{kind=link}
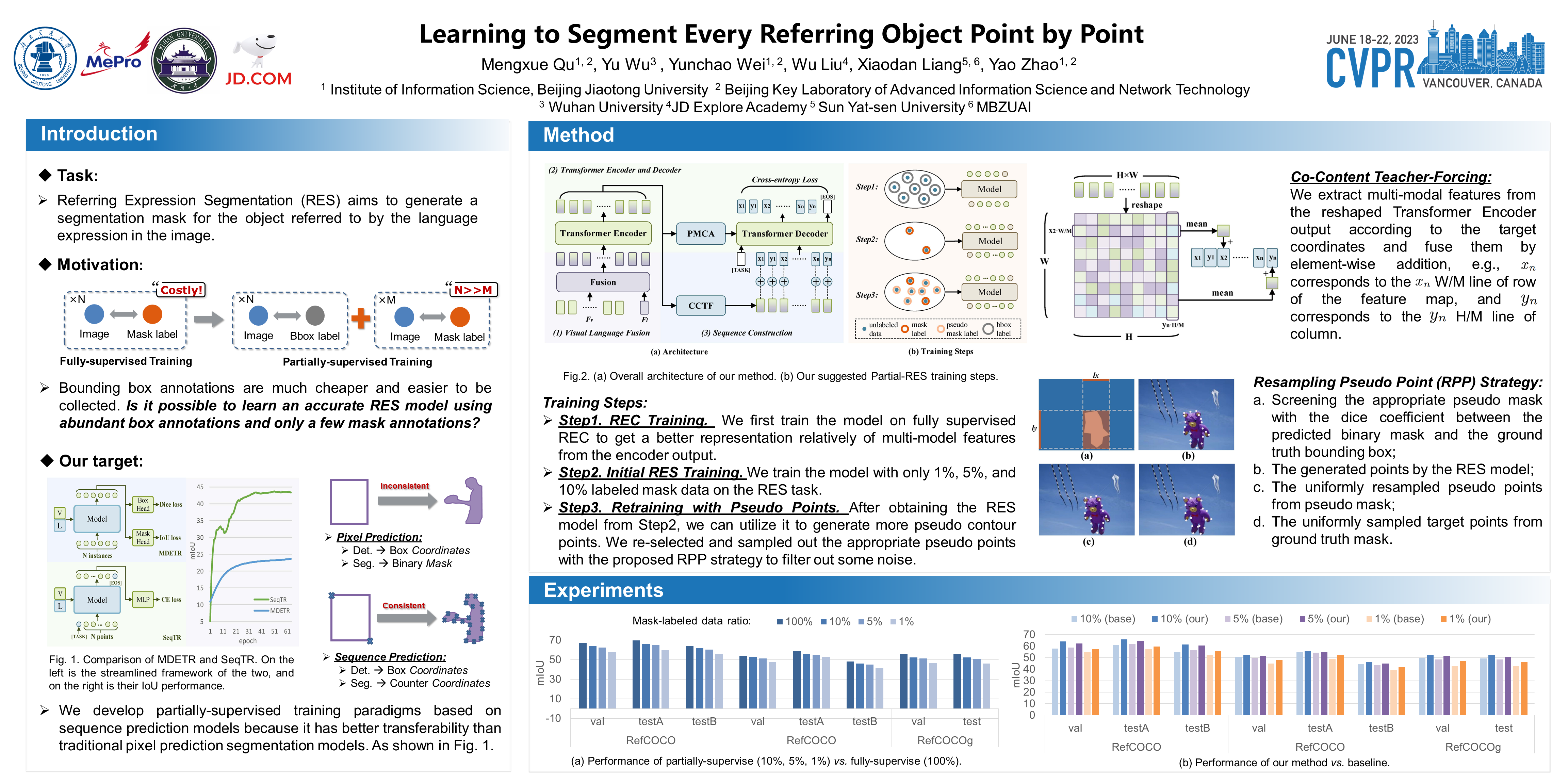
Referring Expression Segmentation (RES) can facilitate pixel-level semantic alignment between vision and language. Most of the existing RES approaches require massive pixel-level annotations, which are expensive and exhaustive. In this paper, we propose a new partially supervised training paradigm for RES, i.e., training using abundant referring bounding boxes and only a few (e.g., 1%) pixel-level referring masks. To maximize the transferability from the REC model, we construct our model based on the point-based sequence prediction model. We propose the co-content teacher-forcing to make the model explicitly associate the point coordinates (scale values) with the referred spatial features, which alleviates the exposure bias caused by the limited segmentation masks. To make the most of referring bounding box annotations, we further propose the resampling pseudo points strategy to select more accurate pseudo-points as supervision. Extensive experiments show that our model achieves 52.06% in terms of accuracy (versus 58.93% in fully supervised setting) on RefCOCO+@testA, when only using 1% of the mask annotations.