{kind=link}
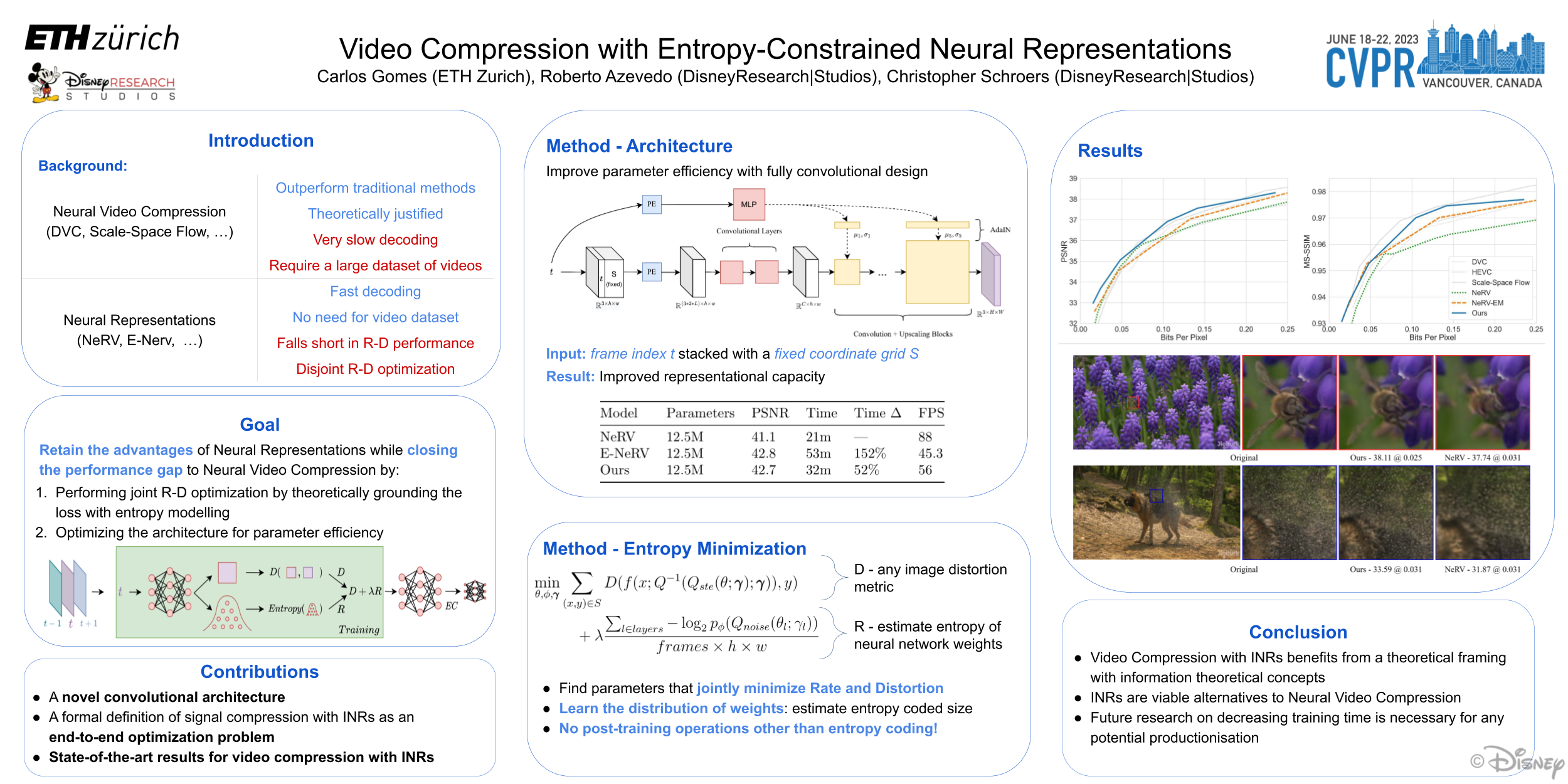
Encoding videos as neural networks is a recently proposed approach that allows new forms of video processing. However, traditional techniques still outperform such neural video representation (NVR) methods for the task of video compression. This performance gap can be explained by the fact that current NVR methods: i) use architectures that do not efficiently obtain a compact representation of temporal and spatial information; and ii) minimize rate and distortion disjointly (first overfitting a network on a video and then using heuristic techniques such as post-training quantization or weight pruning to compress the model). We propose a novel convolutional architecture for video representation that better represents spatio-temporal information and a training strategy capable of jointly optimizing rate and distortion. All network and quantization parameters are jointly learned end-to-end, and the post-training operations used in previous works are unnecessary. We evaluate our method on the UVG dataset, achieving new state-of-the-art results for video compression with NVRs. Moreover, we deliver the first NVR-based video compression method that improves over the typically adopted HEVC benchmark (x265, disabled b-frames, “medium” preset), closing the gap to autoencoder-based video compression techniques.