{kind=link}
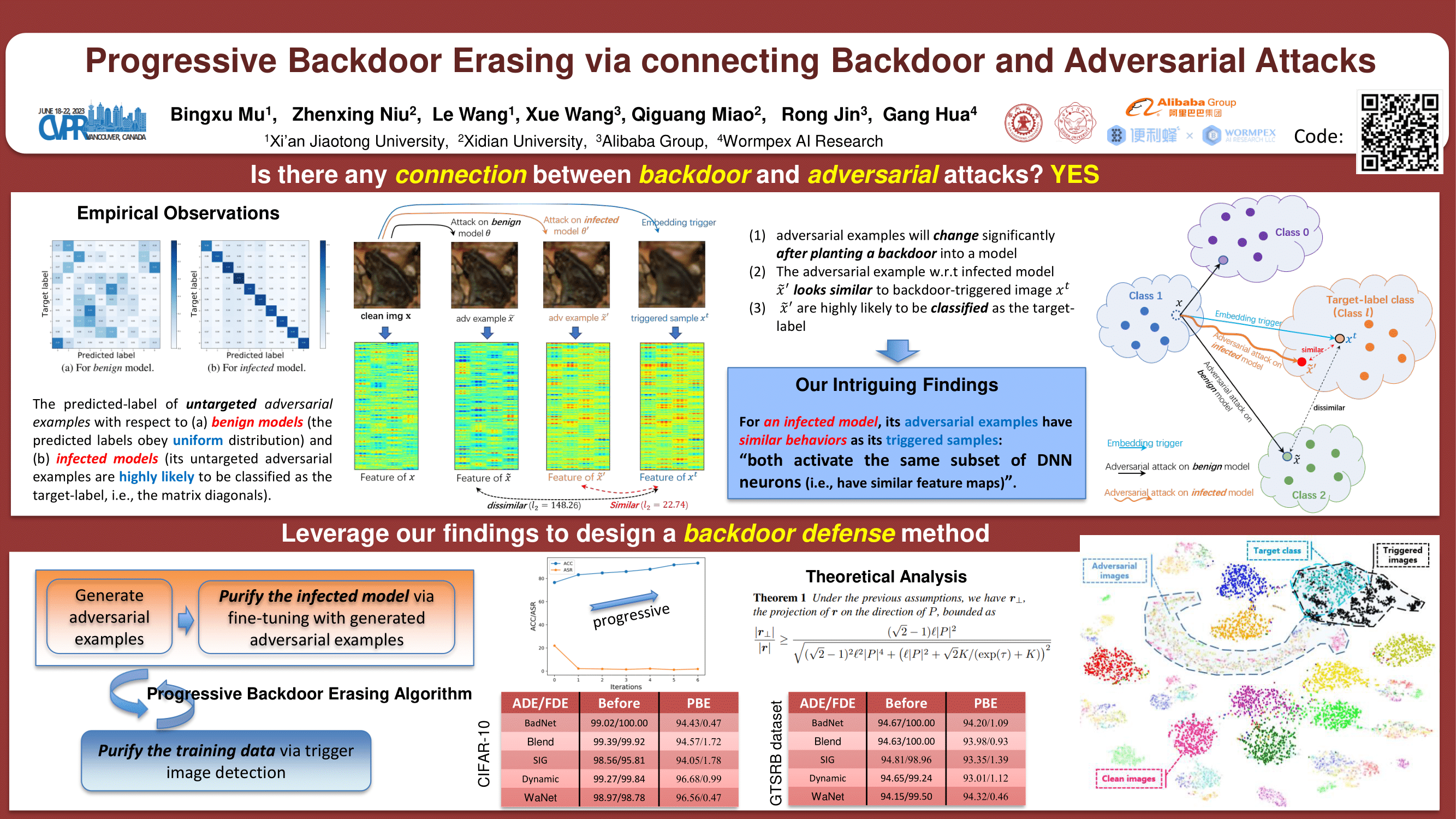
Deep neural networks (DNNs) are known to be vulnerable to both backdoor attacks as well as adversarial attacks. In the literature, these two types of attacks are commonly treated as distinct problems and solved separately, since they belong to training-time and inference-time attacks respectively. However, in this paper we find an intriguing connection between them: for a model planted with backdoors, we observe that its adversarial examples have similar behaviors as its triggered samples, i.e., both activate the same subset of DNN neurons. It indicates that planting a backdoor into a model will significantly affect the model’s adversarial examples. Based on this observations, a novel Progressive Backdoor Erasing (PBE) algorithm is proposed to progressively purify the infected model by leveraging untargeted adversarial attacks. Different from previous backdoor defense methods, one significant advantage of our approach is that it can erase backdoor even when the additional clean dataset is unavailable. We empirically show that, against 5 state-of-the-art backdoor attacks, our AFT can effectively erase the backdoor triggers without obvious performance degradation on clean samples and significantly outperforms existing defense methods.