{kind=link}
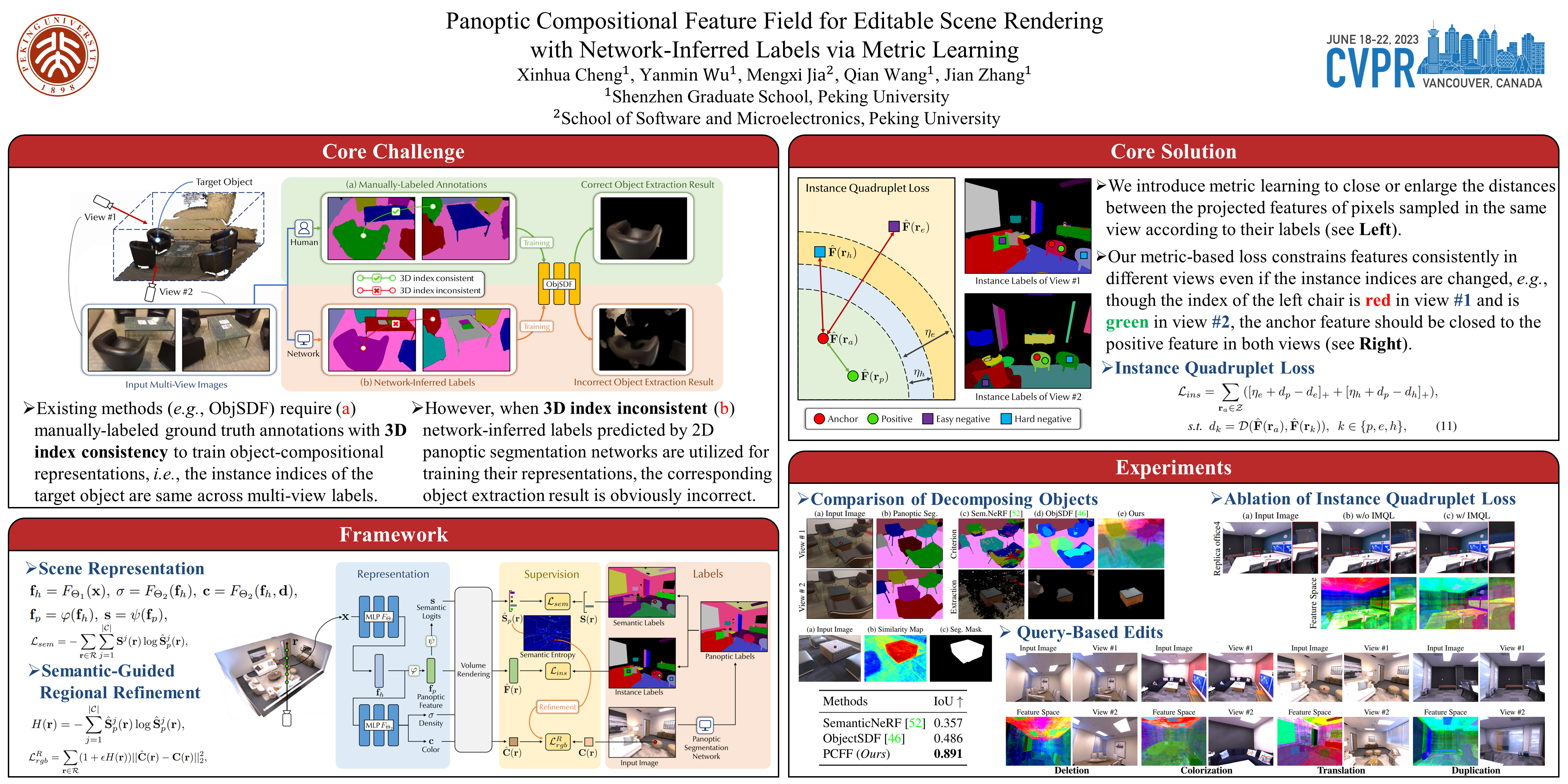
Despite neural implicit representations demonstrating impressive high-quality view synthesis capacity, decomposing such representations into objects for instance-level editing is still challenging. Recent works learn object-compositional representations supervised by ground truth instance annotations and produce promising scene editing results. However, ground truth annotations are manually labeled and expensive in practice, which limits their usage in real-world scenes. In this work, we attempt to learn an object-compositional neural implicit representation for editable scene rendering by leveraging labels inferred from the off-the-shelf 2D panoptic segmentation networks instead of the ground truth annotations. We propose a novel framework named Panoptic Compositional Feature Field (PCFF), which introduces an instance quadruplet metric learning to build a discriminating panoptic feature space for reliable scene editing. In addition, we propose semantic-related strategies to further exploit the correlations between semantic and appearance attributes for achieving better rendering results. Experiments on multiple scene datasets including ScanNet, Replica, and ToyDesk demonstrate that our proposed method achieves superior performance for novel view synthesis and produces convincing real-world scene editing results. The code will be available.