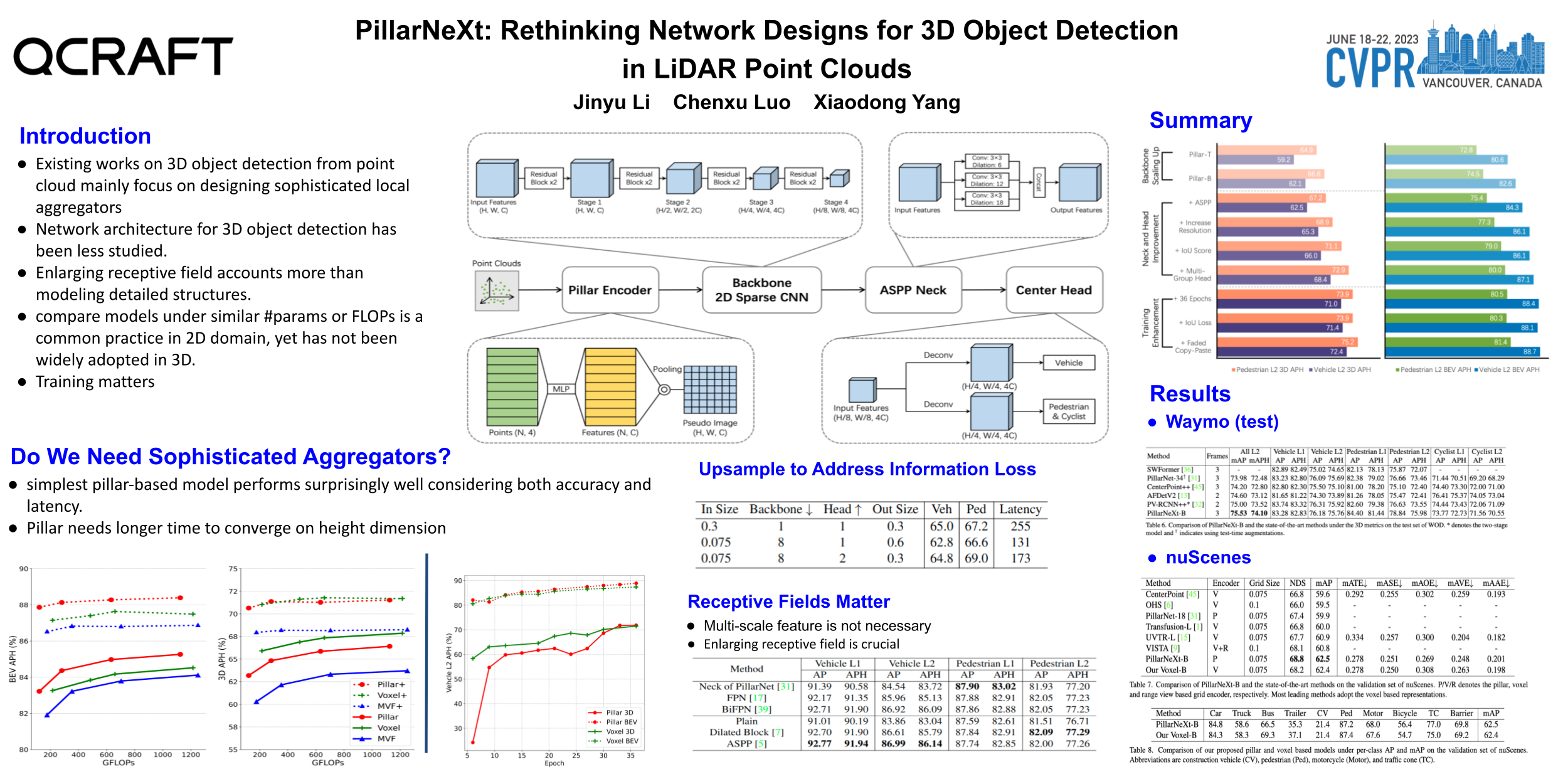
{kind=link}
In order to deal with the sparse and unstructured raw point clouds, most LiDAR based 3D object detection research focuses on designing dedicated local point aggregators for fine-grained geometrical modeling. In this paper, we revisit the local point aggregators from the perspective of allocating computational resources. We find that the simplest pillar based models perform surprisingly well considering both accuracy and latency. Additionally, we show that minimal adaptions from the success of 2D object detection, such as enlarging receptive field, significantly boost the performance. Extensive experiments reveal that our pillar based networks with modernized designs in terms of architecture and training render the state-of-the-art performance on two popular benchmarks: Waymo Open Dataset and nuScenes. Our results challenge the common intuition that detailed geometry modeling is essential to achieve high performance for 3D object detection.