qualitative evaluations demonstrate that PixHt-Lab significantly improves soft shadow generation. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 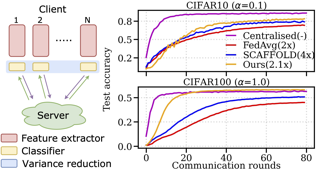
Data heterogeneity across clients is a key challenge in federated learning. Prior works address this by either aligning client and server models or using control variates to correct client model drift. Although these methods achieve fast convergence in convex or simple non-convex problems, the performance in over-parameterized models such as deep neural networks is lacking. In this paper, we first revisit the widely used FedAvg algorithm in a deep neural network to understand how data heterogeneity influences the gradient updates across the neural network layers. We observe that while the feature extraction layers are learned efficiently by FedAvg, the substantial diversity of the final classification layers across clients impedes the performance. Motivated by this, we propose to correct model drift by variance reduction only on the final layers. We demonstrate that this significantly outperforms existing benchmarks at a similar or lower communication cost. We furthermore provide proof for the convergence rate of our algorithm. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
This work addresses the problem of anonymizing the identity of faces in a dataset of images, such that the privacy of those depicted is not violated, while at the same time the dataset is useful for downstream task such as for training machine learning models. To the best of our knowledge, we are the first to explicitly address this issue and deal with two major drawbacks of the existing state-of-the-art approaches, namely that they (i) require the costly training of additional, purpose-trained neural networks, and/or (ii) fail to retain the facial attributes of the original images in the anonymized counterparts, the preservation of which is of paramount importance for their use in downstream tasks. We accordingly present a task-agnostic anonymization procedure that directly optimises the images’ latent representation in the latent space of a pre-trained GAN. By optimizing the latent codes directly, we ensure both that the identity is of a desired distance away from the original (with an identity obfuscation loss), whilst preserving the facial attributes (using a novel feature-matching loss in FaRL’s deep feature space). We demonstrate through a series of both qualitative and quantitative experiments that our method is capable of anonymizing the identity of the images … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Gait recognition is one of the most critical long-distance identification technologies and increasingly gains popularity in both research and industry communities. Despite the significant progress made in indoor datasets, much evidence shows that gait recognition techniques perform poorly in the wild. More importantly, we also find that some conclusions drawn from indoor datasets cannot be generalized to real applications. Therefore, the primary goal of this paper is to present a comprehensive benchmark study for better practicality rather than only a particular model for better performance. To this end, we first develop a flexible and efficient gait recognition codebase named OpenGait. Based on OpenGait, we deeply revisit the recent development of gait recognition by re-conducting the ablative experiments. Encouragingly,we detect some unperfect parts of certain prior woks, as well as new insights. Inspired by these discoveries, we develop a structurally simple, empirically powerful, and practically robust baseline model, GaitBase. Experimentally, we comprehensively compare GaitBase with many current gait recognition methods on multiple public datasets, and the results reflect that GaitBase achieves significantly strong performance in most cases regardless of indoor or outdoor situations. Code is available at https://github.com/ShiqiYu/OpenGait. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In the field of 3D object detection for autonomous driving, the sensor portfolio including multi-modality and single-modality is diverse and complex. Since the multi-modal methods have system complexity while the accuracy of single-modal ones is relatively low, how to make a tradeoff between them is difficult. In this work, we propose a universal cross-modality knowledge distillation framework (UniDistill) to improve the performance of single-modality detectors. Specifically, during training, UniDistill projects the features of both the teacher and the student detector into Bird’s-Eye-View (BEV), which is a friendly representation for different modalities. Then, three distillation losses are calculated to sparsely align the foreground features, helping the student learn from the teacher without introducing additional cost during inference. Taking advantage of the similar detection paradigm of different detectors in BEV, UniDistill easily supports LiDAR-to-camera, camera-to-LiDAR, fusion-to-LiDAR and fusion-to-camera distillation paths. Furthermore, the three distillation losses can filter the effect of misaligned background information and balance between objects of different sizes, improving the distillation effectiveness. Extensive experiments on nuScenes demonstrate that UniDistill effectively improves the mAP and NDS of student detectors by 2.0%~3.2%. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Active domain adaptation (ADA) aims to improve the model adaptation performance by incorporating the active learning (AL) techniques to label a maximally-informative subset of target samples. Conventional AL methods do not consider the existence of domain shift, and hence, fail to identify the truly valuable samples in the context of domain adaptation. To accommodate active learning and domain adaption, the two naturally different tasks, in a collaborative framework, we advocate that a customized learning strategy for the target data is the key to the success of ADA solutions. We present Divide-and-Adapt (DiaNA), a new ADA framework that partitions the target instances into four categories with stratified transferable properties. With a novel data subdivision protocol based on uncertainty and domainness, DiaNA can accurately recognize the most gainful samples. While sending the informative instances for annotation, DiaNA employs tailored learning strategies for the remaining categories. Furthermore, we propose an informativeness score that unifies the data partitioning criteria. This enables the use of a Gaussian mixture model (GMM) to automatically sample unlabeled data into the proposed four categories. Thanks to the “divide-and-adapt” spirit, DiaNA can handle data with large variations of domain gap. In addition, we show that DiaNA can generalize to different … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present an effective and efficient method that explores the properties of Transformers in the frequency domain for high-quality image deblurring. Our method is motivated by the convolution theorem that the correlation or convolution of two signals in the spatial domain is equivalent to an element-wise product of them in the frequency domain. This inspires us to develop an efficient frequency domain-based self-attention solver (FSAS) to estimate the scaled dot-product attention by an element-wise product operation instead of the matrix multiplication in the spatial domain. In addition, we note that simply using the naive feed-forward network (FFN) in Transformers does not generate good deblurred results. To overcome this problem, we propose a simple yet effective discriminative frequency domain-based FFN (DFFN), where we introduce a gated mechanism in the FFN based on the Joint Photographic Experts Group (JPEG) compression algorithm to discriminatively determine which low- and high-frequency information of the features should be preserved for latent clear image restoration. We formulate the proposed FSAS and DFFN into an asymmetrical network based on an encoder and decoder architecture, where the FSAS is only used in the decoder module for better image deblurring. Experimental results show that the proposed method performs favorably against … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Learning-based visual relocalizers exhibit leading pose accuracy, but require hours or days of training. Since training needs to happen on each new scene again, long training times make learning-based relocalization impractical for most applications, despite its promise of high accuracy. In this paper we show how such a system can actually achieve the same accuracy in less than 5 minutes. We start from the obvious: a relocalization network can be split in a scene-agnostic feature backbone, and a scene-specific prediction head. Less obvious: using an MLP prediction head allows us to optimize across thousands of view points simultaneously in each single training iteration. This leads to stable and extremely fast convergence. Furthermore, we substitute effective but slow end-to-end training using a robust pose solver with a curriculum over a reprojection loss. Our approach does not require privileged knowledge, such a depth maps or a 3D model, for speedy training. Overall, our approach is up to 300x faster in mapping than state-of-the-art scene coordinate regression, while keeping accuracy on par. Code is available: https://nianticlabs.github.io/ace |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Subtle periodic signals such as blood volume pulse and respiration can be extracted from RGB video, enabling noncontact health monitoring at low cost. Advancements in remote pulse estimation -- or remote photoplethysmography (rPPG) -- are currently driven by deep learning solutions. However, modern approaches are trained and evaluated on benchmark datasets with ground truth from contact-PPG sensors. We present the first non-contrastive unsupervised learning framework for signal regression to mitigate the need for labelled video data. With minimal assumptions of periodicity and finite bandwidth, our approach discovers the blood volume pulse directly from unlabelled videos. We find that encouraging sparse power spectra within normal physiological bandlimits and variance over batches of power spectra is sufficient for learning visual features of periodic signals. We perform the first experiments utilizing unlabelled video data not specifically created for rPPG to train robust pulse rate estimators. Given the limited inductive biases and impressive empirical results, the approach is theoretically capable of discovering other periodic signals from video, enabling multiple physiological measurements without the need for ground truth signals. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 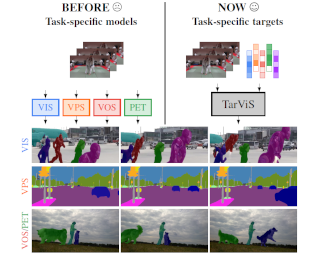
The general domain of video segmentation is currently fragmented into different tasks spanning multiple benchmarks. Despite rapid progress in the state-of-the-art, current methods are overwhelmingly task-specific and cannot conceptually generalize to other tasks. Inspired by recent approaches with multi-task capability, we propose TarViS: a novel, unified network architecture that can be applied to any task that requires segmenting a set of arbitrarily defined ‘targets’ in video. Our approach is flexible with respect to how tasks define these targets, since it models the latter as abstract ‘queries’ which are then used to predict pixel-precise target masks. A single TarViS model can be trained jointly on a collection of datasets spanning different tasks, and can hot-swap between tasks during inference without any task-specific retraining. To demonstrate its effectiveness, we apply TarViS to four different tasks, namely Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), Video Object Segmentation (VOS) and Point Exemplar-guided Tracking (PET). Our unified, jointly trained model achieves state-of-the-art performance on 5/7 benchmarks spanning these four tasks, and competitive performance on the remaining two. Code and model weights are available at: https://github.com/Ali2500/TarViS |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Sign language recognition (SLR) is a weakly supervised task that annotates sign videos as textual glosses. Recent studies show that insufficient training caused by the lack of large-scale available sign datasets becomes the main bottleneck for SLR. Most SLR works thereby adopt pretrained visual modules and develop two mainstream solutions. The multi-stream architectures extend multi-cue visual features, yielding the current SOTA performances but requiring complex designs and might introduce potential noise. Alternatively, the advanced single-cue SLR frameworks using explicit cross-modal alignment between visual and textual modalities are simple and effective, potentially competitive with the multi-cue framework. In this work, we propose a novel contrastive visual-textual transformation for SLR, CVT-SLR, to fully explore the pretrained knowledge of both the visual and language modalities. Based on the single-cue cross-modal alignment framework, we propose a variational autoencoder (VAE) for pretrained contextual knowledge while introducing the complete pretrained language module. The VAE implicitly aligns visual and textual modalities while benefiting from pretrained contextual knowledge as the traditional contextual module. Meanwhile, a contrastive cross-modal alignment algorithm is designed to explicitly enhance the consistency constraints. Extensive experiments on public datasets (PHOENIX-2014 and PHOENIX-2014T) demonstrate that our proposed CVT-SLR consistently outperforms existing single-cue methods and even outperforms … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recent progress in diffusion models has revolutionized the popular technology of text-to-image generation. While existing approaches could produce photorealistic high-resolution images with text conditions, there are still several open problems to be solved, which limits the further improvement of image fidelity and text relevancy. In this paper, we propose ERNIE-ViLG 2.0, a large-scale Chinese text-to-image diffusion model, to progressively upgrade the quality of generated images by: (1) incorporating fine-grained textual and visual knowledge of key elements in the scene, and (2) utilizing different denoising experts at different denoising stages. With the proposed mechanisms, ERNIE-ViLG 2.0 not only achieves a new state-of-the-art on MS-COCO with zero-shot FID-30k score of 6.75, but also significantly outperforms recent models in terms of image fidelity and image-text alignment, with side-by-side human evaluation on the bilingual prompt set ViLG-300. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We introduce MarginMatch, a new SSL approach combining consistency regularization and pseudo-labeling, with its main novelty arising from the use of unlabeled data training dynamics to measure pseudo-label quality. Instead of using only the model’s confidence on an unlabeled example at an arbitrary iteration to decide if the example should be masked or not, MarginMatch also analyzes the behavior of the model on the pseudo-labeled examples as the training progresses, ensuring low fluctuations in the model’s predictions from one iteration to another. MarginMatch brings substantial improvements on four vision benchmarks in low data regimes and on two large-scale datasets, emphasizing the importance of enforcing high-quality pseudo-labels. Notably, we obtain an improvement in error rate over the state-of-the-art of 3.25% on CIFAR-100 with only 25 examples per class and of 4.19% on STL-10 using as few as 4 examples per class. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present a novel method for reconstructing a 3D implicit surface from a large-scale, sparse, and noisy point cloud. Our approach builds upon the recently introduced Neural Kernel Fields (NKF) representation. It enjoys similar generalization capabilities to NKF, while simultaneously addressing its main limitations: (a) We can scale to large scenes through compactly supported kernel functions, which enable the use of memory-efficient sparse linear solvers. (b) We are robust to noise, through a gradient fitting solve. (c) We minimize training requirements, enabling us to learn from any dataset of dense oriented points, and even mix training data consisting of objects and scenes at different scales. Our method is capable of reconstructing millions of points in a few seconds, and handling very large scenes in an out-of-core fashion. We achieve state-of-the-art results on reconstruction benchmarks consisting of single objects (ShapeNet, ABC), indoor scenes (ScanNet, Matterport3D), and outdoor scenes (CARLA, Waymo). |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The recent detection transformer (DETR) has advanced object detection, but its application on resource-constrained devices requires massive computation and memory resources. Quantization stands out as a solution by representing the network in low-bit parameters and operations. However, there is a significant performance drop when performing low-bit quantized DETR (Q-DETR) with existing quantization methods. We find that the bottlenecks of Q-DETR come from the query information distortion through our empirical analyses. This paper addresses this problem based on a distribution rectification distillation (DRD). We formulate our DRD as a bi-level optimization problem, which can be derived by generalizing the information bottleneck (IB) principle to the learning of Q-DETR. At the inner level, we conduct a distribution alignment for the queries to maximize the self-information entropy. At the upper level, we introduce a new foreground-aware query matching scheme to effectively transfer the teacher information to distillation-desired features to minimize the conditional information entropy. Extensive experimental results show that our method performs much better than prior arts. For example, the 4-bit Q-DETR can theoretically accelerate DETR with ResNet-50 backbone by 6.6x and achieve 39.4% AP, with only 2.6% performance gaps than its real-valued counterpart on the COCO dataset. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 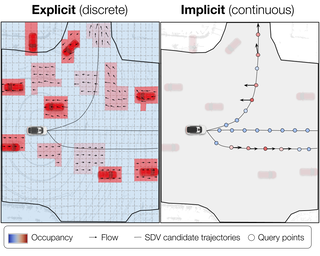
A self-driving vehicle (SDV) must be able to perceive its surroundings and predict the future behavior of other traffic participants. Existing works either perform object detection followed by trajectory forecasting of the detected objects, or predict dense occupancy and flow grids for the whole scene. The former poses a safety concern as the number of detections needs to be kept low for efficiency reasons, sacrificing object recall. The latter is computationally expensive due to the high-dimensionality of the output grid, and suffers from the limited receptive field inherent to fully convolutional networks. Furthermore, both approaches employ many computational resources predicting areas or objects that might never be queried by the motion planner. This motivates our unified approach to perception and future prediction that implicitly represents occupancy and flow over time with a single neural network. Our method avoids unnecessary computation, as it can be directly queried by the motion planner at continuous spatio-temporal locations. Moreover, we design an architecture that overcomes the limited receptive field of previous explicit occupancy prediction methods by adding an efficient yet effective global attention mechanism. Through extensive experiments in both urban and highway settings, we demonstrate that our implicit model outperforms the current state-of-the-art. For … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recently, Masked Image Modeling (MIM) achieves great success in self-supervised visual recognition. However, as a reconstruction-based framework, it is still an open question to understand how MIM works, since MIM appears very different from previous well-studied siamese approaches such as contrastive learning. In this paper, we propose a new viewpoint: MIM implicitly learns occlusion-invariant features, which is analogous to other siamese methods while the latter learns other invariance. By relaxing MIM formulation into an equivalent siamese form, MIM methods can be interpreted in a unified framework with conventional methods, among which only a) data transformations, i.e. what invariance to learn, and b) similarity measurements are different. Furthermore, taking MAE (He et al., 2021) as a representative example of MIM, we empirically find the success of MIM models relates a little to the choice of similarity functions, but the learned occlusion invariant feature introduced by masked image -- it turns out to be a favored initialization for vision transformers, even though the learned feature could be less semantic. We hope our findings could inspire researchers to develop more powerful self-supervised methods in computer vision community. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We introduce an interferometric technique for passive time-of-flight imaging and depth sensing at micrometer axial resolutions. Our technique uses a full-field Michelson interferometer, modified to use sunlight as the only light source. The large spectral bandwidth of sunlight makes it possible to acquire micrometer-resolution time-resolved scene responses, through a simple axial scanning operation. Additionally, the angular bandwidth of sunlight makes it possible to capture time-of-flight measurements insensitive to indirect illumination effects, such as interreflections and subsurface scattering. We build an experimental prototype that we operate outdoors, under direct sunlight, and in adverse environment conditions such as machine vibrations and vehicle traffic. We use this prototype to demonstrate, for the first time, passive imaging capabilities such as micrometer-scale depth sensing robust to indirect illumination, direct-only imaging, and imaging through diffusers. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The self-supervised pretraining paradigm has achieved great success in skeleton-based action recognition. However, these methods treat the motion and static parts equally, and lack an adaptive design for different parts, which has a negative impact on the accuracy of action recognition. To realize the adaptive action modeling of both parts, we propose an Actionlet-Dependent Contrastive Learning method (ActCLR). The actionlet, defined as the discriminative subset of the human skeleton, effectively decomposes motion regions for better action modeling. In detail, by contrasting with the static anchor without motion, we extract the motion region of the skeleton data, which serves as the actionlet, in an unsupervised manner. Then, centering on actionlet, a motion-adaptive data transformation method is built. Different data transformations are applied to actionlet and non-actionlet regions to introduce more diversity while maintaining their own characteristics. Meanwhile, we propose a semantic-aware feature pooling method to build feature representations among motion and static regions in a distinguished manner. Extensive experiments on NTU RGB+D and PKUMMD show that the proposed method achieves remarkable action recognition performance. More visualization and quantitative experiments demonstrate the effectiveness of our method. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs. Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information. As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs. The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K. It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] Motion forecasting is a key module in an autonomous driving system. Due to the heterogeneous nature of multi-sourced input, multimodality in agent behavior, and low latency required by onboard deployment, this task is notoriously challenging. To cope with these difficulties, this paper proposes a novel agent-centric model with anchor-informed proposals for efficient multimodal motion forecasting. We design a modality-agnostic strategy to concisely encode the complex input in a unified manner. We generate diverse proposals, fused with anchors bearing goal-oriented context, to induce multimodal prediction that covers a wide range of future trajectories. The network architecture is highly uniform and succinct, leading to an efficient model amenable for real-world deployment. Experiments reveal that our agent-centric network compares favorably with the state-of-the-art methods in prediction accuracy, while achieving scene-centric level inference latency. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The task of 3D semantic scene graph (3DSSG) prediction in the point cloud is challenging since (1) the 3D point cloud only captures geometric structures with limited semantics compared to 2D images, and (2) long-tailed relation distribution inherently hinders the learning of unbiased prediction. Since 2D images provide rich semantics and scene graphs are in nature coped with languages, in this study, we propose Visual-Linguistic Semantics Assisted Training (VL-SAT) scheme that can significantly empower 3DSSG prediction models with discrimination about long-tailed and ambiguous semantic relations. The key idea is to train a powerful multi-modal oracle model to assist the 3D model. This oracle learns reliable structural representations based on semantics from vision, language, and 3D geometry, and its benefits can be heterogeneously passed to the 3D model during the training stage. By effectively utilizing visual-linguistic semantics in training, our VL-SAT can significantly boost common 3DSSG prediction models, such as SGFN and SGGpoint, only with 3D inputs in the inference stage, especially when dealing with tail relation triplets. Comprehensive evaluations and ablation studies on the 3DSSG dataset have validated the effectiveness of the proposed scheme. Code is available at https://github.com/wz7in/CVPR2023-VLSAT. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 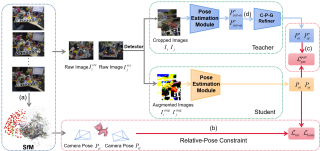
Recently, self-supervised 6D object pose estimation, where synthetic images with object poses (sometimes jointly with un-annotated real images) are used for training, has attracted much attention in computer vision. Some typical works in literature employ a time-consuming differentiable renderer for object pose prediction at the training stage, so that (i) their performances on real images are generally limited due to the gap between their rendered images and real images and (ii) their training process is computationally expensive. To address the two problems, we propose a novel Network for Self-supervised Monocular Object pose estimation by utilizing the predicted Camera poses from un-annotated real images, called SMOC-Net. The proposed network is explored under a knowledge distillation framework, consisting of a teacher model and a student model. The teacher model contains a backbone estimation module for initial object pose estimation, and an object pose refiner for refining the initial object poses using a geometric constraint (called relative-pose constraint) derived from relative camera poses. The student model gains knowledge for object pose estimation from the teacher model by imposing the relative-pose constraint. Thanks to the relative-pose constraint, SMOC-Net could not only narrow the domain gap between synthetic and real data but also reduce the … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 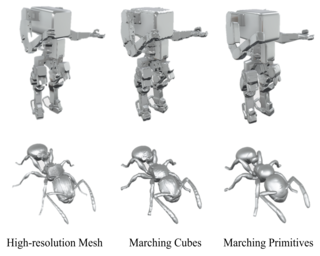
Representing complex objects with basic geometric primitives has long been a topic in computer vision. Primitive-based representations have the merits of compactness and computational efficiency in higher-level tasks such as physics simulation, collision checking, and robotic manipulation. Unlike previous works which extract polygonal meshes from a signed distance function (SDF), in this paper, we present a novel method, named Marching-Primitives, to obtain a primitive-based abstraction directly from an SDF. Our method grows geometric primitives (such as superquadrics) iteratively by analyzing the connectivity of voxels while marching at different levels of signed distance. For each valid connected volume of interest, we march on the scope of voxels from which a primitive is able to be extracted in a probabilistic sense and simultaneously solve for the parameters of the primitive to capture the underlying local geometry. We evaluate the performance of our method on both synthetic and real-world datasets. The results show that the proposed method outperforms the state-of-the-art in terms of accuracy, and is directly generalizable among different categories and scales. The code is open-sourced at https://github.com/ChirikjianLab/Marching-Primitives.git. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Feature matching is a challenging computer vision task that involves finding correspondences between two images of a 3D scene. In this paper we consider the dense approach instead of the more common sparse paradigm, thus striving to find all correspondences. Perhaps counter-intuitively, dense methods have previously shown inferior performance to their sparse and semi-sparse counterparts for estimation of two-view geometry. This changes with our novel dense method, which outperforms both dense and sparse methods on geometry estimation. The novelty is threefold: First, we propose a kernel regression global matcher. Secondly, we propose warp refinement through stacked feature maps and depthwise convolution kernels. Thirdly, we propose learning dense confidence through consistent depth and a balanced sampling approach for dense confidence maps. Through extensive experiments we confirm that our proposed dense method, Dense Kernelized Feature Matching, sets a new state-of-the-art on multiple geometry estimation benchmarks. In particular, we achieve an improvement on MegaDepth-1500 of +4.9 and +8.9 AUC@5 compared to the best previous sparse method and dense method respectively. Our code is provided at the following repository: https://github.com/Parskatt/DKM |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 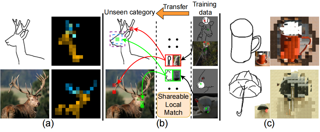
This paper studies the problem of zero-short sketch-based image retrieval (ZS-SBIR), however with two significant differentiators to prior art (i) we tackle all variants (inter-category, intra-category, and cross datasets) of ZS-SBIR with just one network (“everything”), and (ii) we would really like to understand how this sketch-photo matching operates (“explainable”). Our key innovation lies with the realization that such a cross-modal matching problem could be reduced to comparisons of groups of key local patches -- akin to the seasoned “bag-of-words” paradigm. Just with this change, we are able to achieve both of the aforementioned goals, with the added benefit of no longer requiring external semantic knowledge. Technically, ours is a transformer-based cross-modal network, with three novel components (i) a self-attention module with a learnable tokenizer to produce visual tokens that correspond to the most informative local regions, (ii) a cross-attention module to compute local correspondences between the visual tokens across two modalities, and finally (iii) a kernel-based relation network to assemble local putative matches and produce an overall similarity metric for a sketch-photo pair. Experiments show ours indeed delivers superior performances across all ZS-SBIR settings. The all important explainable goal is elegantly achieved by visualizing cross-modal token correspondences, and for … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Existing 3D-aware image synthesis approaches mainly focus on generating a single canonical object and show limited capacity in composing a complex scene containing a variety of objects. This work presents DisCoScene: a 3D-aware generative model for high-quality and controllable scene synthesis. The key ingredient of our method is a very abstract object-level representation (i.e., 3D bounding boxes without semantic annotation) as the scene layout prior, which is simple to obtain, general to describe various scene contents, and yet informative to disentangle objects and background. Moreover, it serves as an intuitive user control for scene editing. Based on such a prior, the proposed model spatially disentangles the whole scene into object-centric generative radiance fields by learning on only 2D images with the global-local discrimination. Our model obtains the generation fidelity and editing flexibility of individual objects while being able to efficiently compose objects and the background into a complete scene. We demonstrate state-of-the-art performance on many scene datasets, including the challenging Waymo outdoor dataset. Our code will be made publicly available. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We propose Gated Stereo, a high-resolution and long-range depth estimation technique that operates on active gated stereo images. Using active and high dynamic range passive captures, Gated Stereo exploits multi-view cues alongside time-of-flight intensity cues from active gating. To this end, we propose a depth estimation method with a monocular and stereo depth prediction branch which are combined in a final fusion stage. Each block is supervised through a combination of supervised and gated self-supervision losses. To facilitate training and validation, we acquire a long-range synchronized gated stereo dataset for automotive scenarios. We find that the method achieves an improvement of more than 50 % MAE compared to the next best RGB stereo method, and 74 % MAE to existing monocular gated methods for distances up to 160 m. Our code, models and datasets are available here: https://light.princeton.edu/gatedstereo/. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 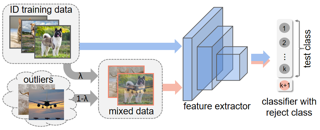
Reliable confidence estimation for deep neural classifiers is a challenging yet fundamental requirement in high-stakes applications. Unfortunately, modern deep neural networks are often overconfident for their erroneous predictions. In this work, we exploit the easily available outlier samples, i.e., unlabeled samples coming from non-target classes, for helping detect misclassification errors. Particularly, we find that the well-known Outlier Exposure, which is powerful in detecting out-of-distribution (OOD) samples from unknown classes, does not provide any gain in identifying misclassification errors. Based on these observations, we propose a novel method called OpenMix, which incorporates open-world knowledge by learning to reject uncertain pseudo-samples generated via outlier transformation. OpenMix significantly improves confidence reliability under various scenarios, establishing a strong and unified framework for detecting both misclassified samples from known classes and OOD samples from unknown classes. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Implicit neural representations (INR) have gained significant popularity for signal and image representation for many end-tasks, such as superresolution, 3D modeling, and more. Most INR architectures rely on sinusoidal positional encoding, which accounts for high-frequency information in data. However, the finite encoding size restricts the model’s representational power. Higher representational power is needed to go from representing a single given image to representing large and diverse datasets. Our approach addresses this gap by representing an image with a polynomial function and eliminates the need for positional encodings. Therefore, to achieve a progressively higher degree of polynomial representation, we use element-wise multiplications between features and affine-transformed coordinate locations after every ReLU layer. The proposed method is evaluated qualitatively and quantitatively on large datasets like ImageNet. The proposed Poly-INR model performs comparably to state-of-the-art generative models without any convolution, normalization, or self-attention layers, and with far fewer trainable parameters. With much fewer training parameters and higher representative power, our approach paves the way for broader adoption of INR models for generative modeling tasks in complex domains. The code is available at https://github.com/Rajhans0/Poly_INR |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The performance of video prediction has been greatly boosted by advanced deep neural networks. However, most of the current methods suffer from large model sizes and require extra inputs, e.g., semantic/depth maps, for promising performance. For efficiency consideration, in this paper, we propose a Dynamic Multi-scale Voxel Flow Network (DMVFN) to achieve better video prediction performance at lower computational costs with only RGB images, than previous methods. The core of our DMVFN is a differentiable routing module that can effectively perceive the motion scales of video frames. Once trained, our DMVFN selects adaptive sub-networks for different inputs at the inference stage. Experiments on several benchmarks demonstrate that our DMVFN is an order of magnitude faster than Deep Voxel Flow and surpasses the state-of-the-art iterative-based OPT on generated image quality. Our code and demo are available at https://huxiaotaostasy.github.io/DMVFN/. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present the Habitat-Matterport 3D Semantics (HM3DSEM) dataset. HM3DSEM is the largest dataset of 3D real-world spaces with densely annotated semantics that is currently available to the academic community. It consists of 142,646 object instance annotations across 216 3D spaces and 3,100 rooms within those spaces. The scale, quality, and diversity of object annotations far exceed those of prior datasets. A key difference setting apart HM3DSEM from other datasets is the use of texture information to annotate pixel-accurate object boundaries. We demonstrate the effectiveness of HM3DSEM dataset for the Object Goal Navigation task using different methods. Policies trained using HM3DSEM perform outperform those trained on prior datasets. Introduction of HM3DSEM in the Habitat ObjectNav Challenge lead to an increase in participation from 400 submissions in 2021 to 1022 submissions in 2022. Project page: https://aihabitat.org/datasets/hm3d-semantics/ |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Although DETR-based 3D detectors simplify the detection pipeline and achieve direct sparse predictions, their performance still lags behind dense detectors with post-processing for 3D object detection from point clouds. DETRs usually adopt a larger number of queries than GTs (e.g., 300 queries v.s. ~40 objects in Waymo) in a scene, which inevitably incur many false positives during inference. In this paper, we propose a simple yet effective sparse 3D detector, named Query Contrast Voxel-DETR (ConQueR), to eliminate the challenging false positives, and achieve more accurate and sparser predictions. We observe that most false positives are highly overlapping in local regions, caused by the lack of explicit supervision to discriminate locally similar queries. We thus propose a Query Contrast mechanism to explicitly enhance queries towards their best-matched GTs over all unmatched query predictions. This is achieved by the construction of positive and negative GT-query pairs for each GT, and a contrastive loss to enhance positive GT-query pairs against negative ones based on feature similarities. ConQueR closes the gap of sparse and dense 3D detectors, and reduces ~60% false positives. Our single-frame ConQueR achieves 71.6 mAPH/L2 on the challenging Waymo Open Dataset validation set, outperforming previous sota methods by over 2.0 mAPH/L2. … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recently, DreamFusion demonstrated the utility of a pretrained text-to-image diffusion model to optimize Neural Radiance Fields (NeRF), achieving remarkable text-to-3D synthesis results. However, the method has two inherent limitations: 1) optimization of the NeRF representation is extremely slow, 2) NeRF is supervised by images at a low resolution (64×64), thus leading to low-quality 3D models with a long wait time. In this paper, we address these limitations by utilizing a two-stage coarse-to-fine optimization framework. In the first stage, we use a sparse 3D neural representation to accelerate optimization while using a low-resolution diffusion prior. In the second stage, we use a textured mesh model initialized from the coarse neural representation, allowing us to perform optimization with a very efficient differentiable renderer interacting with high-resolution images. Our method, dubbed Magic3D, can create a 3D mesh model in 40 minutes, 2× faster than DreamFusion (reportedly taking 1.5 hours on average), while achieving 8× higher resolution. User studies show 61.7% raters to prefer our approach than DreamFusion. Together with the image-conditioned generation capabilities, we provide users with new ways to control 3D synthesis, opening up new avenues to various creative applications. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Text-to-motion generation is an emerging and challenging problem, which aims to synthesize motion with the same semantics as the input text. However, due to the lack of diverse labeled training data, most approaches either limit to specific types of text annotations or require online optimizations to cater to the texts during inference at the cost of efficiency and stability. In this paper, we investigate offline open-vocabulary text-to-motion generation in a zero-shot learning manner that neither requires paired training data nor extra online optimization to adapt for unseen texts. Inspired by the prompt learning in NLP, we pretrain a motion generator that learns to reconstruct the full motion from the masked motion. During inference, instead of changing the motion generator, our method reformulates the input text into a masked motion as the prompt for the motion generator to “reconstruct” the motion. In constructing the prompt, the unmasked poses of the prompt are synthesized by a text-to-pose generator. To supervise the optimization of the text-to-pose generator, we propose the first text-pose alignment model for measuring the alignment between texts and 3D poses. And to prevent the pose generator from overfitting to limited training texts, we further propose a novel wordless training mechanism … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Creative workflows for generating graphical documents involve complex inter-related tasks, such as aligning elements, choosing appropriate fonts, or employing aesthetically harmonious colors. In this work, we attempt at building a holistic model that can jointly solve many different design tasks. Our model, which we denote by FlexDM, treats vector graphic documents as a set of multi-modal elements, and learns to predict masked fields such as element type, position, styling attributes, image, or text, using a unified architecture. Through the use of explicit multi-task learning and in-domain pre-training, our model can better capture the multi-modal relationships among the different document fields. Experimental results corroborate that our single FlexDM is able to successfully solve a multitude of different design tasks, while achieving performance that is competitive with task-specific and costly baselines. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Optical flow is an indispensable building block for various important computer vision tasks, including motion estimation, object tracking, and disparity measurement. In this work, we propose TransFlow, a pure transformer architecture for optical flow estimation. Compared to dominant CNN-based methods, TransFlow demonstrates three advantages. First, it provides more accurate correlation and trustworthy matching in flow estimation by utilizing spatial self-attention and cross-attention mechanisms between adjacent frames to effectively capture global dependencies; Second, it recovers more compromised information (e.g., occlusion and motion blur) in flow estimation through long-range temporal association in dynamic scenes; Third, it enables a concise self-learning paradigm and effectively eliminate the complex and laborious multi-stage pre-training procedures. We achieve the state-of-the-art results on the Sintel, KITTI-15, as well as several downstream tasks, including video object detection, interpolation and stabilization. For its efficacy, we hope TransFlow could serve as a flexible baseline for optical flow estimation. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The public model zoo containing enormous powerful pretrained model families (e.g., ResNet/DeiT) has reached an unprecedented scope than ever, which significantly contributes to the success of deep learning. As each model family consists of pretrained models with diverse scales (e.g., DeiT-Ti/S/B), it naturally arises a fundamental question of how to efficiently assemble these readily available models in a family for dynamic accuracy-efficiency trade-offs at runtime. To this end, we present Stitchable Neural Networks (SN-Net), a novel scalable and efficient framework for model deployment. It cheaply produces numerous networks with different complexity and performance trade-offs given a family of pretrained neural networks, which we call anchors. Specifically, SN-Net splits the anchors across the blocks/layers and then stitches them together with simple stitching layers to map the activations from one anchor to another. With only a few epochs of training, SN-Net effectively interpolates between the performance of anchors with varying scales. At runtime, SN-Net can instantly adapt to dynamic resource constraints by switching the stitching positions. Extensive experiments on ImageNet classification demonstrate that SN-Net can obtain on-par or even better performance than many individually trained networks while supporting diverse deployment scenarios. For example, by stitching Swin Transformers, we challenge hundreds of models … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recently, self-supervised large-scale visual pre-training models have shown great promise in representing pixel-level semantic relationships, significantly promoting the development of unsupervised dense prediction tasks, e.g., unsupervised semantic segmentation (USS). The extracted relationship among pixel-level representations typically contains rich class-aware information that semantically identical pixel embeddings in the representation space gather together to form sophisticated concepts. However, leveraging the learned models to ascertain semantically consistent pixel groups or regions in the image is non-trivial since over/ under-clustering overwhelms the conceptualization procedure under various semantic distributions of different images. In this work, we investigate the pixel-level semantic aggregation in self-supervised ViT pre-trained models as image Segmentation and propose the Adaptive Conceptualization approach for USS, termed ACSeg. Concretely, we explicitly encode concepts into learnable prototypes and design the Adaptive Concept Generator (ACG), which adaptively maps these prototypes to informative concepts for each image. Meanwhile, considering the scene complexity of different images, we propose the modularity loss to optimize ACG independent of the concept number based on estimating the intensity of pixel pairs belonging to the same concept. Finally, we turn the USS task into classifying the discovered concepts in an unsupervised manner. Extensive experiments with state-of-the-art results demonstrate the effectiveness of the proposed … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 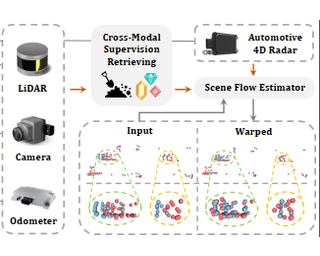
This work proposes a novel approach to 4D radar-based scene flow estimation via cross-modal learning. Our approach is motivated by the co-located sensing redundancy in modern autonomous vehicles. Such redundancy implicitly provides various forms of supervision cues to the radar scene flow estimation. Specifically, we introduce a multi-task model architecture for the identified cross-modal learning problem and propose loss functions to opportunistically engage scene flow estimation using multiple cross-modal constraints for effective model training. Extensive experiments show the state-of-the-art performance of our method and demonstrate the effectiveness of cross-modal supervised learning to infer more accurate 4D radar scene flow. We also show its usefulness to two subtasks - motion segmentation and ego-motion estimation. Our source code will be available on https://github.com/Toytiny/CMFlow. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
This paper proposes a regularizer called Implicit Neural Representation Regularizer (INRR) to improve the generalization ability of the Implicit Neural Representation (INR). The INR is a fully connected network that can represent signals with details not restricted by grid resolution. However, its generalization ability could be improved, especially with non-uniformly sampled data. The proposed INRR is based on learned Dirichlet Energy (DE) that measures similarities between rows/columns of the matrix. The smoothness of the Laplacian matrix is further integrated by parameterizing DE with a tiny INR. INRR improves the generalization of INR in signal representation by perfectly integrating the signal’s self-similarity with the smoothness of the Laplacian matrix. Through well-designed numerical experiments, the paper also reveals a series of properties derived from INRR, including momentum methods like convergence trajectory and multi-scale similarity. Moreover, the proposed method could improve the performance of other signal representation methods. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 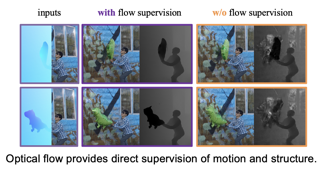
In this paper we present a new method for deformable NeRF that can directly use optical flow as supervision. We overcome the major challenge with respect to the computationally inefficiency of enforcing the flow constraints to the backward deformation field, used by deformable NeRFs. Specifically, we show that inverting the backward deformation function is actually not needed for computing scene flows between frames. This insight dramatically simplifies the problem, as one is no longer constrained to deformation functions that can be analytically inverted. Instead, thanks to the weak assumptions required by our derivation based on the inverse function theorem, our approach can be extended to a broad class of commonly used backward deformation field. We present results on monocular novel view synthesis with rapid object motion, and demonstrate significant improvements over baselines without flow supervision. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Dataset Distillation (DD), a newly emerging field, aims at generating much smaller but efficient synthetic training datasets from large ones. Existing DD methods based on gradient matching achieve leading performance; however, they are extremely computationally intensive as they require continuously optimizing a dataset among thousands of randomly initialized models. In this paper, we assume that training the synthetic data with diverse models leads to better generalization performance. Thus we propose two model augmentation techniques, i.e. using early-stage models and parameter perturbation to learn an informative synthetic set with significantly reduced training cost. Extensive experiments demonstrate that our method achieves up to 20× speedup and comparable performance on par with state-of-the-art methods. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Obtaining photorealistic reconstructions of objects from sparse views is inherently ambiguous and can only be achieved by learning suitable reconstruction priors. Earlier works on sparse rigid object reconstruction successfully learned such priors from large datasets such as CO3D. In this paper, we extend this approach to dynamic objects. We use cats and dogs as a representative example and introduce Common Pets in 3D (CoP3D), a collection of crowd-sourced videos showing around 4,200 distinct pets. CoP3D is one of the first large-scale datasets for benchmarking non-rigid 3D reconstruction “in the wild”. We also propose Tracker-NeRF, a method for learning 4D reconstruction from our dataset. At test time, given a small number of video frames of an unseen sequence, Tracker-NeRF predicts the trajectories and dynamics of the 3D points and generates new views, interpolating viewpoint and time. Results on CoP3D reveal significantly better non-rigid new-view synthesis performance than existing baselines. The data is available on the project webpage: https://cop3d.github.io/. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Pseudo-labeling approaches have been proven beneficial for semi-supervised learning (SSL) schemes in computer vision and medical imaging. Most works are dedicated to finding samples with high-confidence pseudo-labels from the perspective of model predicted probability. Whereas this way may lead to the inclusion of incorrectly pseudo-labeled data if the threshold is not carefully adjusted. In addition, low-confidence probability samples are frequently disregarded and not employed to their full potential. In this paper, we propose a novel Pseudo-loss Estimation and Feature Adversarial Training semi-supervised framework, termed as PEFAT, to boost the performance of multi-class and multi-label medical image classification from the point of loss distribution modeling and adversarial training. Specifically, we develop a trustworthy data selection scheme to split a high-quality pseudo-labeled set, inspired by the dividable pseudo-loss assumption that clean data tend to show lower loss while noise data is the opposite. Instead of directly discarding these samples with low-quality pseudo-labels, we present a novel regularization approach to learn discriminate information from them via injecting adversarial noises at the feature-level to smooth the decision boundary. Experimental results on three medical and two natural image benchmarks validate that our PEFAT can achieve a promising performance and surpass other state-of-the-art methods. The code … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
This paper focuses on analyzing and improving the commonsense ability of recent popular vision-language (VL) models. Despite the great success, we observe that existing VL-models still lack commonsense knowledge/reasoning ability (e.g., “Lemons are sour”), which is a vital component towards artificial general intelligence. Through our analysis, we find one important reason is that existing large-scale VL datasets do not contain much commonsense knowledge, which motivates us to improve the commonsense of VL-models from the data perspective. Rather than collecting a new VL training dataset, we propose a more scalable strategy, i.e., “Data Augmentation with kNowledge graph linearization for CommonsensE capability” (DANCE). It can be viewed as one type of data augmentation technique, which can inject commonsense knowledge into existing VL datasets on the fly during training. More specifically, we leverage the commonsense knowledge graph (e.g., ConceptNet) and create variants of text description in VL datasets via bidirectional sub-graph sequentialization. For better commonsense evaluation, we further propose the first retrieval-based commonsense diagnostic benchmark. By conducting extensive experiments on some representative VL-models, we demonstrate that our DANCE technique is able to significantly improve the commonsense ability while maintaining the performance on vanilla retrieval tasks. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Text-guided image editing can have a transformative impact in supporting creative applications. A key challenge is to generate edits that are faithful to the input text prompt, while consistent with the input image. We present Imagen Editor, a cascaded diffusion model, built by fine-tuning Imagen on text-guided image inpainting. Imagen Editor’s edits are faithful to the text prompts, which is accomplished by incorporating object detectors for proposing inpainting masks during training. In addition, text-guided image inpainting captures fine details in the input image by conditioning the cascaded pipeline on the original high resolution image. To improve qualitative and quantitative evaluation, we introduce EditBench, a systematic benchmark for text-guided image inpainting. EditBench evaluates inpainting edits on natural and generated images exploring objects, attributes, and scenes. Through extensive human evaluation on EditBench, we find that object-masking during training leads to across-the-board improvements in text-image alignment -- such that Imagen Editor is preferred over DALL-E 2 and Stable Diffusion -- and, as a cohort, these models are better at object-rendering than text-rendering, and handle material/color/size attributes better than count/shape attributes. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Volumetric scene representations enable photorealistic view synthesis for static scenes and form the basis of several existing 6-DoF video techniques. However, the volume rendering procedures that drive these representations necessitate careful trade-offs in terms of quality, rendering speed, and memory efficiency. In particular, existing methods fail to simultaneously achieve real-time performance, small memory footprint, and high-quality rendering for challenging real-world scenes. To address these issues, we present HyperReel --- a novel 6-DoF video representation. The two core components of HyperReel are: (1) a ray-conditioned sample prediction network that enables high-fidelity, high frame rate rendering at high resolutions and (2) a compact and memory-efficient dynamic volume representation. Our 6-DoF video pipeline achieves the best performance compared to prior and contemporary approaches in terms of visual quality with small memory requirements, while also rendering at up to 18 frames-per-second at megapixel resolution without any custom CUDA code. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recent advances in 3D scene representation and novel view synthesis have witnessed the rise of Neural Radiance Fields (NeRFs). Nevertheless, it is not trivial to exploit NeRF for the photorealistic 3D scene stylization task, which aims to generate visually consistent and photorealistic stylized scenes from novel views. Simply coupling NeRF with photorealistic style transfer (PST) will result in cross-view inconsistency and degradation of stylized view syntheses. Through a thorough analysis, we demonstrate that this non-trivial task can be simplified in a new light: When transforming the appearance representation of a pre-trained NeRF with Lipschitz mapping, the consistency and photorealism across source views will be seamlessly encoded into the syntheses. That motivates us to build a concise and flexible learning framework namely LipRF, which upgrades arbitrary 2D PST methods with Lipschitz mapping tailored for the 3D scene. Technically, LipRF first pre-trains a radiance field to reconstruct the 3D scene, and then emulates the style on each view by 2D PST as the prior to learn a Lipschitz network to stylize the pre-trained appearance. In view of that Lipschitz condition highly impacts the expressivity of the neural network, we devise an adaptive regularization to balance the reconstruction and stylization. A gradual gradient … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 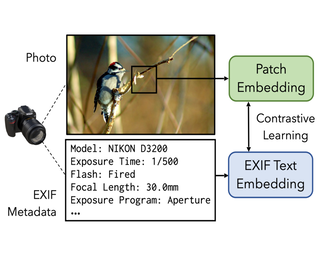
We learn a visual representation that captures information about the camera that recorded a given photo. To do this, we train a multimodal embedding between image patches and the EXIF metadata that cameras automatically insert into image files. Our model represents this metadata by simply converting it to text and then processing it with a transformer. The features that we learn significantly outperform other self-supervised and supervised features on downstream image forensics and calibration tasks. In particular, we successfully localize spliced image regions “zero shot” by clustering the visual embeddings for all of the patches within an image. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Training deep models for semantic scene completion is challenging due to the sparse and incomplete input, a large quantity of objects of diverse scales as well as the inherent label noise for moving objects. To address the above-mentioned problems, we propose the following three solutions: 1) Redesigning the completion network. We design a novel completion network, which consists of several Multi-Path Blocks (MPBs) to aggregate multi-scale features and is free from the lossy downsampling operations. 2) Distilling rich knowledge from the multi-frame model. We design a novel knowledge distillation objective, dubbed Dense-to-Sparse Knowledge Distillation (DSKD). It transfers the dense, relation-based semantic knowledge from the multi-frame teacher to the single-frame student, significantly improving the representation learning of the single-frame model. 3) Completion label rectification. We propose a simple yet effective label rectification strategy, which uses off-the-shelf panoptic segmentation labels to remove the traces of dynamic objects in completion labels, greatly improving the performance of deep models especially for those moving objects. Extensive experiments are conducted in two public semantic scene completion benchmarks, i.e., SemanticKITTI and SemanticPOSS. Our SCPNet ranks 1st on SemanticKITTI semantic scene completion challenge and surpasses the competitive S3CNet by 7.2 mIoU. SCPNet also outperforms previous completion algorithms on … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Real-world medical image segmentation has tremendous long-tailed complexity of objects, among which tail conditions correlate with relatively rare diseases and are clinically significant. A trustworthy medical AI algorithm should demonstrate its effectiveness on tail conditions to avoid clinically dangerous damage in these out-of-distribution (OOD) cases. In this paper, we adopt the concept of object queries in Mask transformers to formulate semantic segmentation as a soft cluster assignment. The queries fit the feature-level cluster centers of inliers during training. Therefore, when performing inference on a medical image in real-world scenarios, the similarity between pixels and the queries detects and localizes OOD regions. We term this OOD localization as MaxQuery. Furthermore, the foregrounds of real-world medical images, whether OOD objects or inliers, are lesions. The difference between them is obviously less than that between the foreground and background, resulting in the object queries may focus redundantly on the background. Thus, we propose a query-distribution (QD) loss to enforce clear boundaries between segmentation targets and other regions at the query level, improving the inlier segmentation and OOD indication. Our proposed framework is tested on two real-world segmentation tasks, i.e., segmentation of pancreatic and liver tumors, outperforming previous leading algorithms by an average of … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 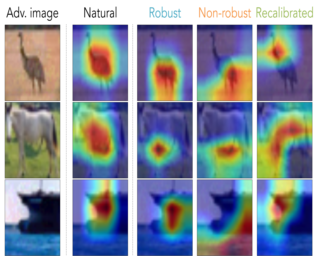
Deep neural networks are susceptible to adversarial attacks due to the accumulation of perturbations in the feature level, and numerous works have boosted model robustness by deactivating the non-robust feature activations that cause model mispredictions. However, we claim that these malicious activations still contain discriminative cues and that with recalibration, they can capture additional useful information for correct model predictions. To this end, we propose a novel, easy-to-plugin approach named Feature Separation and Recalibration (FSR) that recalibrates the malicious, non-robust activations for more robust feature maps through Separation and Recalibration. The Separation part disentangles the input feature map into the robust feature with activations that help the model make correct predictions and the non-robust feature with activations that are responsible for model mispredictions upon adversarial attack. The Recalibration part then adjusts the non-robust activations to restore the potentially useful cues for model predictions. Extensive experiments verify the superiority of FSR compared to traditional deactivation techniques and demonstrate that it improves the robustness of existing adversarial training methods by up to 8.57% with small computational overhead. Codes are available at https://github.com/wkim97/FSR. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 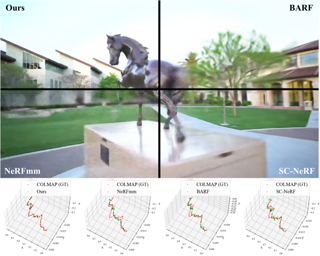
Training a Neural Radiance Field (NeRF) without pre-computed camera poses is challenging. Recent advances in this direction demonstrate the possibility of jointly optimising a NeRF and camera poses in forward-facing scenes. However, these methods still face difficulties during dramatic camera movement. We tackle this challenging problem by incorporating undistorted monocular depth priors. These priors are generated by correcting scale and shift parameters during training, with which we are then able to constrain the relative poses between consecutive frames. This constraint is achieved using our proposed novel loss functions. Experiments on real-world indoor and outdoor scenes show that our method can handle challenging camera trajectories and outperforms existing methods in terms of novel view rendering quality and pose estimation accuracy. Our project page is https://nope-nerf.active.vision. |
|
Highlight
|
Consistent-Teacher: Towards Reducing Inconsistent Pseudo-Targets in Semi-Supervised Object Detection
Poster
[ West Building Exhibit Halls ABC ] 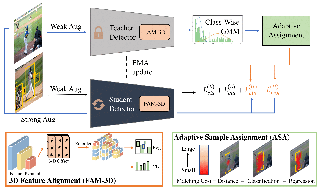
In this study, we dive deep into the inconsistency of pseudo targets in semi-supervised object detection (SSOD). Our core observation is that the oscillating pseudo-targets undermine the training of an accurate detector. It injects noise into the student’s training, leading to severe overfitting problems. Therefore, we propose a systematic solution, termed NAME, to reduce the inconsistency. First, adaptive anchor assignment~(ASA) substitutes the static IoU-based strategy, which enables the student network to be resistant to noisy pseudo-bounding boxes. Then we calibrate the subtask predictions by designing a 3D feature alignment module~(FAM-3D). It allows each classification feature to adaptively query the optimal feature vector for the regression task at arbitrary scales and locations. Lastly, a Gaussian Mixture Model (GMM) dynamically revises the score threshold of pseudo-bboxes, which stabilizes the number of ground truths at an early stage and remedies the unreliable supervision signal during training. NAME provides strong results on a large range of SSOD evaluations. It achieves 40.0 mAP with ResNet-50 backbone given only 10% of annotated MS-COCO data, which surpasses previous baselines using pseudo labels by around 3 mAP. When trained on fully annotated MS-COCO with additional unlabeled data, the performance further increases to 47.7 mAP. Our code is available … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We show, for the first time, that neural networks trained only on synthetic data achieve state-of-the-art accuracy on the problem of 3D human pose and shape (HPS) estimation from real images. Previous synthetic datasets have been small, unrealistic, or lacked realistic clothing. Achieving sufficient realism is non-trivial and we show how to do this for full bodies in motion. Specifically, our BEDLAM dataset contains monocular RGB videos with ground-truth 3D bodies in SMPL-X format. It includes a diversity of body shapes, motions, skin tones, hair, and clothing. The clothing is realistically simulated on the moving bodies using commercial clothing physics simulation. We render varying numbers of people in realistic scenes with varied lighting and camera motions. We then train various HPS regressors using BEDLAM and achieve state-of-the-art accuracy on real-image benchmarks despite training with synthetic data. We use BEDLAM to gain insights into what model design choices are important for accuracy. With good synthetic training data, we find that a basic method like HMR approaches the accuracy of the current SOTA method (CLIFF). BEDLAM is useful for a variety of tasks and all images, ground truth bodies, 3D clothing, support code, and more are available for research purposes. Additionally, we … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Visual information extraction (VIE) plays an important role in Document Intelligence. Generally, it is divided into two tasks: semantic entity recognition (SER) and relation extraction (RE). Recently, pre-trained models for documents have achieved substantial progress in VIE, particularly in SER. However, most of the existing models learn the geometric representation in an implicit way, which has been found insufficient for the RE task since geometric information is especially crucial for RE. Moreover, we reveal another factor that limits the performance of RE lies in the objective gap between the pre-training phase and the fine-tuning phase for RE. To tackle these issues, we propose in this paper a multi-modal framework, named GeoLayoutLM, for VIE. GeoLayoutLM explicitly models the geometric relations in pre-training, which we call geometric pre-training. Geometric pre-training is achieved by three specially designed geometry-related pre-training tasks. Additionally, novel relation heads, which are pre-trained by the geometric pre-training tasks and fine-tuned for RE, are elaborately designed to enrich and enhance the feature representation. According to extensive experiments on standard VIE benchmarks, GeoLayoutLM achieves highly competitive scores in the SER task and significantly outperforms the previous state-of-the-arts for RE (e.g.,the F1 score of RE on FUNSD is boosted from 80.35% to … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We propose Video Localized Narratives, a new form of multimodal video annotations connecting vision and language. In the original Localized Narratives, annotators speak and move their mouse simultaneously on an image, thus grounding each word with a mouse trace segment. However, this is challenging on a video. Our new protocol empowers annotators to tell the story of a video with Localized Narratives, capturing even complex events involving multiple actors interacting with each other and with several passive objects. We annotated 20k videos of the OVIS, UVO, and Oops datasets, totalling 1.7M words. Based on this data, we also construct new benchmarks for the video narrative grounding and video question answering tasks, and provide reference results from strong baseline models. Our annotations are available at https://google.github.io/video-localized-narratives/. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Legged robots have the potential to expand the reach of autonomy beyond paved roads. In this work, we consider the difficult problem of locomotion on challenging terrains using a single forward-facing depth camera. Due to the partial observability of the problem, the robot has to rely on past observations to infer the terrain currently beneath it. To solve this problem, we follow the paradigm in computer vision that explicitly models the 3D geometry of the scene and propose Neural Volumetric Memory (NVM), a geometric memory architecture that explicitly accounts for the SE(3) equivariance of the 3D world. NVM aggregates feature volumes from multiple camera views by first bringing them back to the ego-centric frame of the robot. We test the learned visual-locomotion policy on a physical robot and show that our approach, learning legged locomotion with neural volumetric memory, produces performance gains over prior works on challenging terrains. We include ablation studies and show that the representations stored in the neural volumetric memory capture sufficient geometric information to reconstruct the scene. Our project page with videos is https://rchalyang.github.io/NVM/ |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Object models are gradually progressing from predicting just category labels to providing detailed descriptions of object instances. This motivates the need for large datasets which go beyond traditional object masks and provide richer annotations such as part masks and attributes. Hence, we introduce PACO: Parts and Attributes of Common Objects. It spans 75 object categories, 456 object-part categories and 55 attributes across image (LVIS) and video (Ego4D) datasets. We provide 641K part masks annotated across 260K object boxes, with roughly half of them exhaustively annotated with attributes as well. We design evaluation metrics and provide benchmark results for three tasks on the dataset: part mask segmentation, object and part attribute prediction and zero-shot instance detection. Dataset, models, and code are open-sourced at https://github.com/facebookresearch/paco. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] Accurate segmentation of cellular images remains an elusive task due to the intrinsic variability in morphology of biological structures. Complete manual segmentation is unfeasible for large datasets, and while supervised methods have been proposed to automate segmentation, they often rely on manually generated ground truths which are especially challenging and time consuming to generate in biology due to the requirement of domain expertise. Furthermore, these methods have limited generalization capacity, requiring additional manual labels to be generated for each dataset and use case. We introduce MAESTER (Masked AutoEncoder guided SegmenTation at pixEl Resolution), a self-supervised method for accurate, subcellular structure segmentation at pixel resolution. MAESTER treats segmentation as a representation learning and clustering problem. Specifically, MAESTER learns semantically meaningful token representations of multi-pixel image patches while simultaneously maintaining a sufficiently large field of view for contextual learning. We also develop a cover-and-stride inference strategy to achieve pixel-level subcellular structure segmentation. We evaluated MAESTER on a publicly available volumetric electron microscopy (VEM) dataset of primary mouse pancreatic islets beta cells and achieved upwards of 29.1% improvement over state-of-the-art under the same evaluation criteria. Furthermore, our results are competitive against supervised methods trained on the same tasks, closing the gap between self-supervised … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Typical video compression systems consist of two main modules: motion coding and residual coding. This general architecture is adopted by classical coding schemes (such as international standards H.265 and H.266) and deep learning-based coding schemes. We propose a novel B-frame coding architecture based on two-layer Conditional Augmented Normalization Flows (CANF). It has the striking feature of not transmitting any motion information. Our proposed idea of video compression without motion coding offers a new direction for learned video coding. Our base layer is a low-resolution image compressor that replaces the full-resolution motion compressor. The low-resolution coded image is merged with the warped high-resolution images to generate a high-quality image as a conditioning signal for the enhancement-layer image coding in full resolution. One advantage of this architecture is significantly reduced computational complexity due to eliminating the motion information compressor. In addition, we adopt a skip-mode coding technique to reduce the transmitted latent samples. The rate-distortion performance of our scheme is slightly lower than that of the state-of-the-art learned B-frame coding scheme, B-CANF, but outperforms other learned B-frame coding schemes. However, compared to B-CANF, our scheme saves 45% of multiply-accumulate operations (MACs) for encoding and 27% of MACs for decoding. The code is … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] Video Frame Interpolation (VFI) aims to generate intermediate video frames between consecutive input frames. Since the event cameras are bio-inspired sensors that only encode brightness changes with a micro-second temporal resolution, several works utilized the event camera to enhance the performance of VFI. However, existing methods estimate bidirectional inter-frame motion fields with only events or approximations, which can not consider the complex motion in real-world scenarios. In this paper, we propose a novel event-based VFI framework with cross-modal asymmetric bidirectional motion field estimation. In detail, our EIF-BiOFNet utilizes each valuable characteristic of the events and images for direct estimation of inter-frame motion fields without any approximation methods.Moreover, we develop an interactive attention-based frame synthesis network to efficiently leverage the complementary warping-based and synthesis-based features. Finally, we build a large-scale event-based VFI dataset, ERF-X170FPS, with a high frame rate, extreme motion, and dynamic textures to overcome the limitations of previous event-based VFI datasets. Extensive experimental results validate that our method shows significant performance improvement over the state-of-the-art VFI methods on various datasets.Our project pages are available at: https://github.com/intelpro/CBMNet |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 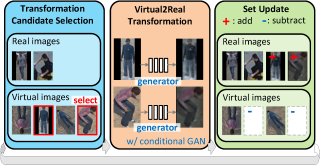
To effectively interrogate UAV-based images for detecting objects of interest, such as humans, it is essential to acquire large-scale UAV-based datasets that include human instances with various poses captured from widely varying viewing angles. As a viable alternative to laborious and costly data curation, we introduce Progressive Transformation Learning (PTL), which gradually augments a training dataset by adding transformed virtual images with enhanced realism. Generally, a virtual2real transformation generator in the conditional GAN framework suffers from quality degradation when a large domain gap exists between real and virtual images. To deal with the domain gap, PTL takes a novel approach that progressively iterates the following three steps: 1) select a subset from a pool of virtual images according to the domain gap, 2) transform the selected virtual images to enhance realism, and 3) add the transformed virtual images to the training set while removing them from the pool. In PTL, accurately quantifying the domain gap is critical. To do that, we theoretically demonstrate that the feature representation space of a given object detector can be modeled as a multivariate Gaussian distribution from which the Mahalanobis distance between a virtual object and the Gaussian distribution of each object category in the … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 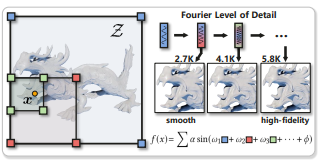
We develop a simple yet surprisingly effective implicit representing scheme called Multiplicative Fourier Level of Detail (MFLOD) motivated by the recent success of multiplicative filter network. Built on multi-resolution feature grid/volume (e.g., the sparse voxel octree), each level’s feature is first modulated by a sinusoidal function and then element-wisely multiplied by a linear transformation of previous layer’s representation in a layer-to-layer recursive manner, yielding the scale-aggregated encodings for a subsequent simple linear forward to get final output. In contrast to previous hybrid representations relying on interleaved multilevel fusion and nonlinear activation-based decoding, MFLOD could be elegantly characterized as a linear combination of sine basis functions with varying amplitude, frequency, and phase upon the learned multilevel features, thus offering great feasibility in Fourier analysis. Comprehensive experimental results on implicit neural representation learning tasks including image fitting, 3D shape representation, and neural radiance fields well demonstrate the superior quality and generalizability achieved by the proposed MFLOD scheme. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] Understanding how well a deep generative model captures a distribution of high-dimensional data remains an important open challenge. It is especially difficult for certain model classes, such as Generative Adversarial Networks and Diffusion Models, whose models do not admit exact likelihoods. In this work, we demonstrate that generalized empirical likelihood (GEL) methods offer a family of diagnostic tools that can identify many deficiencies of deep generative models (DGMs). We show, with appropriate specification of moment conditions, that the proposed method can identify which modes have been dropped, the degree to which DGMs are mode imbalanced, and whether DGMs sufficiently capture intra-class diversity. We show how to combine techniques from Maximum Mean Discrepancy and Generalized Empirical Likelihood to create not only distribution tests that retain per-sample interpretability, but also metrics that include label information. We find that such tests predict the degree of mode dropping and mode imbalance up to 60% better than metrics such as improved precision/recall. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Typical layout-to-image synthesis (LIS) models generate images for a closed set of semantic classes, e.g., 182 common objects in COCO-Stuff. In this work, we explore the freestyle capability of the model, i.e., how far can it generate unseen semantics (e.g., classes, attributes, and styles) onto a given layout, and call the task Freestyle LIS (FLIS). Thanks to the development of large-scale pre-trained language-image models, a number of discriminative models (e.g., image classification and object detection) trained on limited base classes are empowered with the ability of unseen class prediction. Inspired by this, we opt to leverage large-scale pre-trained text-to-image diffusion models to achieve the generation of unseen semantics. The key challenge of FLIS is how to enable the diffusion model to synthesize images from a specific layout which very likely violates its pre-learned knowledge, e.g., the model never sees “a unicorn sitting on a bench” during its pre-training. To this end, we introduce a new module called Rectified Cross-Attention (RCA) that can be conveniently plugged in the diffusion model to integrate semantic masks. This “plug-in” is applied in each cross-attention layer of the model to rectify the attention maps between image and text tokens. The key idea of RCA is … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
To apply optical flow in practice, it is often necessary to resize the input to smaller dimensions in order to reduce computational costs. However, downsizing inputs makes the estimation more challenging because objects and motion ranges become smaller. Even though recent approaches have demonstrated high-quality flow estimation, they tend to fail to accurately model small objects and precise boundaries when the input resolution is lowered, restricting their applicability to high-resolution inputs. In this paper, we introduce AnyFlow, a robust network that estimates accurate flow from images of various resolutions. By representing optical flow as a continuous coordinate-based representation, AnyFlow generates outputs at arbitrary scales from low-resolution inputs, demonstrating superior performance over prior works in capturing tiny objects with detail preservation on a wide range of scenes. We establish a new state-of-the-art performance of cross-dataset generalization on the KITTI dataset, while achieving comparable accuracy on the online benchmarks to other SOTA methods. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models--a language model (GPT-3) and a text-to-image model (Stable Diffusion)--to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per-example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 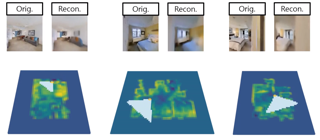
We propose a novel type of map for visual navigation, a renderable neural radiance map (RNR-Map), which is designed to contain the overall visual information of a 3D environment. The RNR-Map has a grid form and consists of latent codes at each pixel. These latent codes are embedded from image observations, and can be converted to the neural radiance field which enables image rendering given a camera pose. The recorded latent codes implicitly contain visual information about the environment, which makes the RNR-Map visually descriptive. This visual information in RNR-Map can be a useful guideline for visual localization and navigation. We develop localization and navigation frameworks that can effectively utilize the RNR-Map. We evaluate the proposed frameworks on camera tracking, visual localization, and image-goal navigation. Experimental results show that the RNR-Map-based localization framework can find the target location based on a single query image with fast speed and competitive accuracy compared to other baselines. Also, this localization framework is robust to environmental changes, and even finds the most visually similar places when a query image from a different environment is given. The proposed navigation framework outperforms the existing image-goal navigation methods in difficult scenarios, under odometry and actuation noises. The … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Click-based interactive segmentation (IS) aims to extract the target objects under user interaction. For this task, most of the current deep learning (DL)-based methods mainly follow the general pipelines of semantic segmentation. Albeit achieving promising performance, they do not fully and explicitly utilize and propagate the click information, inevitably leading to unsatisfactory segmentation results, even at clicked points. Against this issue, in this paper, we propose to formulate the IS task as a Gaussian process (GP)-based pixel-wise binary classification model on each image. To solve this model, we utilize amortized variational inference to approximate the intractable GP posterior in a data-driven manner and then decouple the approximated GP posterior into double space forms for efficient sampling with linear complexity. Then, we correspondingly construct a GP classification framework, named GPCIS, which is integrated with the deep kernel learning mechanism for more flexibility. The main specificities of the proposed GPCIS lie in: 1) Under the explicit guidance of the derived GP posterior, the information contained in clicks can be finely propagated to the entire image and then boost the segmentation; 2) The accuracy of predictions at clicks has good theoretical support. These merits of GPCIS as well as its good generality and … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Transformers-based methods have achieved significant performance in image deraining as they can model the non-local information which is vital for high-quality image reconstruction. In this paper, we find that most existing Transformers usually use all similarities of the tokens from the query-key pairs for the feature aggregation. However, if the tokens from the query are different from those of the key, the self-attention values estimated from these tokens also involve in feature aggregation, which accordingly interferes with the clear image restoration. To overcome this problem, we propose an effective DeRaining network, Sparse Transformer (DRSformer) that can adaptively keep the most useful self-attention values for feature aggregation so that the aggregated features better facilitate high-quality image reconstruction. Specifically, we develop a learnable top-k selection operator to adaptively retain the most crucial attention scores from the keys for each query for better feature aggregation. Simultaneously, as the naive feed-forward network in Transformers does not model the multi-scale information that is important for latent clear image restoration, we develop an effective mixed-scale feed-forward network to generate better features for image deraining. To learn an enriched set of hybrid features, which combines local context from CNN operators, we equip our model with mixture of … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 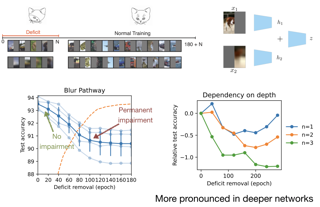
We show that the ability of a neural network to integrate information from diverse sources hinges critically on being exposed to properly correlated signals during the early phases of training. Interfering with the learning process during this initial stage can permanently impair the development of a skill, both in artificial and biological systems where the phenomenon is known as a critical learning period. We show that critical periods arise from the complex and unstable early transient dynamics, which are decisive of final performance of the trained system and their learned representations. This evidence challenges the view, engendered by analysis of wide and shallow networks, that early learning dynamics of neural networks are simple, akin to those of a linear model. Indeed, we show that even deep linear networks exhibit critical learning periods for multi-source integration, while shallow networks do not. To better understand how the internal representations change according to disturbances or sensory deficits, we introduce a new measure of source sensitivity, which allows us to track the inhibition and integration of sources during training. Our analysis of inhibition suggests cross-source reconstruction as a natural auxiliary training objective, and indeed we show that architectures trained with cross-sensor reconstruction objectives are … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
This paper presents a novel grid-based NeRF called F^2-NeRF (Fast-Free-NeRF) for novel view synthesis, which enables arbitrary input camera trajectories and only costs a few minutes for training. Existing fast grid-based NeRF training frameworks, like Instant-NGP, Plenoxels, DVGO, or TensoRF, are mainly designed for bounded scenes and rely on space warping to handle unbounded scenes. Existing two widely-used space-warping methods are only designed for the forward-facing trajectory or the 360° object-centric trajectory but cannot process arbitrary trajectories. In this paper, we delve deep into the mechanism of space warping to handle unbounded scenes. Based on our analysis, we further propose a novel space-warping method called perspective warping, which allows us to handle arbitrary trajectories in the grid-based NeRF framework. Extensive experiments demonstrate that F^2-NeRF is able to use the same perspective warping to render high-quality images on two standard datasets and a new free trajectory dataset collected by us. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] The Lucas-Kanade (LK) method is a classic iterative homography estimation algorithm for image alignment, but often suffers from poor local optimality especially when image pairs have large distortions. To address this challenge, in this paper we propose a novel Deep Star-Convexified Lucas-Kanade (PRISE)} method for multimodel image alignment by introducing strongly star-convex constraints into the optimization problem. Our basic idea is to enforce the neural network to approximately learn a star-convex loss landscape around the ground truth give any data to facilitate the convergence of the LK method to the ground truth through the high dimensional space defined by the network. This leads to a minimax learning problem, with contrastive (hinge) losses due to the definition of strong star-convexity that are appended to the original loss for training. We also provide an efficient sampling based algorithm to leverage the training cost, as well as some analysis on the quality of the solutions from PRISE. We further evaluate our approach on benchmark datasets such as MSCOCO, GoogleEarth, and GoogleMap, and demonstrate state-of-the-art results, especially for small pixel errors. Demo code is attached. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
A natural image frequently contains multiple classification targets, accordingly providing multiple class labels rather than a single label per image. While the single-label classification is effectively addressed by applying a softmax cross-entropy loss, the multi-label task is tackled mainly in a binary cross-entropy (BCE) framework. In contrast to the softmax loss, the BCE loss involves issues regarding imbalance as multiple classes are decomposed into a bunch of binary classifications; recent works improve the BCE loss to cope with the issue by means of weighting. In this paper, we propose a multi-label loss by bridging a gap between the softmax loss and the multi-label scenario. The proposed loss function is formulated on the basis of relative comparison among classes which also enables us to further improve discriminative power of features by enhancing classification margin. The loss function is so flexible as to be applicable to a multi-label setting in two ways for discriminating classes as well as samples. In the experiments on multi-label classification, the proposed method exhibits competitive performance to the other multi-label losses, and it also provides transferrable features on single-label ImageNet training. Codes are available at https://github.com/tk1980/TwowayMultiLabelLoss. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Dataset distillation, also known as dataset condensation, aims to compress a large dataset into a compact synthetic one. Existing methods perform dataset condensation by assuming a fixed storage or transmission budget. When the budget changes, however, they have to repeat the synthesizing process with access to original datasets, which is highly cumbersome if not infeasible at all. In this paper, we explore the problem of slimmable dataset condensation, to extract a smaller synthetic dataset given only previous condensation results. We first study the limitations of existing dataset condensation algorithms on such a successive compression setting and identify two key factors: (1) the inconsistency of neural networks over different compression times and (2) the underdetermined solution space for synthetic data. Accordingly, we propose a novel training objective for slimmable dataset condensation to explicitly account for both factors. Moreover, synthetic datasets in our method adopt an significance-aware parameterization. Theoretical derivation indicates that an upper-bounded error can be achieved by discarding the minor components without training. Alternatively, if training is allowed, this strategy can serve as a strong initialization that enables a fast convergence. Extensive comparisons and ablations demonstrate the superiority of the proposed solution over existing methods on multiple benchmarks. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In this paper, we introduce SDM-UniPS, a groundbreaking Scalable, Detailed, Mask-free, and Universal Photometric Stereo network. Our approach can recover astonishingly intricate surface normal maps, rivaling the quality of 3D scanners, even when images are captured under unknown, spatially-varying lighting conditions in uncontrolled environments. We have extended previous universal photometric stereo networks to extract spatial-light features, utilizing all available information in high-resolution input images and accounting for non-local interactions among surface points. Moreover, we present a new synthetic training dataset that encompasses a diverse range of shapes, materials, and illumination scenarios found in real-world scenes. Through extensive evaluation, we demonstrate that our method not only surpasses calibrated, lighting-specific techniques on public benchmarks, but also excels with a significantly smaller number of input images even without object masks. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 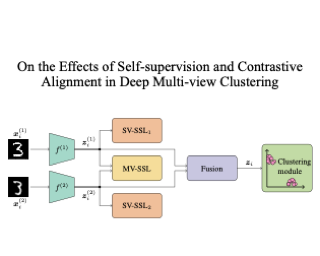
Self-supervised learning is a central component in recent approaches to deep multi-view clustering (MVC). However, we find large variations in the development of self-supervision-based methods for deep MVC, potentially slowing the progress of the field. To address this, we present DeepMVC, a unified framework for deep MVC that includes many recent methods as instances. We leverage our framework to make key observations about the effect of self-supervision, and in particular, drawbacks of aligning representations with contrastive learning. Further, we prove that contrastive alignment can negatively influence cluster separability, and that this effect becomes worse when the number of views increases. Motivated by our findings, we develop several new DeepMVC instances with new forms of self-supervision. We conduct extensive experiments and find that (i) in line with our theoretical findings, contrastive alignments decreases performance on datasets with many views; (ii) all methods benefit from some form of self-supervision; and (iii) our new instances outperform previous methods on several datasets. Based on our results, we suggest several promising directions for future research. To enhance the openness of the field, we provide an open-source implementation of DeepMVC, including recent models and our new instances. Our implementation includes a consistent evaluation protocol, facilitating fair … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 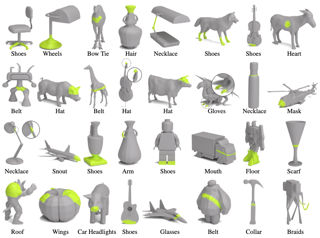
We present 3D Highlighter, a technique for localizing semantic regions on a mesh using text as input. A key feature of our system is the ability to interpret “out-of-domain” localizations. Our system demonstrates the ability to reason about where to place non-obviously related concepts on an input 3D shape, such as adding clothing to a bare 3D animal model. Our method contextualizes the text description using a neural field and colors the corresponding region of the shape using a probability-weighted blend. Our neural optimization is guided by a pre-trained CLIP encoder, which bypasses the need for any 3D datasets or 3D annotations. Thus, 3D Highlighter is highly flexible, general, and capable of producing localizations on a myriad of input shapes. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 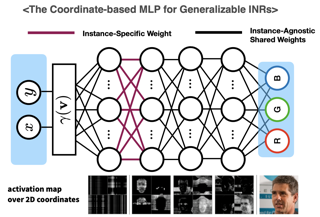
Despite recent advances in implicit neural representations (INRs), it remains challenging for a coordinate-based multi-layer perceptron (MLP) of INRs to learn a common representation across data instances and generalize it for unseen instances. In this work, we introduce a simple yet effective framework for generalizable INRs that enables a coordinate-based MLP to represent complex data instances by modulating only a small set of weights in an early MLP layer as an instance pattern composer; the remaining MLP weights learn pattern composition rules to learn common representations across instances. Our generalizable INR framework is fully compatible with existing meta-learning and hypernetworks in learning to predict the modulated weight for unseen instances. Extensive experiments demonstrate that our method achieves high performance on a wide range of domains such as an audio, image, and 3D object, while the ablation study validates our weight modulation. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 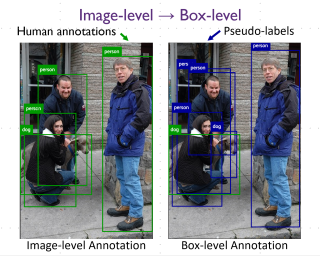
Active learning selects informative samples for annotation within budget, which has proven efficient recently on object detection. However, the widely used active detection benchmarks conduct image-level evaluation, which is unrealistic in human workload estimation and biased towards crowded images. Furthermore, existing methods still perform image-level annotation, but equally scoring all targets within the same image incurs waste of budget and redundant labels. Having revealed above problems and limitations, we introduce a box-level active detection framework that controls a box-based budget per cycle, prioritizes informative targets and avoids redundancy for fair comparison and efficient application. Under the proposed box-level setting, we devise a novel pipeline, namely Complementary Pseudo Active Strategy (ComPAS). It exploits both human annotations and the model intelligence in a complementary fashion: an efficient input-end committee queries labels for informative objects only; meantime well-learned targets are identified by the model and compensated with pseudo-labels. ComPAS consistently outperforms 10 competitors under 4 settings in a unified codebase. With supervision from labeled data only, it achieves 100% supervised performance of VOC0712 with merely 19% box annotations. On the COCO dataset, it yields up to 4.3% mAP improvement over the second-best method. ComPAS also supports training with the unlabeled pool, where it … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
A fully automated object reconstruction pipeline is crucial for digital content creation. While the area of 3D reconstruction has witnessed profound developments, the removal of background to obtain a clean object model still relies on different forms of manual labor, such as bounding box labeling, mask annotations, and mesh manipulations. In this paper, we propose a novel framework named AutoRecon for the automated discovery and reconstruction of an object from multi-view images. We demonstrate that foreground objects can be robustly located and segmented from SfM point clouds by leveraging self-supervised 2D vision transformer features. Then, we reconstruct decomposed neural scene representations with dense supervision provided by the decomposed point clouds, resulting in accurate object reconstruction and segmentation. Experiments on the DTU, BlendedMVS and CO3D-V2 datasets demonstrate the effectiveness and robustness of AutoRecon. The code and supplementary material are available on the project page: https://zju3dv.github.io/autorecon/. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 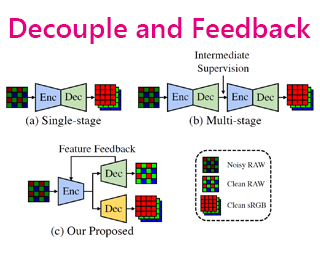
The exclusive properties of RAW data have shown great potential for low-light image enhancement. Nevertheless, the performance is bottlenecked by the inherent limitations of existing architectures in both single-stage and multi-stage methods. Mixed mapping across two different domains, noise-to-clean and RAW-to-sRGB, misleads the single-stage methods due to the domain ambiguity. The multi-stage methods propagate the information merely through the resulting image of each stage, neglecting the abundant features in the lossy image-level dataflow. In this paper, we probe a generalized solution to these bottlenecks and propose a Decouple aNd Feedback framework, abbreviated as DNF. To mitigate the domain ambiguity, domainspecific subtasks are decoupled, along with fully utilizing the unique properties in RAW and sRGB domains. The feature propagation across stages with a feedback mechanism avoids the information loss caused by image-level dataflow. The two key insights of our method resolve the inherent limitations of RAW data-based low-light image enhancement satisfactorily, empowering our method to outperform the previous state-of-the-art method by a large margin with only 19% parameters, achieving 0.97dB and 1.30dB PSNR improvements on the Sony and Fuji subsets of SID. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Generic image inpainting aims to complete a corrupted image by borrowing surrounding information, which barely generates novel content. By contrast, multi-modal inpainting provides more flexible and useful controls on the inpainted content, e.g., a text prompt can be used to describe an object with richer attributes, and a mask can be used to constrain the shape of the inpainted object rather than being only considered as a missing area. We propose a new diffusion-based model named SmartBrush for completing a missing region with an object using both text and shape-guidance. While previous work such as DALLE-2 and Stable Diffusion can do text-guided inapinting they do not support shape guidance and tend to modify background texture surrounding the generated object. Our model incorporates both text and shape guidance with precision control. To preserve the background better, we propose a novel training and sampling strategy by augmenting the diffusion U-net with object-mask prediction. Lastly, we introduce a multi-task training strategy by jointly training inpainting with text-to-image generation to leverage more training data. We conduct extensive experiments showing that our model outperforms all baselines in terms of visual quality, mask controllability, and background preservation. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In this paper, we focus on the problem of rendering novel views from a Neural Radiance Field (NeRF) under unobserved light conditions. To this end, we introduce a novel dataset, dubbed ReNe (Relighting NeRF), framing real world objects under one-light-at-time (OLAT) conditions, annotated with accurate ground-truth camera and light poses. Our acquisition pipeline leverages two robotic arms holding, respectively, a camera and an omni-directional point-wise light source. We release a total of 20 scenes depicting a variety of objects with complex geometry and challenging materials. Each scene includes 2000 images, acquired from 50 different points of views under 40 different OLAT conditions. By leveraging the dataset, we perform an ablation study on the relighting capability of variants of the vanilla NeRF architecture and identify a lightweight architecture that can render novel views of an object under novel light conditions, which we use to establish a non-trivial baseline for the dataset. Dataset and benchmark are available at https://eyecan-ai.github.io/rene. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 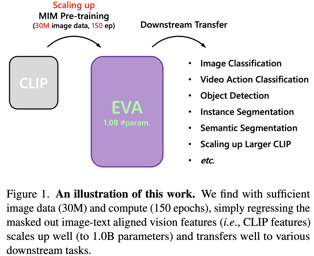
We launch EVA, a vision-centric foundation model to explore the limits of visual representation at scale using only publicly accessible data. EVA is a vanilla ViT pre-trained to reconstruct the masked out image-text aligned vision features conditioned on visible image patches. Via this pretext task, we can efficiently scale up EVA to one billion parameters, and sets new records on a broad range of representative vision downstream tasks, such as image recognition, video action recognition, object detection, instance segmentation and semantic segmentation without heavy supervised training. Moreover, we observe quantitative changes in scaling EVA result in qualitative changes in transfer learning performance that are not present in other models. For instance, EVA takes a great leap in the challenging large vocabulary instance segmentation task: our model achieves almost the same state-of-the-art performance on LVIS dataset with over a thousand categories and COCO dataset with only eighty categories. Beyond a pure vision encoder, EVA can also serve as a vision-centric, multi-modal pivot to connect images and text. We find initializing the vision tower of a giant CLIP from EVA can greatly stabilize the training and outperform the training from scratch counterpart with much fewer samples and less compute, providing a new … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 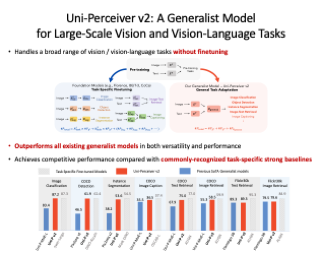
Despite the remarkable success of foundation models, their task-specific fine-tuning paradigm makes them inconsistent with the goal of general perception modeling. The key to eliminating this inconsistency is to use generalist models for general task modeling. However, existing attempts at generalist models are inadequate in both versatility and performance. In this paper, we propose Uni-Perceiver v2, which is the first generalist model capable of handling major large-scale vision and vision-language tasks with competitive performance. Specifically, images are encoded as general region proposals, while texts are encoded via a Transformer-based language model. The encoded representations are transformed by a task-agnostic decoder. Different tasks are formulated as a unified maximum likelihood estimation problem. We further propose an effective optimization technique named Task-Balanced Gradient Normalization to ensure stable multi-task learning with an unmixed sampling strategy, which is helpful for tasks requiring large batch-size training. After being jointly trained on various tasks, Uni-Perceiver v2 is capable of directly handling downstream tasks without any task-specific adaptation. Results show that Uni-Perceiver v2 outperforms all existing generalist models in both versatility and performance. Meanwhile, compared with the commonly-recognized strong baselines that require tasks-specific fine-tuning, Uni-Perceiver v2 achieves competitive performance on a broad range of vision and vision-language … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 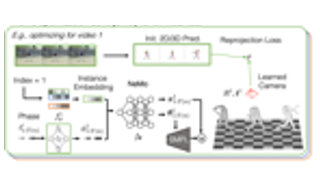
The task of reconstructing 3D human motion has wide-ranging applications. The gold standard Motion capture (MoCap) systems are accurate but inaccessible to the general public due to their cost, hardware, and space constraints. In contrast, monocular human mesh recovery (HMR) methods are much more accessible than MoCap as they take single-view videos as inputs. Replacing the multi-view MoCap systems with a monocular HMR method would break the current barriers to collecting accurate 3D motion thus making exciting applications like motion analysis and motion-driven animation accessible to the general public. However, the performance of existing HMR methods degrades when the video contains challenging and dynamic motion that is not in existing MoCap datasets used for training. This reduces its appeal as dynamic motion is frequently the target in 3D motion recovery in the aforementioned applications. Our study aims to bridge the gap between monocular HMR and multi-view MoCap systems by leveraging information shared across multiple video instances of the same action. We introduce the Neural Motion (NeMo) field. It is optimized to represent the underlying 3D motions across a set of videos of the same action. Empirically, we show that NeMo can recover 3D motion in sports using videos from the … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 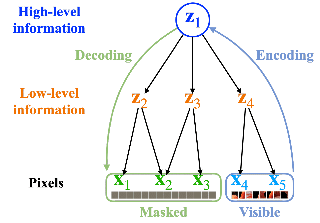
Masked autoencoder (MAE), a simple and effective self-supervised learning framework based on the reconstruction of masked image regions, has recently achieved prominent success in a variety of vision tasks. Despite the emergence of intriguing empirical observations on MAE, a theoretically principled understanding is still lacking. In this work, we formally characterize and justify existing empirical insights and provide theoretical guarantees of MAE. We formulate the underlying data-generating process as a hierarchical latent variable model, and show that under reasonable assumptions, MAE provably identifies a set of latent variables in the hierarchical model, explaining why MAE can extract high-level information from pixels. Further, we show how key hyperparameters in MAE (the masking ratio and the patch size) determine which true latent variables to be recovered, therefore influencing the level of semantic information in the representation. Specifically, extremely large or small masking ratios inevitably lead to low-level representations. Our theory offers coherent explanations of existing empirical observations and provides insights for potential empirical improvements and fundamental limitations of the masked-reconstruction paradigm. We conduct extensive experiments to validate our theoretical insights. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We introduce PLIKS (Pseudo-Linear Inverse Kinematic Solver) for reconstruction of a 3D mesh of the human body from a single 2D image. Current techniques directly regress the shape, pose, and translation of a parametric model from an input image through a non-linear mapping with minimal flexibility to any external influences. We approach the task as a model-in-the-loop optimization problem. PLIKS is built on a linearized formulation of the parametric SMPL model. Using PLIKS, we can analytically reconstruct the human model via 2D pixel-aligned vertices. This enables us with the flexibility to use accurate camera calibration information when available. PLIKS offers an easy way to introduce additional constraints such as shape and translation. We present quantitative evaluations which confirm that PLIKS achieves more accurate reconstruction with greater than 10% improvement compared to other state-of-the-art methods with respect to the standard 3D human pose and shape benchmarks while also obtaining a reconstruction error improvement of 12.9 mm on the newer AGORA dataset. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Planes are generally used in 3D reconstruction for depth sensors, such as RGB-D cameras and LiDARs. This paper focuses on the problem of estimating the optimal planes and sensor poses to minimize the point-to-plane distance. The resulting least-squares problem is referred to as plane adjustment (PA) in the literature, which is the counterpart of bundle adjustment (BA) in visual reconstruction. Iterative methods are adopted to solve these least-squares problems. Typically, Newton’s method is rarely used for a large-scale least-squares problem, due to the high computational complexity of the Hessian matrix. Instead, methods using an approximation of the Hessian matrix, such as the Levenberg-Marquardt (LM) method, are generally adopted. This paper adopts the Newton’s method to efficiently solve the PA problem. Specifically, given poses, the optimal plane have a close-form solution. Thus we can eliminate planes from the cost function, which significantly reduces the number of variables. Furthermore, as the optimal planes are functions of poses, this method actually ensures that the optimal planes for the current estimated poses can be obtained at each iteration, which benefits the convergence. The difficulty lies in how to efficiently compute the Hessian matrix and the gradient of the resulting cost. This paper provides an … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
A meaningful video is semantically coherent and changes smoothly. However, most existing fine-grained video representation learning methods learn frame-wise features by aligning frames across videos or exploring relevance between multiple views, neglecting the inherent dynamic process of each video. In this paper, we propose to learn video representations by modeling Video as Stochastic Processes (VSP) via a novel process-based contrastive learning framework, which aims to discriminate between video processes and simultaneously capture the temporal dynamics in the processes. Specifically, we enforce the embeddings of the frame sequence of interest to approximate a goal-oriented stochastic process, i.e., Brownian bridge, in the latent space via a process-based contrastive loss. To construct the Brownian bridge, we adapt specialized sampling strategies under different annotations for both self-supervised and weakly-supervised learning. Experimental results on four datasets show that VSP stands as a state-of-the-art method for various video understanding tasks, including phase progression, phase classification and frame retrieval. Code is available at ‘https://github.com/hengRUC/VSP’. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
This paper presents a new framework for open-vocabulary semantic segmentation with the pre-trained vision-language model, named SAN. Our approach models the semantic segmentation task as a region recognition problem. A side network is attached to a frozen CLIP model with two branches: one for predicting mask proposals, and the other for predicting attention bias which is applied in the CLIP model to recognize the class of masks. This decoupled design has the benefit CLIP in recognizing the class of mask proposals. Since the attached side network can reuse CLIP features, it can be very light. In addition, the entire network can be trained end-to-end, allowing the side network to be adapted to the frozen CLIP model, which makes the predicted mask proposals CLIP-aware. Our approach is fast, accurate, and only adds a few additional trainable parameters. We evaluate our approach on multiple semantic segmentation benchmarks. Our method significantly outperforms other counterparts, with up to 18 times fewer trainable parameters and 19 times faster inference speed. We hope our approach will serve as a solid baseline and help ease future research in open-vocabulary semantic segmentation. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Methane (CH 4 ) is the chief contributor to global climate change. Recent Airborne Visible-Infrared Imaging Spectrometer-Next Generation (AVIRIS-NG) has been very useful in quantitative mapping of methane emissions. Existing methods for analyzing this data are sensitive to local terrain conditions, often require manual inspection from domain experts, prone to significant error and hence are not scalable. To address these challenges, we propose a novel end-to-end spectral absorption wavelength aware transformer network, MethaneMapper, to detect and quantify the emissions. MethaneMapper introduces two novel modules that help to locate the most relevant methane plume regions in the spectral domain and uses them to localize these accurately. Thorough evaluation shows that MethaneMapper achieves 0.63 mAP in detection and reduces the model size (by 5×) compared to the current state of the art. In addition, we also introduce a large-scale dataset of methane plume segmentation mask for over 1200 AVIRIS-NG flightlines from 2015-2022. It contains over 4000 methane plume sites. Our dataset will provide researchers the opportunity to develop and advance new methods for tackling this challenging green-house gas detection problem with significant broader social impact. Dataset and source code link. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We develop an effective point cloud rendering pipeline for novel view synthesis, which enables high fidelity local detail reconstruction, real-time rendering and user-friendly editing. In the heart of our pipeline is an adaptive frequency modulation module called Adaptive Frequency Net (AFNet), which utilizes a hypernetwork to learn the local texture frequency encoding that is consecutively injected into adaptive frequency activation layers to modulate the implicit radiance signal. This mechanism improves the frequency expressive ability of the network with richer frequency basis support, only at a small computational budget. To further boost performance, a preprocessing module is also proposed for point cloud geometry optimization via point opacity estimation. In contrast to implicit rendering, our pipeline supports high-fidelity interactive editing based on point cloud manipulation. Extensive experimental results on NeRF-Synthetic, ScanNet, DTU and Tanks and Temples datasets demonstrate the superior performances achieved by our method in terms of PSNR, SSIM and LPIPS, in comparison to the state-of-the-art. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
In this work, we tackle the challenging problem of learning-based single-view 3D hair modeling. Due to the great difficulty of collecting paired real image and 3D hair data, using synthetic data to provide prior knowledge for real domain becomes a leading solution. This unfortunately introduces the challenge of domain gap. Due to the inherent difficulty of realistic hair rendering, existing methods typically use orientation maps instead of hair images as input to bridge the gap. We firmly think an intermediate representation is essential, but we argue that orientation map using the dominant filtering-based methods is sensitive to uncertain noise and far from a competent representation. Thus, we first raise this issue up and propose a novel intermediate representation, termed as HairStep, which consists of a strand map and a depth map. It is found that HairStep not only provides sufficient information for accurate 3D hair modeling, but also is feasible to be inferred from real images. Specifically, we collect a dataset of 1,250 portrait images with two types of annotations. A learning framework is further designed to transfer real images to the strand map and depth map. It is noted that, an extra bonus of our new dataset is the … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] Recent research in robust optimization has shown an overfitting-like phenomenon in which models trained against adversarial attacks exhibit higher robustness on the training set compared to the test set. Although previous work provided theoretical explanations for this phenomenon using a robust PAC-Bayesian bound over the adversarial test error, related algorithmic derivations are at best only loosely connected to this bound, which implies that there is still a gap between their empirical success and our understanding of adversarial robustness theory. To close this gap, in this paper we consider a different form of the robust PAC-Bayesian bound and directly minimize it with respect to the model posterior. The derivation of the optimal solution connects PAC-Bayesian learning to the geometry of the robust loss surface through a Trace of Hessian (TrH) regularizer that measures the surface flatness. In practice, we restrict the TrH regularizer to the top layer only, which results in an analytical solution to the bound whose computational cost does not depend on the network depth. Finally, we evaluate our TrH regularization approach over CIFAR-10/100 and ImageNet using Vision Transformers (ViT) and compare against baseline adversarial robustness algorithms. Experimental results show that TrH regularization leads to improved ViT robustness that … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] Reflective flare is a phenomenon that occurs when light reflects inside lenses, causing bright spots or a “ghosting effect” in photos, which can impact their quality. Eliminating reflective flare is highly desirable but challenging. Many existing methods rely on manually designed features to detect these bright spots, but they often fail to identify reflective flares created by various types of light and may even mistakenly remove the light sources in scenarios with multiple light sources. To address these challenges, we propose an optical center symmetry prior, which suggests that the reflective flare and light source are always symmetrical around the lens’s optical center. This prior helps to locate the reflective flare’s proposal region more accurately and can be applied to most smartphone cameras. Building on this prior, we create the first reflective flare removal dataset called BracketFlare, which contains diverse and realistic reflective flare patterns. We use continuous bracketing to capture the reflective flare pattern in the underexposed image and combine it with a normally exposed image to synthesize a pair of flare-corrupted and flare-free images. With the dataset, neural networks can be trained to remove the reflective flares effectively. Extensive experiments demonstrate the effectiveness of our method on both … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
3D-aware generative adversarial networks (GANs) synthesize high-fidelity and multi-view-consistent facial images using only collections of single-view 2D imagery. Towards fine-grained control over facial attributes, recent efforts incorporate 3D Morphable Face Model (3DMM) to describe deformation in generative radiance fields either explicitly or implicitly. Explicit methods provide fine-grained expression control but cannot handle topological changes caused by hair and accessories, while implicit ones can model varied topologies but have limited generalization caused by the unconstrained deformation fields. We propose a novel 3D GAN framework for unsupervised learning of generative, high-quality and 3D-consistent facial avatars from unstructured 2D images. To achieve both deformation accuracy and topological flexibility, we propose a 3D representation called Generative Texture-Rasterized Tri-planes. The proposed representation learns Generative Neural Textures on top of parametric mesh templates and then projects them into three orthogonal-viewed feature planes through rasterization, forming a tri-plane feature representation for volume rendering. In this way, we combine both fine-grained expression control of mesh-guided explicit deformation and the flexibility of implicit volumetric representation. We further propose specific modules for modeling mouth interior which is not taken into account by 3DMM. Our method demonstrates state-of-the-art 3Daware synthesis quality and animation ability through extensive experiments. Furthermore, serving as 3D … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
3D scene understanding has seen significant advances in recent years, but has largely focused on object understanding in 3D scenes with independent per-object predictions. We thus propose to learn Neural Part Priors (NPPs), parametric spaces of objects and their parts, that enable optimizing to fit to a new input 3D scan geometry with global scene consistency constraints. The rich structure of our NPPs enables accurate, holistic scene reconstruction across similar objects in the scene. Both objects and their part geometries are characterized by coordinate field MLPs, facilitating optimization at test time to fit to input geometric observations as well as similar objects in the input scan. This enables more accurate reconstructions than independent per-object predictions as a single forward pass, while establishing global consistency within a scene. Experiments on the ScanNet dataset demonstrate that NPPs significantly outperforms the state-of-the-art in part decomposition and object completion in real-world scenes. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present ARTrack, an autoregressive framework for visual object tracking. ARTrack tackles tracking as a coordinate sequence interpretation task that estimates object trajectories progressively, where the current estimate is induced by previous states and in turn affects subsequences. This time-autoregressive approach models the sequential evolution of trajectories to keep tracing the object across frames, making it superior to existing template matching based trackers that only consider the per-frame localization accuracy. ARTrack is simple and direct, eliminating customized localization heads and post-processings. Despite its simplicity, ARTrack achieves state-of-the-art performance on prevailing benchmark datasets. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The increasing tendency to collect large and uncurated datasets to train vision-and-language models has raised concerns about fair representations. It is known that even small but manually annotated datasets, such as MSCOCO, are affected by societal bias. This problem, far from being solved, may be getting worse with data crawled from the Internet without much control. In addition, the lack of tools to analyze societal bias in big collections of images makes addressing the problem extremely challenging. Our first contribution is to annotate part of the Google Conceptual Captions dataset, widely used for training vision-and-language models, with four demographic and two contextual attributes. Our second contribution is to conduct a comprehensive analysis of the annotations, focusing on how different demographic groups are represented. Our last contribution lies in evaluating three prevailing vision-and-language tasks: image captioning, text-image CLIP embeddings, and text-to-image generation, showing that societal bias is a persistent problem in all of them. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
For years, researchers have been devoted to generalizable object perception and manipulation, where cross-category generalizability is highly desired yet underexplored. In this work, we propose to learn such cross-category skills via Generalizable and Actionable Parts (GAParts). By identifying and defining 9 GAPart classes (lids, handles, etc.) in 27 object categories, we construct a large-scale part-centric interactive dataset, GAPartNet, where we provide rich, part-level annotations (semantics, poses) for 8,489 part instances on 1,166 objects. Based on GAPartNet, we investigate three cross-category tasks: part segmentation, part pose estimation, and part-based object manipulation. Given the significant domain gaps between seen and unseen object categories, we propose a robust 3D segmentation method from the perspective of domain generalization by integrating adversarial learning techniques. Our method outperforms all existing methods by a large margin, no matter on seen or unseen categories. Furthermore, with part segmentation and pose estimation results, we leverage the GAPart pose definition to design part-based manipulation heuristics that can generalize well to unseen object categories in both the simulator and the real world. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Recent 3D face reconstruction methods have made significant advances in geometry prediction, yet further cosmetic improvements are limited by lagged albedo because inferring albedo from appearance is an ill-posed problem. Although some existing methods consider prior knowledge from illumination to improve albedo estimation, they still produce a light-skin bias due to racially biased albedo models and limited light constraints. In this paper, we reconsider the relationship between albedo and face attributes and propose an ID2Albedo to directly estimate albedo without constraining illumination. Our key insight is that intrinsic semantic attributes such as race, skin color, and age can constrain the albedo map. We first introduce visual-textual cues and design a semantic loss to supervise facial albedo estimation. Specifically, we pre-define text labels such as race, skin color, age, and wrinkles. Then, we employ the text-image model (CLIP) to compute the similarity between the text and the input image, and assign a pseudo-label to each facial image. We constrain generated albedos in the training phase to have the same attributes as the inputs. In addition, we train a high-quality, unbiased facial albedo generator and utilize the semantic loss to learn the mapping from illumination-robust identity features to the albedo latent codes. … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 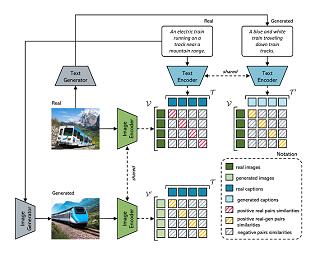
The CLIP model has been recently proven to be very effective for a variety of cross-modal tasks, including the evaluation of captions generated from vision-and-language architectures. In this paper, we propose a new recipe for a contrastive-based evaluation metric for image captioning, namely Positive-Augmented Contrastive learning Score (PAC-S), that in a novel way unifies the learning of a contrastive visual-semantic space with the addition of generated images and text on curated data. Experiments spanning several datasets demonstrate that our new metric achieves the highest correlation with human judgments on both images and videos, outperforming existing reference-based metrics like CIDEr and SPICE and reference-free metrics like CLIP-Score. Finally, we test the system-level correlation of the proposed metric when considering popular image captioning approaches, and assess the impact of employing different cross-modal features. Our source code and trained models are publicly available at: https://github.com/aimagelab/pacscore. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Learning high-quality, self-supervised, visual representations is essential to advance the role of computer vision in biomedical microscopy and clinical medicine. Previous work has focused on self-supervised representation learning (SSL) methods developed for instance discrimination and applied them directly to image patches, or fields-of-view, sampled from gigapixel whole-slide images (WSIs) used for cancer diagnosis. However, this strategy is limited because it (1) assumes patches from the same patient are independent, (2) neglects the patient-slide-patch hierarchy of clinical biomedical microscopy, and (3) requires strong data augmentations that can degrade downstream performance. Importantly, sampled patches from WSIs of a patient’s tumor are a diverse set of image examples that capture the same underlying cancer diagnosis. This motivated HiDisc, a data-driven method that leverages the inherent patient-slide-patch hierarchy of clinical biomedical microscopy to define a hierarchical discriminative learning task that implicitly learns features of the underlying diagnosis. HiDisc uses a self-supervised contrastive learning framework in which positive patch pairs are defined based on a common ancestry in the data hierarchy, and a unified patch, slide, and patient discriminative learning objective is used for visual SSL. We benchmark HiDisc visual representations on two vision tasks using two biomedical microscopy datasets, and demonstrate that (1) HiDisc … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Most current RGB-T trackers adopt a two-stream structure to extract unimodal RGB and thermal features and complex fusion strategies to achieve multi-modal feature fusion, which require a huge number of parameters, thus hindering their real-life applications. On the other hand, a compact RGB-T tracker may be computationally efficient but encounter non-negligible performance degradation, due to the weakening of feature representation ability. To remedy this situation, a cross-modality distillation framework is presented to bridge the performance gap between a compact tracker and a powerful tracker. Specifically, a specific-common feature distillation module is proposed to transform the modality-common information as well as the modality-specific information from a deeper two-stream network to a shallower single-stream network. In addition, a multi-path selection distillation module is proposed to instruct a simple fusion module to learn more accurate multi-modal information from a well-designed fusion mechanism by using multiple paths. We validate the effectiveness of our method with extensive experiments on three RGB-T benchmarks, which achieves state-of-the-art performance but consumes much less computational resources. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present MotionDiffuser, a diffusion based representation for the joint distribution of future trajectories over multiple agents. Such representation has several key advantages: first, our model learns a highly multimodal distribution that captures diverse future outcomes. Second, the simple predictor design requires only a single L2 loss training objective, and does not depend on trajectory anchors. Third, our model is capable of learning the joint distribution for the motion of multiple agents in a permutation-invariant manner. Furthermore, we utilize a compressed trajectory representation via PCA, which improves model performance and allows for efficient computation of the exact sample log probability. Subsequently, we propose a general constrained sampling framework that enables controlled trajectory sampling based on differentiable cost functions. This strategy enables a host of applications such as enforcing rules and physical priors, or creating tailored simulation scenarios. MotionDiffuser can be combined with existing backbone architectures to achieve top motion forecasting results. We obtain state-of-the-art results for multi-agent motion prediction on the Waymo Open Motion Dataset. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Confidence-based pseudo-labeling is among the dominant approaches in semi-supervised learning (SSL). It relies on including high-confidence predictions made on unlabeled data as additional targets to train the model. We propose ProtoCon, a novel SSL method aimed at the less-explored label-scarce SSL where such methods usually underperform. ProtoCon refines the pseudo-labels by leveraging their nearest neighbours’ information. The neighbours are identified as the training proceeds using an online clustering approach operating in an embedding space trained via a prototypical loss to encourage well-formed clusters. The online nature of ProtoCon allows it to utilise the label history of the entire dataset in one training cycle to refine labels in the following cycle without the need to store image embeddings. Hence, it can seamlessly scale to larger datasets at a low cost. Finally, ProtoCon addresses the poor training signal in the initial phase of training (due to fewer confident predictions) by introducing an auxiliary self-supervised loss. It delivers significant gains and faster convergence over state-of-the-art across 5 datasets, including CIFARs, ImageNet and DomainNet. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] Few-shot semantic segmentation (FSS) aims to form class-agnostic models segmenting unseen classes with only a handful of annotations. Previous methods limited to the semantic feature and prototype representation suffer from coarse segmentation granularity and train-set overfitting. In this work, we design Hierarchically Decoupled Matching Network (HDMNet) mining pixel-level support correlation based on the transformer architecture. The self-attention modules are used to assist in establishing hierarchical dense features, as a means to accomplish the cascade matching between query and support features. Moreover, we propose a matching module to reduce train-set overfitting and introduce correlation distillation leveraging semantic correspondence from coarse resolution to boost fine-grained segmentation. Our method performs decently in experiments. We achieve 50.0% mIoU on COCO-5i dataset one-shot setting and 56.0% on five-shot segmentation, respectively. The code is available on the project website. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Neural radiance fields (NeRF) excel at synthesizing new views given multi-view, calibrated images of a static scene. When scenes include distractors, which are not persistent during image capture (moving objects, lighting variations, shadows), artifacts appear as view-dependent effects or ‘floaters’. To cope with distractors, we advocate a form of robust estimation for NeRF training, modeling distractors in training data as outliers of an optimization problem. Our method successfully removes outliers from a scene and improves upon our baselines, on synthetic and real-world scenes. Our technique is simple to incorporate in modern NeRF frameworks, with few hyper-parameters. It does not assume a priori knowledge of the types of distractors, and is instead focused on the optimization problem rather than pre-processing or modeling transient objects. More results on our page https://robustnerf.github.io/public. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 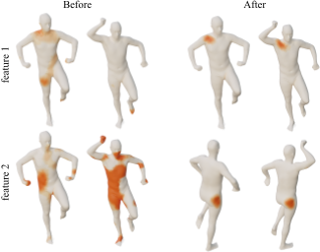
Deep functional maps have recently emerged as a successful paradigm for non-rigid 3D shape correspondence tasks. An essential step in this pipeline consists in learning feature functions that are used as constraints to solve for a functional map inside the network. However, the precise nature of the information learned and stored in these functions is not yet well understood. Specifically, a major question is whether these features can be used for any other objective, apart from their purely algebraic role, in solving for functional map matrices. In this paper, we show that under some mild conditions, the features learned within deep functional map approaches can be used as point-wise descriptors and thus are directly comparable across different shapes, even without the necessity of solving for a functional map at test time. Furthermore, informed by our analysis, we propose effective modifications to the standard deep functional map pipeline, which promotes structural properties of learned features, significantly improving the matching results. Finally, we demonstrate that previously unsuccessful attempts at using extrinsic architectures for deep functional map feature extraction can be remedied via simple architectural changes, which promote the theoretical properties suggested by our analysis. We thus bridge the gap between intrinsic and … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Current evaluations of Continual Learning (CL) methods typically assume that there is no constraint on training time and computation. This is an unrealistic assumption for any real-world setting, which motivates us to propose: a practical real-time evaluation of continual learning, in which the stream does not wait for the model to complete training before revealing the next data for predictions. To do this, we evaluate current CL methods with respect to their computational costs. We conduct extensive experiments on CLOC, a large-scale dataset containing 39 million time-stamped images with geolocation labels. We show that a simple baseline outperforms state-of-the-art CL methods under this evaluation, questioning the applicability of existing methods in realistic settings. In addition, we explore various CL components commonly used in the literature, including memory sampling strategies and regularization approaches. We find that all considered methods fail to be competitive against our simple baseline. This surprisingly suggests that the majority of existing CL literature is tailored to a specific class of streams that is not practical. We hope that the evaluation we provide will be the first step towards a paradigm shift to consider the computational cost in the development of online continual learning methods. |
|
Highlight
|
Video-Text As Game Players: Hierarchical Banzhaf Interaction for Cross-Modal Representation Learning
Poster
[ West Building Exhibit Halls ABC ] 
Contrastive learning-based video-language representation learning approaches, e.g., CLIP, have achieved outstanding performance, which pursue semantic interaction upon pre-defined video-text pairs. To clarify this coarse-grained global interaction and move a step further, we have to encounter challenging shell-breaking interactions for fine-grained cross-modal learning. In this paper, we creatively model video-text as game players with multivariate cooperative game theory to wisely handle the uncertainty during fine-grained semantic interaction with diverse granularity, flexible combination, and vague intensity. Concretely, we propose Hierarchical Banzhaf Interaction (HBI) to value possible correspondence between video frames and text words for sensitive and explainable cross-modal contrast. To efficiently realize the cooperative game of multiple video frames and multiple text words, the proposed method clusters the original video frames (text words) and computes the Banzhaf Interaction between the merged tokens. By stacking token merge modules, we achieve cooperative games at different semantic levels. Extensive experiments on commonly used text-video retrieval and video-question answering benchmarks with superior performances justify the efficacy of our HBI. More encouragingly, it can also serve as a visualization tool to promote the understanding of cross-modal interaction, which may have a far-reaching impact on the community. Project page is available at https://jpthu17.github.io/HBI/. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 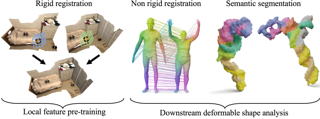
Transfer learning is fundamental for addressing problems in settings with little training data. While several transfer learning approaches have been proposed in 3D, unfortunately, these solutions typically operate on an entire 3D object or even scene-level and thus, as we show, fail to generalize to new classes, such as deformable organic shapes. In addition, there is currently a lack of understanding of what makes pre-trained features transferable across significantly different 3D shape categories. In this paper, we make a step toward addressing these challenges. First, we analyze the link between feature locality and transferability in tasks involving deformable 3D objects, while also comparing different backbones and losses for local feature pre-training. We observe that with proper training, learned features can be useful in such tasks, but, crucially, only with an appropriate choice of the receptive field size. We then propose a differentiable method for optimizing the receptive field within 3D transfer learning. Jointly, this leads to the first learnable features that can successfully generalize to unseen classes of 3D shapes such as humans and animals. Our extensive experiments show that this approach leads to state-of-the-art results on several downstream tasks such as segmentation, shape correspondence, and classification. Our code is … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Screen content images (SCIs) include many informative components, e.g., texts and graphics. Such content creates sharp edges or homogeneous areas, making a pixel distribution of SCI different from the natural image. Therefore, we need to properly handle the edges and textures to minimize information distortion of the contents when a display device’s resolution differs from SCIs. To achieve this goal, we propose an implicit neural representation using B-splines for screen content image super-resolution (SCI SR) with arbitrary scales. Our method extracts scaling, translating, and smoothing parameters of B-splines. The followed multi-layer perceptron (MLP) uses the estimated B-splines to recover high-resolution SCI. Our network outperforms both a transformer-based reconstruction and an implicit Fourier representation method in almost upscaling factor, thanks to the positive constraint and compact support of the B-spline basis. Moreover, our SR results are recognized as correct text letters with the highest confidence by a pre-trained scene text recognition network. Source code is available at https://github.com/ByeongHyunPak/btc. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Conventional methods for human motion synthesis have either been deterministic or have had to struggle with the trade-off between motion diversity vs~motion quality. In response to these limitations, we introduce MoFusion, i.e., a new denoising-diffusion-based framework for high-quality conditional human motion synthesis that can synthesise long, temporally plausible, and semantically accurate motions based on a range of conditioning contexts (such as music and text). We also present ways to introduce well-known kinematic losses for motion plausibility within the motion-diffusion framework through our scheduled weighting strategy. The learned latent space can be used for several interactive motion-editing applications like in-betweening, seed-conditioning, and text-based editing, thus, providing crucial abilities for virtual-character animation and robotics. Through comprehensive quantitative evaluations and a perceptual user study, we demonstrate the effectiveness of MoFusion compared to the state-of-the-art on established benchmarks in the literature. We urge the reader to watch our supplementary video. The source code will be released. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
Speech-driven gesture generation is highly challenging due to the random jitters of human motion. In addition, there is an inherent asynchronous relationship between human speech and gestures. To tackle these challenges, we introduce a novel quantization-based and phase-guided motion matching framework. Specifically, we first present a gesture VQ-VAE module to learn a codebook to summarize meaningful gesture units. With each code representing a unique gesture, random jittering problems are alleviated effectively. We then use Levenshtein distance to align diverse gestures with different speech. Levenshtein distance based on audio quantization as a similarity metric of corresponding speech of gestures helps match more appropriate gestures with speech, and solves the alignment problem of speech and gestures well. Moreover, we introduce phase to guide the optimal gesture matching based on the semantics of context or rhythm of audio. Phase guides when text-based or speech-based gestures should be performed to make the generated gestures more natural. Extensive experiments show that our method outperforms recent approaches on speech-driven gesture generation. Our code, database, pre-trained models and demos are available at https://github.com/YoungSeng/QPGesture. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
We present Tensor4D, an efficient yet effective approach to dynamic scene modeling. The key of our solution is an efficient 4D tensor decomposition method so that the dynamic scene can be directly represented as a 4D spatio-temporal tensor. To tackle the accompanying memory issue, we decompose the 4D tensor hierarchically by projecting it first into three time-aware volumes and then nine compact feature planes. In this way, spatial information over time can be simultaneously captured in a compact and memory-efficient manner. When applying Tensor4D for dynamic scene reconstruction and rendering, we further factorize the 4D fields to different scales in the sense that structural motions and dynamic detailed changes can be learned from coarse to fine. The effectiveness of our method is validated on both synthetic and real-world scenes. Extensive experiments show that our method is able to achieve high-quality dynamic reconstruction and rendering from sparse-view camera rigs or even a monocular camera. |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 
The combination of deep learning, artist-curated scans, and Implicit Functions (IF), is enabling the creation of detailed, clothed, 3D humans from images. However, existing methods are far from perfect. IF-based methods recover free-form geometry, but produce disembodied limbs or degenerate shapes for novel poses or clothes. To increase robustness for these cases, existing work uses an explicit parametric body model to constrain surface reconstruction, but this limits the recovery of free-form surfaces such as loose clothing that deviates from the body. What we want is a method that combines the best properties of implicit representation and explicit body regularization. To this end, we make two key observations: (1) current networks are better at inferring detailed 2D maps than full-3D surfaces, and (2) a parametric model can be seen as a “canvas” for stitching together detailed surface patches. Based on these, our method, ECON, has three main steps: (1) It infers detailed 2D normal maps for the front and back side of a clothed person. (2) From these, it recovers 2.5D front and back surfaces, called d-BiNI, that are equally detailed, yet incomplete, and registers these w.r.t. each other with the help of a SMPL-X body mesh recovered from the image. … |
|
Highlight
|
Poster
[ West Building Exhibit Halls ABC ] 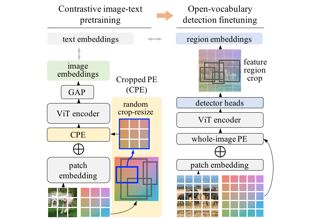
We present Region-aware Open-vocabulary Vision Transformers (RO-ViT) -- a contrastive image-text pretraining recipe to bridge the gap between image-level pretraining and open-vocabulary object detection. At the pretraining phase, we propose to randomly crop and resize regions of positional embeddings instead of using the whole image positional embeddings. This better matches the use of positional embeddings at region-level in the detection finetuning phase. In addition, we replace the common softmax cross entropy loss in contrastive learning with focal loss to better learn the informative yet difficult examples. Finally, we leverage recent advances in novel object proposals to improve open-vocabulary detection finetuning. We evaluate our full model on the LVIS and COCO open-vocabulary detection benchmarks and zero-shot transfer. RO-ViT achieves a state-of-the-art 32.1 APr on LVIS, surpassing the best existing approach by +5.8 points in addition to competitive zero-shot transfer detection. Surprisingly, RO-ViT improves the image-level representation as well and achieves the state of the art on 9 out of 12 metrics on COCO and Flickr image-text retrieval benchmarks, outperforming competitive approaches with larger models. |