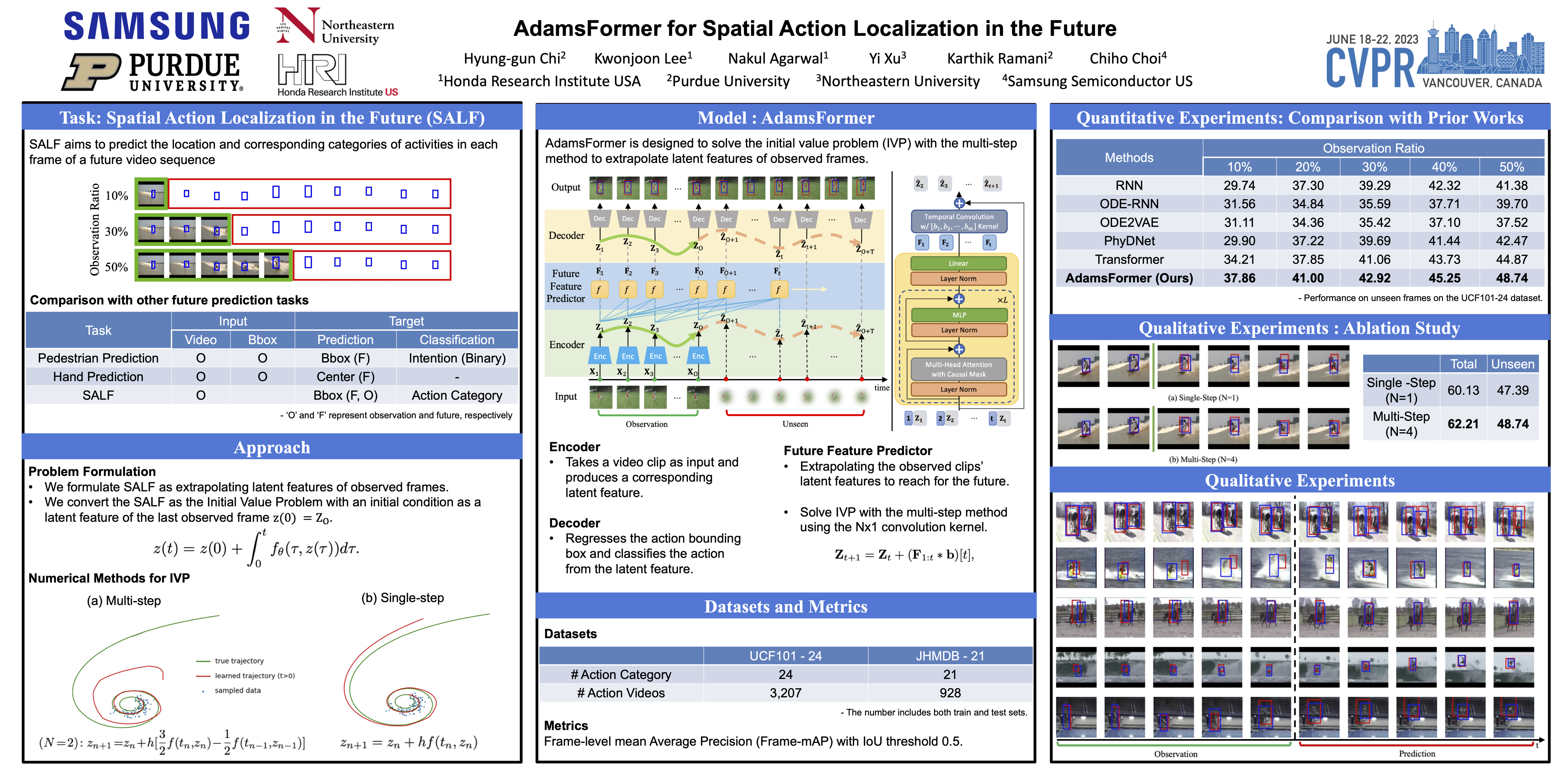
{kind=link}
Predicting future action locations is vital for applications like human-robot collaboration. While some computer vision tasks have made progress in predicting human actions, accurately localizing these actions in future frames remains an area with room for improvement. We introduce a new task called spatial action localization in the future (SALF), which aims to predict action locations in both observed and future frames. SALF is challenging because it requires understanding the underlying physics of video observations to predict future action locations accurately. To address SALF, we use the concept of NeuralODE, which models the latent dynamics of sequential data by solving ordinary differential equations (ODE) with neural networks. We propose a novel architecture, AdamsFormer, which extends observed frame features to future time horizons by modeling continuous temporal dynamics through ODE solving. Specifically, we employ the Adams method, a multi-step approach that efficiently uses information from previous steps without discarding it. Our extensive experiments on UCF101-24 and JHMDB-21 datasets demonstrate that our proposed model outperforms existing long-range temporal modeling methods by a significant margin in terms of frame-mAP.