{kind=link}
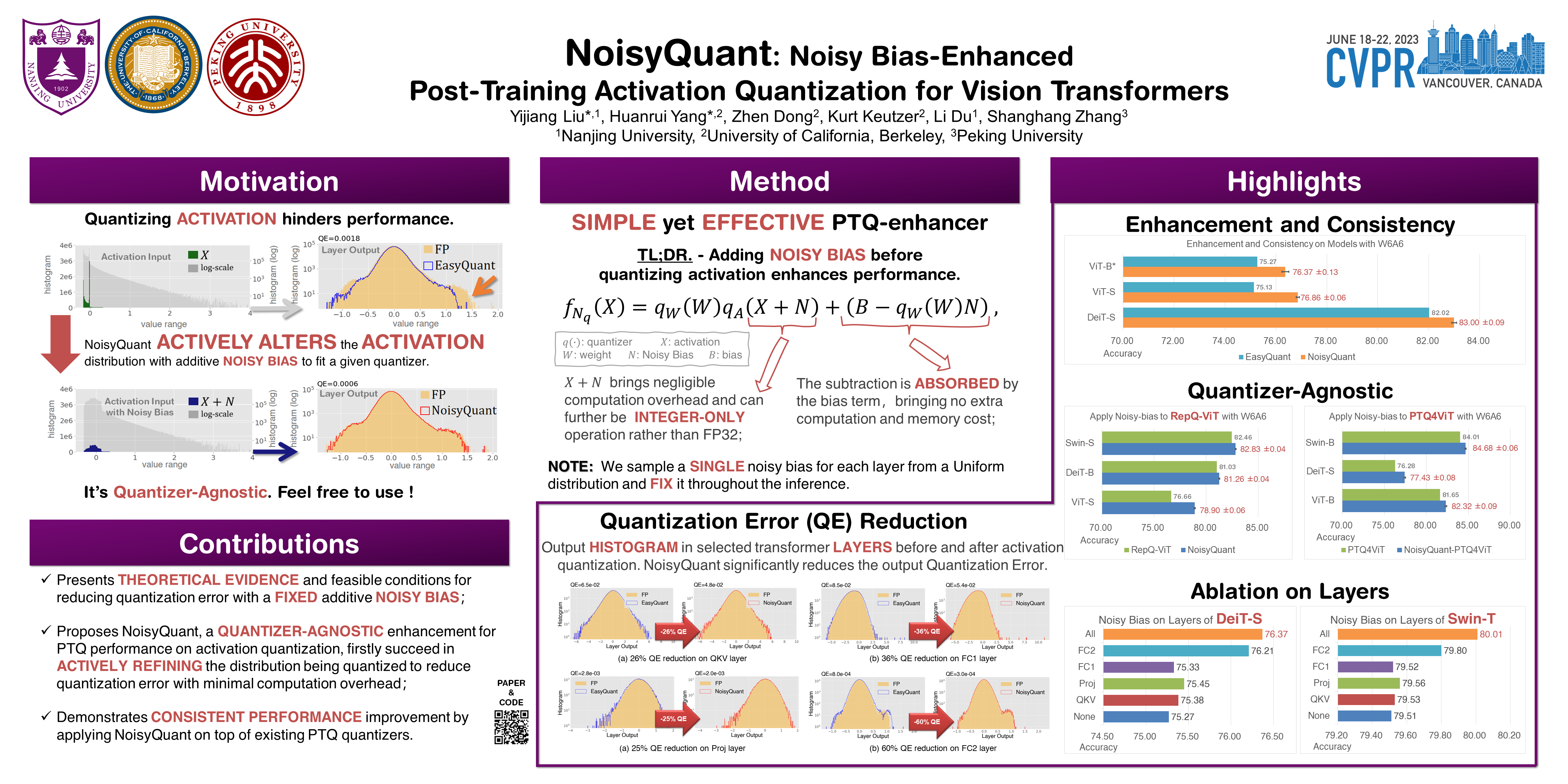
The complicated architecture and high training cost of vision transformers urge the exploration of post-training quantization. However, the heavy-tailed distribution of vision transformer activations hinders the effectiveness of previous post-training quantization methods, even with advanced quantizer designs. Instead of tuning the quantizer to better fit the complicated activation distribution, this paper proposes NoisyQuant, a quantizer-agnostic enhancement for the post-training activation quantization performance of vision transformers. We make a surprising theoretical discovery that for a given quantizer, adding a fixed Uniform noisy bias to the values being quantized can significantly reduce the quantization error under provable conditions. Building on the theoretical insight, NoisyQuant achieves the first success on actively altering the heavy-tailed activation distribution with additive noisy bias to fit a given quantizer. Extensive experiments show NoisyQuant largely improves the post-training quantization performance of vision transformer with minimal computation overhead. For instance, on linear uniform 6-bit activation quantization, NoisyQuant improves SOTA top-1 accuracy on ImageNet by up to 1.7%, 1.1% and 0.5% for ViT, DeiT, and Swin Transformer respectively, achieving on-par or even higher performance than previous nonlinear, mixed-precision quantization.