Poster
Fusing Pre-Trained Language Models With Multimodal Prompts Through Reinforcement Learning
Youngjae Yu · Jiwan Chung · Heeseung Yun · Jack Hessel · Jae Sung Park · Ximing Lu · Rowan Zellers · Prithviraj Ammanabrolu · Ronan Le Bras · Gunhee Kim · Yejin Choi
West Building Exhibit Halls ABC 249
{kind=link}
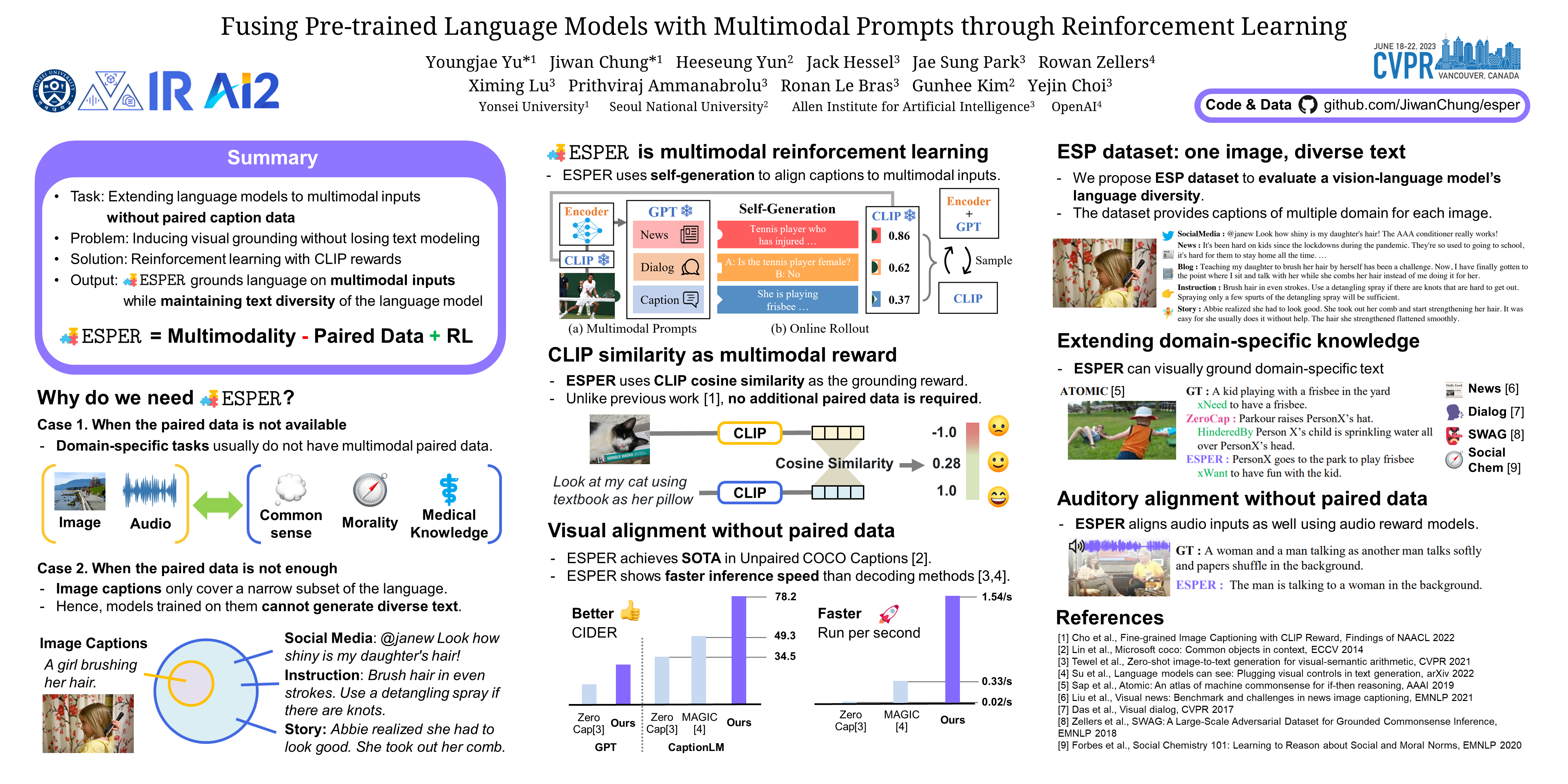
Language models are capable of commonsense reasoning: while domain-specific models can learn from explicit knowledge (e.g. commonsense graphs [6], ethical norms [25]), and larger models like GPT-3 manifest broad commonsense reasoning capacity. Can their knowledge be extended to multimodal inputs such as images and audio without paired domain data? In this work, we propose ESPER (Extending Sensory PErception with Reinforcement learning) which enables text-only pretrained models to address multimodal tasks such as visual commonsense reasoning. Our key novelty is to use reinforcement learning to align multimodal inputs to language model generations without direct supervision: for example, our reward optimization relies only on cosine similarity derived from CLIP and requires no additional paired (image, text) data. Experiments demonstrate that ESPER outperforms baselines and prior work on a variety of multimodal text generation tasks ranging from captioning to commonsense reasoning; these include a new benchmark we collect and release, the ESP dataset, which tasks models with generating the text of several different domains for each image. Our code and data are publicly released at https://github.com/JiwanChung/esper.