Poster
Being Comes From Not-Being: Open-Vocabulary Text-to-Motion Generation With Wordless Training
Junfan Lin · Jianlong Chang · Lingbo Liu · Guanbin Li · Liang Lin · Qi Tian · Chang-Wen Chen
West Building Exhibit Halls ABC 250

{kind=link}
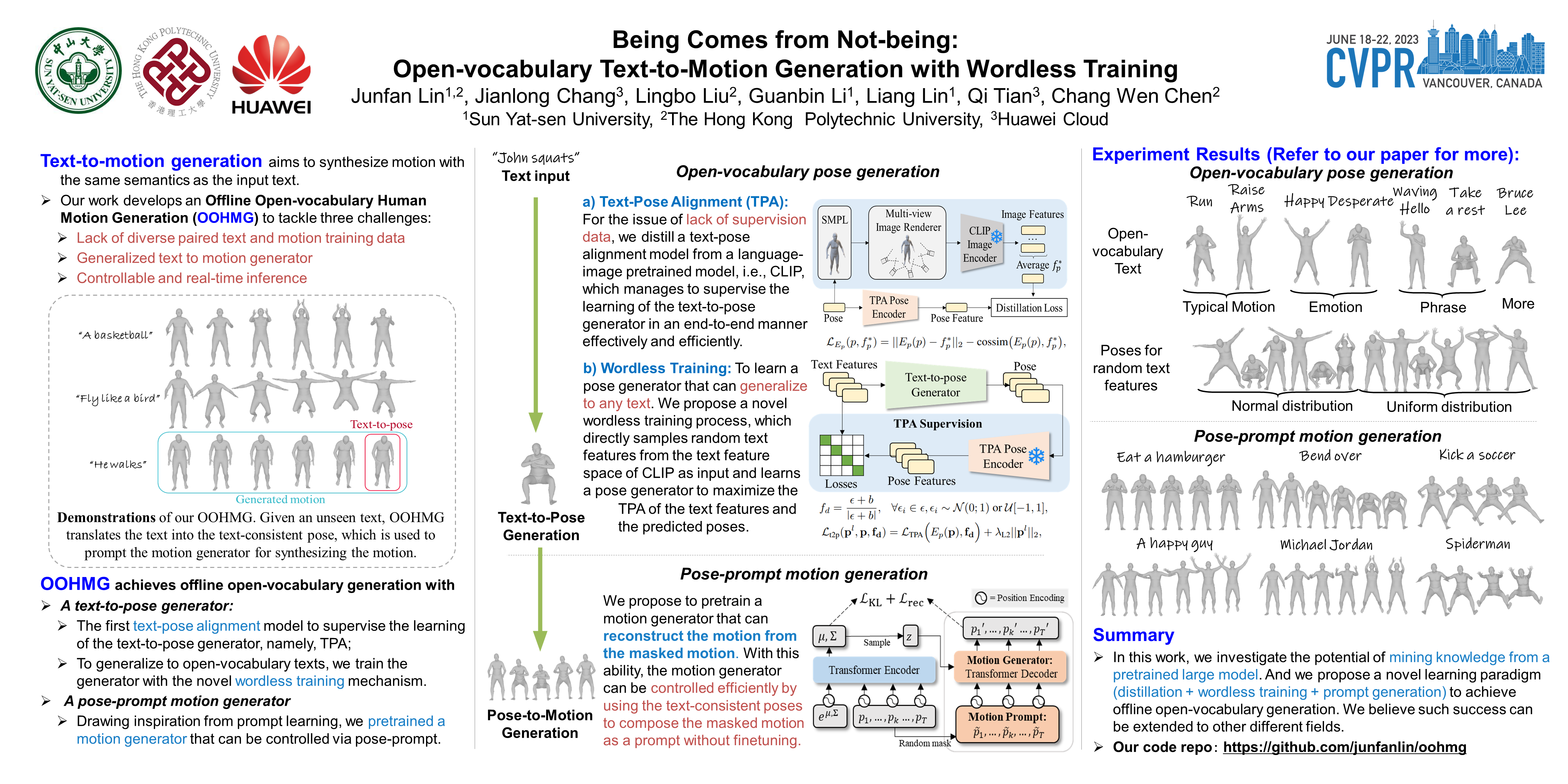
Text-to-motion generation is an emerging and challenging problem, which aims to synthesize motion with the same semantics as the input text. However, due to the lack of diverse labeled training data, most approaches either limit to specific types of text annotations or require online optimizations to cater to the texts during inference at the cost of efficiency and stability. In this paper, we investigate offline open-vocabulary text-to-motion generation in a zero-shot learning manner that neither requires paired training data nor extra online optimization to adapt for unseen texts. Inspired by the prompt learning in NLP, we pretrain a motion generator that learns to reconstruct the full motion from the masked motion. During inference, instead of changing the motion generator, our method reformulates the input text into a masked motion as the prompt for the motion generator to “reconstruct” the motion. In constructing the prompt, the unmasked poses of the prompt are synthesized by a text-to-pose generator. To supervise the optimization of the text-to-pose generator, we propose the first text-pose alignment model for measuring the alignment between texts and 3D poses. And to prevent the pose generator from overfitting to limited training texts, we further propose a novel wordless training mechanism that optimizes the text-to-pose generator without any training texts. The comprehensive experimental results show that our method obtains a significant improvement against the baseline methods. The code is available at https://github.com/junfanlin/oohmg.